《分奖金》专题
-
ApacheFlink和Kinesis分析:java。lang.IllegalArgumentException:要分配的内存部分不应为0
背景:我一直试图在部署在运动分析运行时的同一个flink应用程序中设置BATCH STREAMING。流部分工作正常,但我有麻烦添加支持BATCH。 Flink:处理数据早于应用程序水印的密钥流 Apache Flink:数据流API的批处理模式失败,但“非法状态异常:排序输入不允许检查点”除外。' 逻辑是这样的: 这样做,我得到了以下例外: 似乎运动分析不允许客户端定义flink-conf.ya
-
使用特殊的分隔线将文本文件拆分为部分-python
问题内容: 我有这样的输入文件: 所需的任务是按由特殊行分隔的部分读取文件,在这种情况下,该行为空行,例如[out]: 通过这样做,我一直在获得所需的输出: 但是,如果特殊行是以例如以下开头的行: 我必须这样做: 如果我允许拥有分隔符参数,则可以尝试以下操作: 但是有没有办法我不对所有可能的分隔符进行硬编码? 问题答案: 传递谓词怎么样? 用法:
-
Python csv:按分隔符将列拆分为列,然后再拆分为行
我在csv文件中有一个列,其中包含此格式的人员详细信息: 实际csv格式: 我想将它们拆分为一个新的csv文件,如下所示: 拆分详细信息: 拆分行分隔符:
-
将RDD划分为每个分区中元素数量固定的分区
在Apache Spark中, -允许将RDD精确划分为分区。 而是如何将给定的RDD划分成分区,使得所有分区(最后一个分区除外)都具有指定数量的元素。鉴于RDD元素的数量是未知的,做<代码>。count()的开销很大。 预期:
-
分层ldd(1)
问题内容: 由于使用了Gentoo,经常发生这样的情况,即在更新程序链接到旧版本的库之后。通常,revdep- rebuild有助于解决该问题,但是这一次它依赖于python库,因此不会使用。 是否有“分层”变体向我显示哪个共享库取决于另一个共享库?大多数时候,库和可执行文件仅与少数几个其他共享库链接,而这些共享库又与少数几个共享库链接,从而使库依赖性成为一个大列表。我想知道我必须使用升级的另一个
-
PHP / MySQL分页
问题内容: 我是php和sql的新手,我对如何实现sql query有一个小问题,它可以: 以数据库中的5个条目为例,将其插入第一页(1-5) 比从同一个数据库中提取下5个条目并将它们插入另一页(5-10) ,依此类推:) 谢谢 ) 问题答案: 阅读MySQL SELECT帮助页面上 的LIMIT部分。如果要显示可用的总行数,则可以进行额外的计数或使用ROW_COUNT函数。
-
实时划分
问题内容: 我正在尝试用Java编写一个小程序,将华氏温度转换为摄氏温度。它涉及减去32并乘以5/9。所以我做到了。 但是由于某种原因5/9返回零,这甚至毁了一切 返回零,我不知道为什么。我发现自己可以做到的唯一方法是声明所有内容并逐步进行。 谁能告诉我为什么发生这种情况,我认为至少将其声明为double会返回值。如果有人知道,那就可以解决。 问题答案: 默认情况下,Java中的数字是。因此,当您
-
Hibernate-HQL分页
问题内容: 我正在尝试使用HQL实现分页。我有一个PostgreSQL数据库。 发生的情况是,Hibernate提取所有消息,并在所有消息加载后返回所需的消息。 因此,Hibernate获取210000个实体,而不是返回的30个实体(每个Messages都有2个命令)。 有没有一种方法可以将开销减少7000倍? 编辑:我尝试添加 。它没有帮助。 编辑2:生成的SQL查询是: 绝对没有LIMIT或O
-
xml CDATA部分
