《分奖金》专题
-
Spark重新分区创建的分区超过128 MB
假设我有一个1.2 GB的文件,那么考虑到128 MB的块大小,它将创建10个分区。现在,如果我将其重新分区(或合并)为4个分区,这意味着每个分区肯定会超过128 MB。在这种情况下,每个分区必须容纳320 MB的数据,但块大小是128 MB。我有点糊涂了。这怎么可能?我们如何创建一个大于块大小的分区?
-
数据框架-连接/分组依据-聚集-分区
我可能对加入/组By-agg有一个天真的问题。在RDD的日子里,每当我想执行a. groupBy-agg时,我曾经说reduceByKey(PairRDDFunctions)带有可选的分区策略(带有分区数或分区程序)b.join(PairRDDFunctions)及其变体,我曾经有一种方法可以提供分区数量 在DataFrame中,如何指定此操作期间的分区数?我可以在事后使用repartition(
-
Itext:使用条形码分隔符拆分pdf文档
我面临以下用例: 我收到一个包含许多文档的pdf。每个文档具有不同的页数。它们由条形码页分隔。 是否可以拆分包含多个文档的多页PDF,这些文档由带有条形码的页面分隔,并为每个文档创建一个新的PDF? 我听说我们可以用Itext:https://developers.itextpdf.com/examples/stamping-content-existing-pdfs/clone-splittin
-
Apache Camel拆分器不能正确拆分xml文件
我只有一个具有大xml文件最后顺序的文件,而不是许多小xml文件。你能告诉我出了什么问题吗?太感谢你们了!
-
带多个点分组分隔符的格式编号
我需要验证显示的字符串是否为数字。值的格式为123.345.678,99。即分组分隔符是点,小数分隔符是逗号。 我尝试了设置分隔符的DecimalFormatter: 有什么想法吗? 我想我也可以使用regexp,但如果可能的话,我想首先使用这个。
-
Spring Boot“瘦肥罐”-将罐分成两部分(app/libs)
我想把我的应用程序分成2个胖罐(模块/库)。 我已经检查了“Spring Boot瘦jar项目”,它加载依赖项并在第一次运行时缓存它们,但我不能让它与多个本地模块一起工作。 不过...我还是想让我的第一种方法奏效。有什么想法吗? Gradle 6.9.1(7.x不适用于薄罐) Spring靴2.6。十、
-
我可以结合功能分组来划分流吗?
我分组和分区流如下: 有没有办法把这两者结合起来?我尝试将两者结合使用,并在PartionBy中使用groupingBy,但没有成功。有什么建议吗? 预期的结果是将这些人与以P开头的人分开,并按年龄分组。以下是人员名单:
-
致命:当前分支主控没有上游分支
然后我试了一下: 有什么提示吗?
-
StringTokenizer类--使用分隔符作为标记分隔符
如果使用带有单个参数的第一个StringToknenizer构造函数并编写示例程序,结果是和12个令牌。它返回没有任何空格的整个句子。我明白这是怎么回事。 如果使用带有两个参数的第二个构造函数,我的测试程序将得到每个单词有空格,但没有逗号,只有两个标记。我认为它应该同时将空格和逗号作为标记分隔符计算,但它将逗号之前的所有内容作为1标记计算,将逗号之后的所有内容作为1标记计算。这部分让我很困惑。 我
-
字典区分大小写和不区分大小写
我需要一个像
-
 牧原统计分析岗面试经验分享(上)
牧原统计分析岗面试经验分享(上)我也来分享一下我的面试,内容有点长。 正值毕业季嘛,我就在招聘网站进行了海投,因为实习是做的统计,就投递了京津冀牧原(虽然是上市公司,但我压根不知道这个公司是干嘛的,也没听说过)。 先说下面试时间吧,人事那边添加我的微信,正好也快周六日,周六日她是没空搭理你的,所以要选在工作日联系最好(着急的话),她会提前一天通知面试而且会发你网址,里面有宣讲会和相关影片,都是官网的(会问问题的,认真看看)。 我
-
 爱回收(业务数据分析师)面经分享
爱回收(业务数据分析师)面经分享1月3号下午HR在BOSS直聘与我联系,沟通好以后约定1月5号下午2点面试。 一共3轮面试,一个下午流程全部走完,整个面试经过如下: 1.一面(HR初试): 耗时30分钟左右,主要针对简历上的过往经历详细做了沟通了解,也问了期望薪资等问题 2.二面(部门leader面): 耗时1个小时多,是一位年轻的美女面试官,针对简历上的过往工作经历和项目经历进行了深挖,问了不少细节,很专业。 问了以后的职业发
-
分库分表规则原理及自定义配置
背景 业务在使用分表分表时多数会使用简单的hash分表或者按照时间或者id使用内置的range分表函数,但某些情况下这些简单的hash规则和内置函数并不能满足业务复制的分表场景,这时就需要业务自定义分库分表规则。而zebra的分库分表规则使用的是groovy脚本,理论上可以支持定制各种复杂的路由规则。 基本原理 首先,先看一个简单的分库分表规则(使用本地配置时的XML),后面会基于该例子解释zeb
-
词法分析器和语法分析器的界线
因为词法规则可以使用递归,所以词法解析器在技术上和语法解析器一样强大。那意味着我们甚至可以在词法分析器中匹配语法结构。或者,在另一个极端,我们可以把字符当作记号,使用语法分析器去把语法结构应用到字符流(这种被称为无扫描语法分析器)。这导致什么在词法分析器中匹配和什么在语法分析器中匹配的界线在哪里并不是很明显。幸运的是,有几条经验法则可以让我们做出判断: 在词法分析器中匹配和丢弃任何语法分析器根本不
-
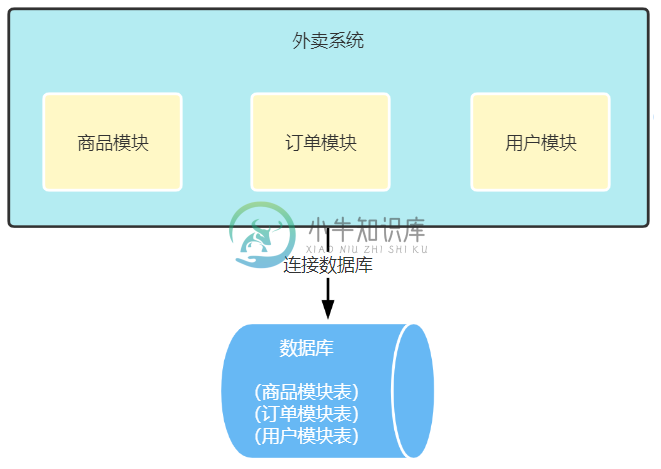 分库分表让系统性能提升上百倍
分库分表让系统性能提升上百倍主要内容:前 言,新的挑战,怎么做垂直拆分?,垂直拆分有哪些好处呢?,垂直拆分有什么不足的地方吗?前 言 读写分离方案上线后,订单sql查询时间再一次稳定在了300ms以下,此时对数据的增删改操作会走主库,而读请求会走从库,通过读写分离大大提升了数据读的处理能力,但遗憾的是没办法提升主库写数据的能力。 新的挑战 那么什么时候主库写数据的压力会过大呢?其实我们之前也聊过这个问题,那就是多个业务共用一个物理数据库的,比如商品相关的表、订单相关的表和用户相关的表等,所有表都放到了一个mysql数据库