《百度春招》专题
-
春靴
我想在我的Junit5单元测试中将值注入到带有@Value注释的私有字段。 我引用了这个,并使用了ReflectionTestUtils。setField通过注入值解决了我的问题,但在验证方法被调用的次数时失败。 MyClass(我的类别): 测试类: 运行上述测试时出错 我想kafkaTemplate.sendMessage();被调用一次,但被调用两次后添加反射TestUtils。 需要关于如
-
春假
我想把硒和Spring一起使用。 如果我在没有Spring的情况下使用Selenium,一切正常。每当我添加Spring依赖项(没有Spring代码)时,执行时会引发以下异常: 线程“main”java中出现异常。lang.NoClassDefFoundError:org/openqa/selenium/MutableCapabilities at java。lang.ClassLoader。在j
-
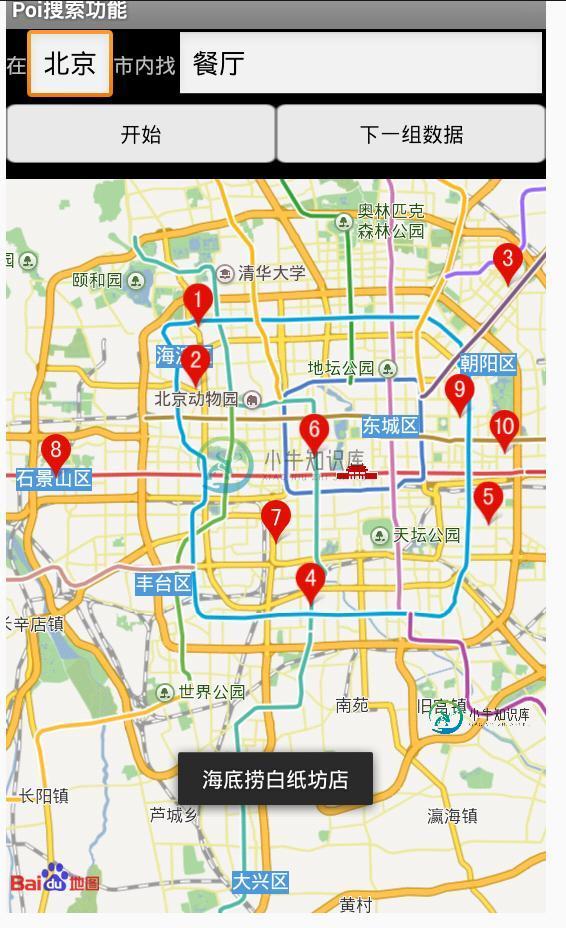 Android百度地图poi范围搜索
Android百度地图poi范围搜索本文向大家介绍Android百度地图poi范围搜索,包括了Android百度地图poi范围搜索的使用技巧和注意事项,需要的朋友参考一下 我想大家可能都有过这样的经历:兜里揣着一张银行卡,在街上到处找自动取款机(ATM)。在这个场景中,ATM就是的兴趣点,我们想做的事情就是找到离自己较近的一些ATM然后取款,此时我们并不关心附近有哪些超市、酒吧,因为这些地方没办法取钱! 说了这么多,一方面是加深大家
-
 ThinkPHP整合百度Ueditor图文教程
ThinkPHP整合百度Ueditor图文教程本文向大家介绍ThinkPHP整合百度Ueditor图文教程,包括了ThinkPHP整合百度Ueditor图文教程的使用技巧和注意事项,需要的朋友参考一下 ThinkPHP整合百度Ueditor,基于黄永成老师的视频说明的 申明:最好大家都能写绝对路径的都写好绝对路径比如:window.UEDITOR_HOME_URL 他在教程里面已经说了的,我就不再次说了啊,就一笔带过,好了不废话! 在调用编辑
-
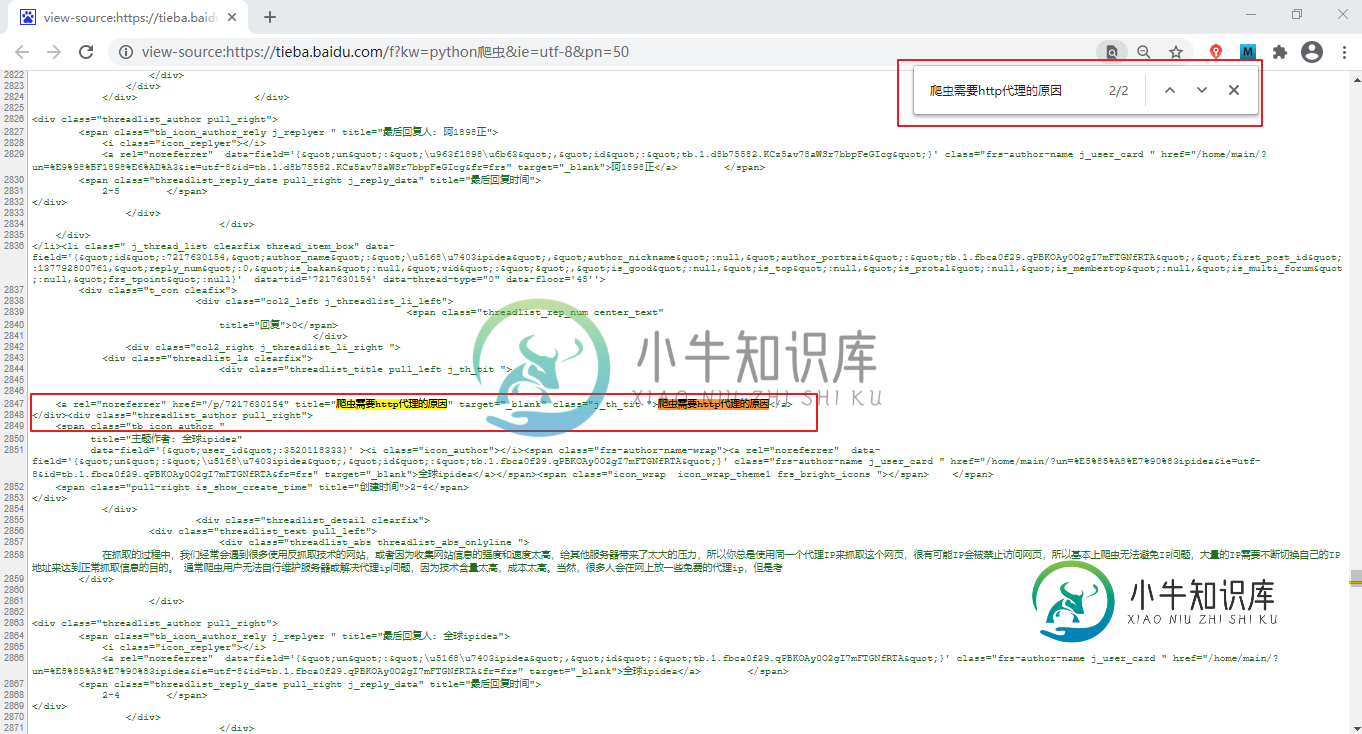 [实例]抓取百度贴吧数据
[实例]抓取百度贴吧数据主要内容:判断页面类型,寻找URL变化规律,编写爬虫程序,爬虫程序结构,爬虫程序随机休眠本节继续讲解 Python 爬虫实战案例:抓取百度贴吧( https://tieba.baidu.com/)页面,比如 Python爬虫吧、编程吧,只抓取贴吧的前 5 个页面即可。本节我们将使用面向对象的编程方法来编写程序。 判断页面类型 通过简单的分析可以得知,待抓取的百度贴吧页面属于静态网页,分析方法非常简单:打开百度贴吧,搜索“Python爬虫”,在出现的页面中复制任意一段信息,比如“爬虫需
