《面试题刺客退退退》专题
-
 数据分析面试题与解析3
数据分析面试题与解析3面试高频题21: 题目:一家实体零售企业发现本月销售额同比下降30%,如何来分析销售额同比下滑的原因呢? 答案解析: 业务模型初步分析: 实体零售一般是以全国-大区-小区-单店的管理模型进行运营。 逻辑拆解: ①内外部大环境判断: 外部环境(PEST): 政策:如国家出台有关政策。 经济:如市场经济环境影响,竞品的影响。 社会:如社会上产生不利于舆论。 科技:如新技术出现并没有促进消费,反而产生不
-
 行业看法面试题与解析1
行业看法面试题与解析1面试高频题1: 题目:谈谈对短视频行业的理解 答案解析: 首先,该行业中长期来看会往哪个方向走: 短期和长期该行业都有着蓬勃向上的发展趋势,市场规模非常庞大,18年增长率超过了700%,虽然现在增长率放缓,但规模仍在增长。 其次,识别出这个行业的关键风险和成功的驱动因素: 内容生产者的质量,人们碎片化的时间等(本质上是内容行业,需要靠内容吸引用户) 最后,这个行业成功的企业和失败的企业大概都有哪些
-
 商业模式-面试题与解析1
商业模式-面试题与解析1面试高频题1: 题目:抖音的盈利模式 答案解析: 1. B2B 收入 抖音利用网红和品牌合作的伙伴关系盈利 2. 品牌滤镜 在抖音上,用户可以给短视频添加滤镜。一些品牌可能会为用户添加专属滤镜,让用户把品牌添加到他们的视频里面。然后,他们可能会请网红主播用这个滤镜拍摄短视频,其他用户看到之后就会跟着使用。一些品牌方可能会造势和滤镜搭配宣传。 在抖音上,用户可以创建音频并上传到平台供其他人使用。这个
-
 数据模型面试题与解析1
数据模型面试题与解析1面试高频题1: 题目:介绍一下k-means,你的数据如何处理,模型的输出是什么? 答案解析: 介绍kmeans: 第一步:数据归一化、离群点处理后,随机选择k个聚类质心 第二步:所有数据点关联划分到离自己最近的质心,形成k个簇; 第三步:重新计算每个簇的质心; 重复第二步、第三步,直到簇不发生变化或达到最大迭代次数; 数据如何处理: 为了防止均值和方差大的维度将对数据的聚类产生决定性影响,所以在
-
 机器学习面试题与解析1
机器学习面试题与解析1面试高频题1: 题目:了解决策树吗 答案解析: 决策树是一种机器学习的方法。决策树的生成算法有ID3, C4.5和C5.0等。决策树是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果。 决策树的构造过程: 决策树的构造过程一般分为3个部分,分别是特征选择、决策树生产和决策树裁剪。 (1)特征选择: 特征选择表示从众多的特征中选择一个
-
 机器学习面试题与解析2
机器学习面试题与解析2面试高频题11: 题目:L1、L2的原理?两者区别? 答案解析: 原理: L1正则是基于L1范数和项,即参数的绝对值和参数的积项;L2正则是基于L2范数,即在目标函数后面加上参数的平方和与参数的积项。 区别: 1.鲁棒性:L1对异常点不敏感,L2对异常点有放大效果。 2.稳定性:对于新数据的调整,L1变动很大,L2整体变动不大。 答案解析 数据分析只需要简单知道原理和区别就行,公式推导不需要,面试
-
 数据处理面试题与解析1
数据处理面试题与解析1面试高频题1: 题目:处理噪声数据方法 答案解析: 1、分箱 分箱方法是一种简单常用的预处理方法,通过考察相邻数据来确定最终值。所谓“分箱”,实际上就是按照属性值划分的子区间,如果一个属性值处于某个子区间范围内,就称把该属性值放进这个子区间所代表的“箱子”内。把待处理的数据(某列属性值)按照一定的规则放进一些箱子中,考察每一个箱子中的数据,采用某种方法分别对各个箱子中的数据进行处理。在采用分箱技术
-
 产品求职面试题:数据分析
产品求职面试题:数据分析GMV上周跌了20%,你会怎么分析 这是一道场景题,如果完全没有准备,很可能答不到点上 这类数据波动分析的题目,也称之为异动分析题,今天就给你好好讲讲怎么回答 回答,一共分为3步 第一步,确认异常 先分析数据是不是有误,上周是不是个数据高峰,所以显得这周数据下跌了... 第二步,拆解归因 确认了异常之后,下一步就是分析异常的原因,这也是异动分析的关键步骤。通常有2种方法 1.指标拆解:指标之间如果
-
人力资源面试问题(HR Interview Questions)
