《华为机试》专题
-
Spring靴执行器-“/关机”失败,错误为500
应用程序运行良好,管理端口运行良好。我可以浏览统计信息、检查运行状况等。我还启用了远程关闭endpoint,它正确地显示在endpoint的localhost:{mgmt_port}/actuator列表中。 我的问题 但是,当我转到localhost:{mgmt_port}/shutdown时,我看到: 10:01:42.496[main]信息O.s.B.C.E.T.TomcatEmbedded
-
Cron作业作为程序或本机k8s方式
为了处理这个任务,我目前看到了两种方法 创建k8s cronjob--它是本机的k8s CRD,并为它使用,https://kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/ PROS正在使用K8S原生方式来处理此类问题 缺点-创建一些抽象… 任何建议,建议哪一个是更好的方法使用,如果我需要一个完全控制这些工作
-
为什么Netty中引入了本机epoll支持?
我相信Java的NIO库将在Linux机器上使用epoll。在Linux机器上使用Epoll而不是NIO有哪些优点。
-
推土机深度映射字段为字符串
我有一个非常复杂的对象。 我的目标是将问题答案集映射展平,以便将值中的所有列表合并为一个 我没有试图找出如何在Dozer中将所有这些列表合并到一个列表中,我甚至不确定它是否能够做到,而是编写了一个自定义setter。 我假设这意味着Dozer只需读取第一个对象的调查并将其放入makeFlatSurvey,但它读取调查对象上的questionAnswerGroup字段,然后遍历QuestionAns
-
为什么随机设备创建成本很高?
C 11支持通过<代码> 我看过多本书,其中提到持续构建和销毁std::random\u device、std::uniform\u int\u distribution非常昂贵 为什么创建/销毁这些对象的成本很高?这里的昂贵到底是什么意思?它在执行速度、可执行文件大小或其他方面是否昂贵? 有人能解释一下吗?
-
JavaFX:具有本机行为的自定义窗口
我希望在JavaFX中有一个完全定制的窗口。与此处完全相同的问题: https://code.msdn.microsoft.com/WPF-styling-a-Window-in-fcf4e4ce 使用未DECORATED JavaFX阶段,我必须自己实现所有窗口功能-并失去所有本机窗口行为,包括: 拖动到顶部时最大化 拖动到两侧时的并排视图 单击任务栏时最小化/最大化 我可以以某种方式访问原生W
-
生成N个和为M的均匀随机数
这个问题以前也有人问过,但我从来没有真正看到过好的答案。 > 我想生成8个和为0.5的随机数。 我希望每个数字都是从一个均匀分布中随机选择的(即下面的简单函数将不起作用,因为数字将不是均匀分布的)。 代码应该是可推广的,这样您就可以生成N个和M(其中M是正浮点)的均匀随机数。如果可能的话,能否也请你解释一下(或用一个图表示)为什么你的解会在适当的范围内均匀地产生随机数? 失手的相关问题: 在pyt
-
为什么在Spring开机时没有找到bean?
这个问题解决了。请看下面的核对答案。 注入点有以下注释:-@org.springframework.beans.factory.annotation.autowired(required=true) 行动: 考虑在您的配置中定义一个类型为'DAO.UserRepository'的bean。 进程结束,退出代码为%1