-
 3.13百度后端笔试编程题
3.13百度后端笔试编程题第一题 给定一个字符串,问是否可以排列为:Baidu 第二题 给定数字p,构造s使得s的子字符串为回文串的数目为p。(p<1e9,s.size() < 1e5); 第三题 给定一棵树,每个节点有蓝色和红色两种颜色,问:删除其中一条边,剩下两个联通块的色块的个数的差值,求所有差值的和;(n<2e5) 代码为回忆版本,非现场通过版本#我的实习求职记录#
-
 百度研发c++机考 3.13(A卷)
百度研发c++机考 3.13(A卷)编程题1:编程3*15 共45分 给定N个字符串,判断其是否能够重新排列出"Baidu"字符串(注意大小写必须完全相同),能重构出 返回YES,不能则返回No; 例1: 输入 BAaidu baidu 输出 Yes No 编程题2: 给定一个整数X(1~1e9),请你构造一个仅有'r&(31189)#39;,'e','d&(30340)#39;三种字符组成的字符串,其中回文字符子串的数量恰好为X(
-
 百度3.13后端笔试第二道
百度3.13后端笔试第二道r,e,d三个字符,能否构成含有 cnt 个回文串的字符串 s 原理:n个相同的字符构建的回文子串的个数为n(n+1)/2,其余的用edr补 ``` public static void deal1() { Scanner sc = new Scanner(System.in); int x = sc.nextInt(); int n = (int) (Math.sqrt(2*x + 0.25)
-
 【百度】3.18 C++暑期实习 一面
【百度】3.18 C++暑期实习 一面本硕211,算法转开发。简历项目比赛都是算法相关,本科中厂开发实习。 面试官很年轻,像是刚毕业工作。全程35min左右,快问快答,比较基础。 算法项目没问,本科开发实习有点久远没问。问了为什么研究生没开发实习经历。 八股 操作系统 线程进程的区别 死锁的四个条件 介绍下协程 进程/线程的通信方式 共享内存的具体实现 计算机网络 OSI 七层模型+每层的作用+协议 三次握手 四次挥手 http状态码
-
 百度C++后端一二三面20230319
