《同花顺2023春招交流讨论》专题
-
 2023秋招—数据开发面经—蚂蚁金融
2023秋招—数据开发面经—蚂蚁金融一面:电话面试 1、自我介绍 2、挑一个实习项目讲一讲 3、项目里的数据是怎么处理的? 4、数据研发选择哪一块?(数据仓库、数据平台、数据算法、数据挖掘) 5、讲讲MapReduce的原理 6、环形缓冲区为什么要反向? 7、实习的存储计算用的是什么组件 8、有金融相关知识的储备吗? 反问: 1、这一面算是第一面吗(是)?算专业面吗(是)? 2、做什么工作的?(国外金融银行业务) 3、用到哪些技术栈
-
 2023秋招—数据开发面经—联友科技
2023秋招—数据开发面经—联友科技面试岗位:数据库工程师 两个面试官,一个主要问知识点,另一个主要问实习、项目 介绍一下HDFS的写流程 Spark、Flink有哪些部署模式? Standlone和Yarn(Client、Cluster),会话模式、单作业模式、应用模式 有没有写过Flink平台的开发代码? Yarn由哪些角色组成?各自的任务是什么? Yarn的调度器有哪些? Hive和HBase的区别是什么? 项目中Kafka的
-
 2023秋招—数据开发面经—卓望数码
2023秋招—数据开发面经—卓望数码分享前吐槽:面试不开摄像头,面试官的语气跟快断气了一样…… 1、有了解web开发、后端开发吗?(无) 2、线程和进程有哪些区别? 3、怎么看一个正在执行的JAVA程序的线程状态? 4、新生代和老年代主要是干什么的?比例是多少? 5、HDFS的服务组成有哪些?它们分别的作用是什么? 6、除了Hive之外,还用过其他数仓吗? 7、Flink的窗口主要是干什么的? 8、Flink的dataStream和
-
 百度2023秋招研发A卷(10月11日)
百度2023秋招研发A卷(10月11日)第一题 暴力即可,注意需要判断字符串长度是否为5 第二题 map存 数字 -> 出现次数 滑动窗口,限制窗口内元素总和不大于k,等于k则为一个答案 注意有元素出窗口时不能只-1,需要减去该元素出现次数。 第三题 数字末尾零的个数 = min(数字2的因子个数,数字5的因子个数) 树链剖分,对子树的更新和查询转化为链上的连续节点操作。 转化为一个维护带懒更新的线段树。 最后三分钟调出来,发现quer
-
 【2023校招】沐瞳(战斗游戏测试)面经
【2023校招】沐瞳(战斗游戏测试)面经一面: 1.游戏开发过程,你觉得有哪些需要进行测试的地方; 2.王者荣耀小乔大招的音效你觉得有哪些需要测试的地方 3.手撕两道基础算法 二面: 1.一个英雄技能修改了,你觉得有哪些地方需要测试 2.安琪拉大招你觉得有哪些测试点 3.如果让你带领一个1000人的团队,你如何进行管理能够让员工效率提高 4.如何留住员工,你有哪些办法 5.手撕代码:判断三条边能否构成三角形 HR面: 1.为什么选择游戏
-
 2023秋招-腾讯-数据科学-四面(HR面)
2023秋招-腾讯-数据科学-四面(HR面)公司:腾讯 部门:腾讯广告 岗位:技术研究-数据科学方向 形式:视频面试 视频面试平台:腾讯会议 时长:14分钟 流程: 1、自我介绍。 2、你对于选择第一份工作的考虑有哪些? 3、腾讯对于你的吸引力是什么? 4、放到一年后你希望你在工作上获得什么样的成果? 5、过往经历中你遇到的最困
-
 2023秋招 | 地平线视觉算法工程师
2023秋招 | 地平线视觉算法工程师岗位 视觉算法工程师 一面 针对项目进行提问,问的比较细,要对每一点说出为什么 深度学习算法相比于传统算法在去噪上有什么优势 了解傅里叶变换吗,蝶形计算快在哪里 了解量化吗 BN有什么用,为什么可以加速训练 label smooth为什么可以提高精度 介绍一下深度可分离卷积,深度可分离卷积和普通卷积的计算量对比 代码:应用题,二分查找的应用 #2023校招##计算机视觉算法工程师#
-
 2023届算法秋招&实习总结-华为&TME