面试是两个或两个以上的人之间的对话,面试官要求他们提出问题,以便从受访者那里获得事实或陈述。 这是一个有用的教程,收集一组最有用的人力资源面试问题以及如何以机智的方式回答这些问题。 听众 (Audience) 本教程主要面向希望了解在面试中取得成功的基本步骤的年轻人和求职者。 先决条件 (Prerequisites) 在继续学习本教程之前,您应该愿意与我们联系,提出问题并解决有关该主题的任何进一步
-
C 编程面试问题(C Programming Interview Questions)
亲爱的读者,这些C Programming Interview Questions专门设计用于让您熟悉在C Programming主题面试中可能遇到的问题的本质。 根据我的经验,很好的面试官在你的面试中几乎不打算问任何特定的问题,通常问题从这个主题的一些基本概念开始,然后他们继续基于进一步的讨论和你回答的问题 - 指针上的指针是什么? 它是一个指针变量,可以保存另一个指针变量的地址。 它取消引用两
-
 最新整理的 Elasticsearch 21道面试题
最新整理的 Elasticsearch 21道面试题******************************* 1、为什么要使用 Elasticsearch? 系统中的数据, 随着业务的发展, 时间的推移, 将会非常多,而业务中往往采用模糊查询进行数据的 搜索,而模糊查询会导致查询引擎放弃索引, 导致系统查询数据时都是全表扫描,在百万级别的数据库中, 查询效率是非常低下的,而我们使用 ES 做一个全文索引, 将经常查询的系统功能的某些字段,比如
-
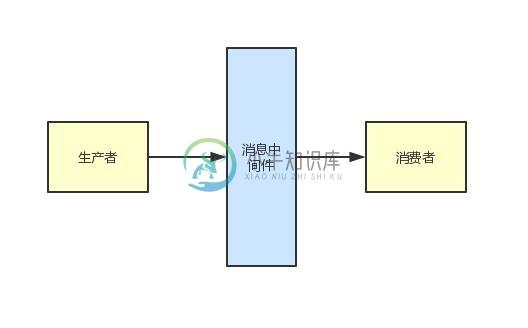 面试官喜欢问什么样的题?
面试官喜欢问什么样的题?主要内容:1、面试官为啥要出这样一个开放式问题,2、生产消费模型以及核心数据结构,3、支撑TB级数据写入的分布式架构,4、数据宕机场景下的高可用架构,5、支持数据不丢失的ack机制,6、最后的总结1、面试官为啥要出这样一个开放式问题 这篇文章简单给大家来聊一个互联网大厂的Java面试题:如果让你设计一个消息中间件,你会怎么做? 其实这个问题之前大致给大家聊过,本质就是面试官在考察一个高级以上的Java工程师的系统设计能力。 给你一个平时大家都常用的一个消息中间件作为命题,让你现场开放式发挥,立马
-
 精心整理的Redis【25道】面试题
精心整理的Redis【25道】面试题主要内容:1.什么是 redis?它能做什么?,2.redis 有哪八种数据类型?有哪些应用场景?,3.redis为什么这么快?,4.听说 redis 6.0之后又使用了多线程,不会有线程安全的问题吗?,5.redis 的持久化机制有哪些?优缺点说说,6. Redis的过期键的删除策略有哪些?缓存如何过期的/如何删除过期key的?,7. Redis的内存满了怎么办?如何淘汰的,8.Redis 的热 key 问题怎么解决?,,,,,,,,,,,,,,,,,因为数据库是架构的瓶颈:所以加入redis
-
大数据数仓高级面试题 3
主要内容:1.建模锯齿,2.数据粒度的锯齿操作,3.下游表依赖上游表问题,4.数仓数据域划分方式,5.数仓一致性是如何保证的,6.数仓优化,7.数据全生命周期,8.数仓建模问题,9.数仓建模过程1.建模锯齿 建模锯齿是指在建模过程中的一种常见的效应,其中模型的输出可能会产生锯齿状的波动。这种效应通常是由于模型的不稳定性或过度拟合导致的。 在建模过程中,锯齿可能会使模型的表现变差,并且在预测新数据时也可能出现不一致的结果。因此,在建模时需要注意避免出现锯齿状的波动。 一种常用的方法是使用正则化来限
-
大数据数仓高级面试题 1
主要内容:1.数仓高内聚低耦合,2.多重粒度,3.如何提高查询效率,4.数仓数据域划分几种方式,5.粒度操作,6.SQL实现,7.数仓中ODS层命中多少为合理,8.数仓价值链的体现和实现,9.建立数仓的步骤,10.指标生命周期的评估,11.数据治理,12.数仓的目的1.数仓高内聚低耦合 一般复杂的公共逻辑可以采用抽象类和抽象方法的方式下沉到共有模块中,然后由相关子类去实现抽象方法,来实现不同的功能。这样可以将复杂的逻辑拆分成各个子类,使得类之间的耦合度降低,提高代码的可维护性。 2.多重粒度 在