-
为React本机项目生成签名APK失败
我得到一个错误>Task:app:ProcessReleaseResources失败,将任务':app:ProcessReleaseResources‘的任务工件状态放入上下文需要0.0秒。文件或目录'/users/apple/desktox/myparkkingapplocalrepo/the-parkking-reactnative/android/app/libs',未找到文件或目录'/us
-
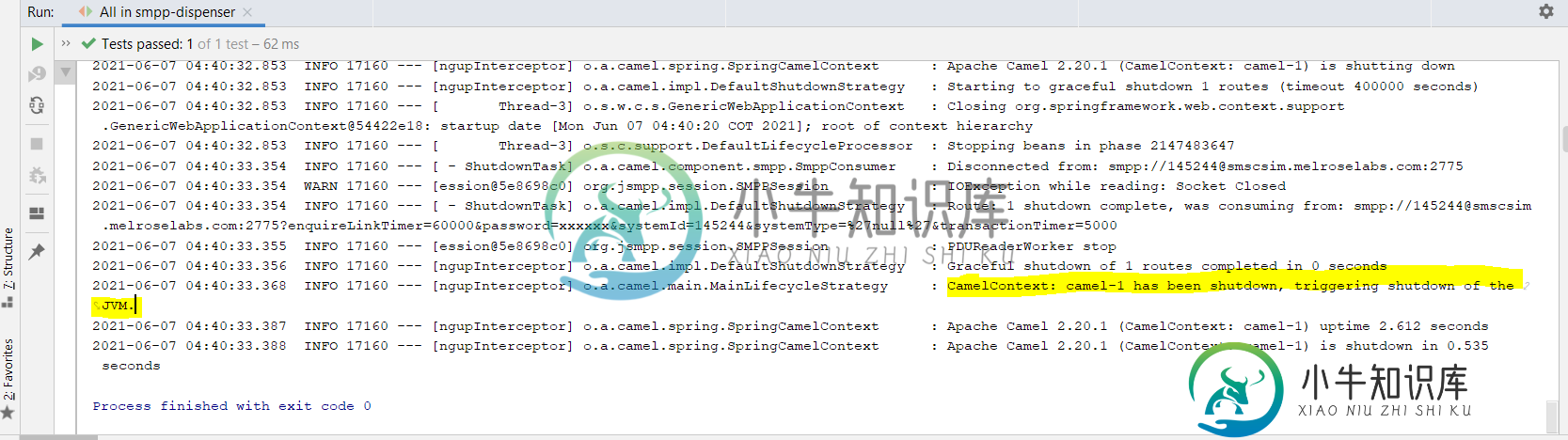 为什么Apache Camel会导致优雅的关机
为什么Apache Camel会导致优雅的关机你好,我有一个用Kotlin编写的应用程序,它使用Spring Boot框架和Apache Camel:https://camel.Apache.org/components/latest/smpp-component.html#_spring_boot_auto_configuration 所以我是Smpp协议的新手,我正在尝试连接到SMC模拟器,所以我想我的“客户机”应该在等待来自SMC的消息
-
 为什么Jacoco分支机构的报道会说
为什么Jacoco分支机构的报道会说我的公司要求我们对新代码的测试覆盖率达到90%,对于Java代码,我使用gradle jacoco插件,这很好;然而,当分支数量开始呈指数增长时(夸张地说,这可能是几何增长),分支覆盖率很难提高到90%。 这里有一个很做作的例子: 而测试: 以下是报道的内容: 它还说,我错过了4个分支中的1个,或者换句话说,我覆盖了4个分支中的3个(75%的分支覆盖率)。 如果我在这里增加布尔数,分支数似乎是n*
-
Ansible-如何为每个主机顺序执行playbook
我正在使用ansible编写API部署脚本。我希望通过我的库存文件中的每个主机顺序工作,这样我就可以一次完全部署到一台机器上。 谢谢
-
将PostgreSQL查询(函数)转换为本机查询
我试图将下面的PostgreSQL查询转换为本机查询,但遇到错误。 Postgres查询: 本机查询: 但我得到了以下错误: 无法提取结果集;SQL [n/a];嵌套异常是 org.hibernate.exception.SQLGrammarException: 无法提取 ResultSet
-
1. 为什么计算机用二进制计数
1. 为什么计算机用二进制计数 人类的计数方式通常是“逢十进一”,称为十进制(Decimal),大概因为人有十个手指,所以十进制是最自然的计数方式,很多民族的语言文字中都有十个数字,而阿拉伯数字0~9是目前最广泛采用的。 计算机是用数字电路搭成的,数字电路中只有1和0两种状态,或者可以说计算机只有两个手指,所以对计算机来说二进制(Binary)是最自然的计数方式。根据“逢二进一”的原则,十进制的1
-
随机/随机比较器
问题内容: 有没有什么方法可以模拟Collections.shuffle的行为,而比较器不容易受到排序算法实现的影响,从而确保结果安全? 我的意思是不违反可比合同等。 问题答案: 不打破合同就不可能实现真正的“改组比较器”。合同的一个基本方面是,结果是可 重现的, 因此必须确定特定实例的顺序。 当然,您可以使用混洗操作预先初始化该固定顺序,并创建一个比较器来精确地建立此顺序。例如 虽然没有意义。显