本文向大家介绍xml CDATA部分,包括了xml CDATA部分的使用技巧和注意事项,需要的朋友参考一下 示例 包含特殊字符的文本的较长部分可以使用CDATA节进行转义。CDATA节只能出现在元素内容中。 CDATA节不能包含序列,]]>因为它结束了它。
-
 Angular ui.bootstrap.pagination分页
Angular ui.bootstrap.pagination分页本文向大家介绍Angular ui.bootstrap.pagination分页,包括了Angular ui.bootstrap.pagination分页的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了Angular 分页的具体代码,供大家参考,具体内容如下 1、Html 2、Action 效果图: 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
Swift tableView分页
问题内容: 我可以使用json解析代码成功工作tableview。但是可能还有1000多个项目,因此在滚动底部时需要分页。我不知道如何在下面执行我的代码。对于Objective-C,有很多例子,但是为了迅速,我没有找到有效的例子。我在等你的帮助。我认为会帮助太多人。谢谢 ! 问题答案: 为此,您还需要更改服务器端。 服务器将接受并在url中作为查询参数。 在服务器响应中,将有一个额外的密钥。这将用
-
Wordpress分类法
我快要哭了! 我已经做了很多谷歌搜索,但是我不能让这段代码按照我想要的方式工作。 在Wordpress中,我有以下分类法: https://dl.dropboxusercontent.com/u/30177707/wo-tax.png 我想要的是孩子被显示为特定的职位,如果没有孩子,我想只显示父母。 这是我编辑过的截图,所以它能更好地描述我的问题。https://dl.dropboxusercon
-
Oracle分页sql
#不带排序的 SELECT * FROM ( SELECT ROWNUM AS rowno, t.* FROM worker t where ROWNUM <=20) table_alias WHERE table_alias.rowno > 10; #带排序的 SELECT * FROM ( SELECT tt.*, ROWNUM AS rowno FROM ( SELECT t.* FR
-
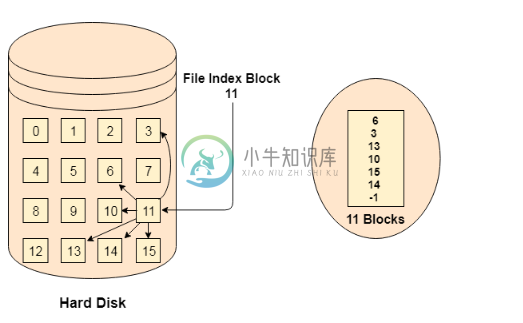 索引分配
索引分配主要内容:FAT的限制,索引分配方案FAT的限制 现有技术的局限性导致新技术的发展。 到目前为止,我们已经看到了各种分配方法; 他们都有几个优点和缺点。 文件分配表尽量解决尽可能多的问题,但会导致一个缺点。 块的数量越多,FAT的大小就越大。 因此,我们需要为文件分配表分配更多空间。 由于文件分配表需要被缓存,因此不可能在缓存中具有尽可能多的空间。 在这里我们需要一种可以解决这些问题的新技术。 索引分配方案 索引分配方案不是维护所有
-
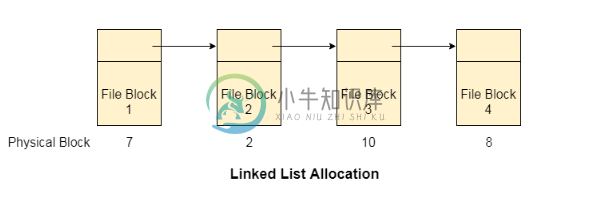 链表分配
链表分配链表分配解决了连续分配的所有问题。 在链表分配中,每个文件都被视为磁盘块的链表。 但是,分配给特定文件的磁盘块不需要在磁盘上连续存在。 分配给文件的每个磁盘块都包含一个指向分配给同一文件的下一个磁盘块的指针。 优点 链接分配没有外部碎片。 可以使用任何空闲块来满足文件块请求。 只要空闲块可用,文件可以继续增长。 目录条目将仅包含起始块地址。 缺点 随机访问不提供。 指针在磁盘块中需要一些空间。 链