2023届算法秋招&实习总结-华为&TME先说说最近热度比较高的华子。 华为实习oc拒,秋招三面完没消息。 #实习一面 介绍论文。 -假设和假设空间的定义 -结构风险最小化和奥卡姆剃刀 -决策树 --节点分裂是熵增还是熵减,原因 -梯度消失和爆炸原因 -梯度的定义,模长方向表示什么 -手撕lc原题:幂集 #实习二面&三面 -二面三面就很水了,纯聊天 #秋招一面、二面、三面 囊括在一起写,因为确实没什么好写的。 随便问问论文,手撕一道原题。
-
火花流未阅读所有Kafka记录
我们从kafka向SparkStreaming发送了15张唱片,但是spark只收到了11张唱片。我用的是spark 2.1.0和kafka_2.12-0.10.2.0。 密码 bin/Kafka-console-producer . sh-broker-list localhost:9092-topic input data topic # 1 2 3 4 5 6 7 8 9 10 11 12
-
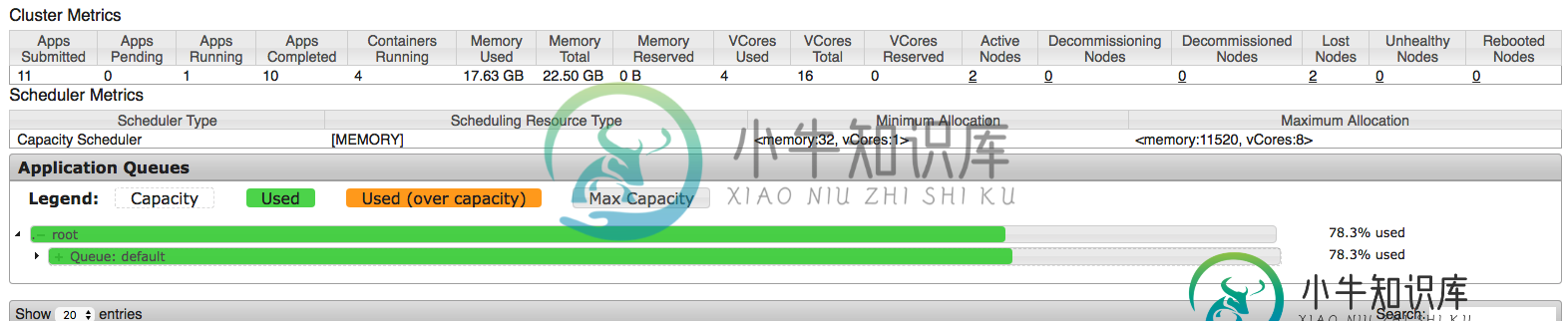 带纱线的火花流应用配置
带纱线的火花流应用配置在配置spark应用程序时,我试图从集群中挤出每一点,但似乎我并没有完全正确地理解每一件事。因此,我正在AWS EMR集群上运行该应用程序,该集群具有1个主节点和2个m3类型的核心节点。xlarge(每个节点15G ram和4个vCPU)。这意味着,默认情况下,每个节点上为纱线调度的应用程序保留11.25 GB。因此,主节点仅由资源管理器(纱线)使用,这意味着剩余的2个核心节点将用于调度应用程序(
-
批之间的流数据共享火花
Spark streaming以微批量处理数据。 使用RDD并行处理每个间隔数据,每个间隔之间没有任何数据共享。 但我的用例需要在间隔之间共享数据。 > 单词“hadoop”和“spark”与前一个间隔计数的相对计数 所有其他单词的正常字数。 注意:UpdateStateByKey执行有状态处理,但这将对每个记录而不是特定记录应用函数。 间隔-1 输入: 输出: 火花发生3次,但输出应为2(3-1
-
用于火花流的Kafka主题分区
我有一些关于Kafka主题分区->spark流媒体资源利用的用例,我想更清楚地说明这些用例。 我使用spark独立模式,所以我只有“执行者总数”和“执行者内存”的设置。据我所知并根据文档,将并行性引入Spark streaming的方法是使用分区的Kafka主题->RDD将具有与Kafka相同数量的分区,当我使用spark-kafka直接流集成时。 因此,如果我在主题中有一个分区和一个执行器核心,
-
火花流中的状态函数问题
我尝试使用Spark Streaming并希望有一个全局状态对象,可以在每个批处理后更新。据我所知,至少有两种选择适合我:1。使用,其中Spark将在处理每个批处理后自动更新状态2。使用函数,在这里我必须自己调用更新 类型javapairdStream 中的方法updateStateByKey(Function2 ,optional ,optional >)不适用于参数(new function2
-
带有火花流集成错误的kafka
我不能用火花流运行Kafka。以下是我迄今为止采取的步骤: > 将此行添加到- Kafka版本:kafka_2.10-0.10.2.2 Jar文件版本:spark-streaming-kafka-0-8-assembly_2.10-2.2.0。罐子 Python代码: 但我仍然得到以下错误: 我做错了什么?
-
火花流句柄 倾斜的Kafka分区
场景: Kafka- 每个火花流微批次中的逻辑(30秒):< br >读取Json- 我的流媒体工作是阅读大约1000个Kafka主题,大约有10K个Kafkapartitions,吞吐量大约为500万事件/秒。 问题来自 Kafka 分区之间的流量负载不均匀,一些分区的吞吐量大约是较小分区的 50 倍,这会导致 RDD 分区倾斜(因为 KafkaUtils 创建了从 Kafka 分区到 Spar