百度C++后端一二三面20230319约了下午13点的,结果还要取号排队,可见并不严格按照时间 一面 1小时 自我介绍 DNS解析过程 网络包的组包拆包过程,包头里有什么 HTTPS原理 Raft过程 multi-Raft实现 项目的性能怎么样?最难的是什么? 编程题:反转链表 二面 40分钟 自我介绍 LSM-Tree的结构 Raft优化 TiDB的架构 Raft具体实现(比如etcd)有哪些值得借鉴的 Raft和其他共识协议相比的
-
 百度前端暑期实习笔试
百度前端暑期实习笔试参加的还是24前端暑期实习笔试。笔试有3部分,15道单选,5道多选,3道编程题。难度适中,选择大部分为前端内容,包括html5、js、css。均为前端基本功,也有计算机基础内容,但是较少。大概3:1吧个人感觉。选择题分数比较重,一题3分。 第一部分:大多为前端,包括HTML5,css[]选择器,数据结构,js看程序读结果等。部分题目还是没遇到过,整体做下来难度不大。 第二部分:多选题,少选得1/3
-
 3.13百度23前端实习笔试
3.13百度23前端实习笔试前两部分单选和不定项,包含计算机基础知识与前端基础知识代码分析题。好多都不太会做。 算法题部分,第一道较简单忘记了。 第二道题两个map,一个map统计数的个数,在遍历计算累加和的过程中,另一个map记录左端点,查询遍历到的右端点是否有符合条件的左端。 第三道题,前边连续d后边red,类似这样dddddddredre。
-
 百度提前批前端一二面
百度提前批前端一二面一面 8.12 聊项目 文件上传,切片,唯一性验证 webworker webpack(我不会) 项目聊得比较多,八股没怎么问(或者是我忘了) 【手写】括号匹配 二面 8.19 vue响应式、diff 对react理解哪些 webpack(好的我不会) 讲讲项目,做了什么,难题 长列表优化(不太懂要问啥) 作用域 闭包,缺点,用处 https 浏览器渲染 渲染进程的多线程(合成...) 浏览器内
-
 百度地图/滴滴测开一面
百度地图/滴滴测开一面百度:(已经忘了一些了,只记得答得不太好的) 1.测试一个自助售卖机 2.awk的用法和参数 滴滴: 1.测试一个促销活动页面,两种促销活动2选1,要注意安全性 2.python的装饰器 3.http请求状态码(今天另一个公司又问了请求方法) 百度ACG(jd写了需要资深测试工程师,我这个工作一年的小菜狗也不知道简历是怎么过的筛) 1.Linux:查找某目录下所有.log结尾的文件,并筛选出文件中
-
 百度测开日常实习一面
百度测开日常实习一面面试官人挺不错 上来先聊简历 自我介绍 聊项目 八股 python的浅拷贝和深拷贝 python的垃圾回收机制(没答上来) http和https的区别 进程和线程区别 http的状态码(没答上来) tcp和udp的应用场景 算法:手撕快速排序(只会原理,没撕出来) 发个面经攒攒人品