《超星集团》专题
-
采集帮助 - 了解采集 - 关于采集
关于采集: 什么是采集呢?我们可以这样理解,我们打开一个网站,看到有一篇文章很不错,于是将文章的标题和内容复制,然后将这篇文章转到我们的网站上,这个过程就可以称作采集,将别人网站上对自己有用的信息转到自己网站上。 采集器也是这样,不过整个过程是由电脑来完成的,我们复制人家的标题和内容,是在知道什么地方是内容,什么地方是标题前提下进行操作的,但电脑是不知道的,所以我们要告诉电脑怎么识别怎么采,这就是
-
如何设置SQL以查找从上一个星期日到这个星期日(1周)的记录
问题内容: 这类似于我现在所拥有的,即: postsdate 这将为我提供一个作者在过去1周内发布过多少次的统计信息。 我想拥有它,所以如果我要在星期日的下午5:30运行该程序,以查找从上一个星期日12:00 AM到这个星期日12:00 AM的帖子。同样,如果我忘记了在星期天和现在的星期一运行它。我仍然希望它从上一个星期日12:00 AM运行到刚过12:00 AM的星期日。 编辑: 我已经完成了使
-
空结果集的集合
问题内容: 我希望将空结果集的总计设置为0。我尝试了以下方法: 结果: 子问题:上面的工作在Oracle中行不通吗? 问题答案: 在有关聚合函数的文档页面中: 应该注意的是,除了这些函数, 当没有选择任何行时 ,这些函数将 返回空值 。特别是,没有行返回空值,而不是预期的零值。必要时,该函数可用于将零替换为null。 所以,如果你想保证返回的值,适用于 结果 的,而不是它的参数: 至于Oracle
-
列表子集的子集
在R中,我有一个列表,由12个子列表组成,每个子列表本身由5个子发布者组成,如下所示 列表和子列表 在本例中,我想为每个子列表提取信息“MSD”。 我可以提取每种使用方法的级别“统计信息” 这很有效。它给了我子列表“statistics”中包含的所有值,但是,对于每个列表,我想向下一级,因为我对其他数据(如MSerror、Df等)不感兴趣。。。。。只有MSD 我试过了 还有许多人没有成功。 如果我
-
ignite集群与kubernetes集成
我是新点燃的。 步骤1:我在两个VM(ubuntu)中安装了Ignite 2.6.0,在一个VM中启动了节点。下面有COMAND。bin/ignite.sh examples/config/example-ignite.xml 步骤2:我的所有配置都在example-default.xml中 步骤3:在其他VM中执行包含datagrid逻辑的client.jar(该VM既是客户机也是节点)。 步骤
-
从集群收集度量
有人能建议从节点集群收集指标的最佳模式吗(每个节点都是带有Java应用程序的Tomcat Docker容器)? 我们计划使用ELK堆栈(ElasticSearch、Logstash、Kibana)作为可视化工具,但我们的问题是如何将指标交付给Kibana? 我们使用DropWizard度量库,它提供每个实例的度量(量表、计时器、直方图)。 显然,应该收集每个实例的一些指标(例如,cpu、内存等..
-
1.8.3 集群&集群发现
Cluster Cluster.EdsClusterConfig Cluster.OutlierDetection Cluster.LbSubsetConfig Cluster.LbSubsetConfig.LbSubsetSelector Cluster.LbSubsetConfig.LbSubsetFallbackPolicy (Enum) Cluster.RingHashLbConfig C
-
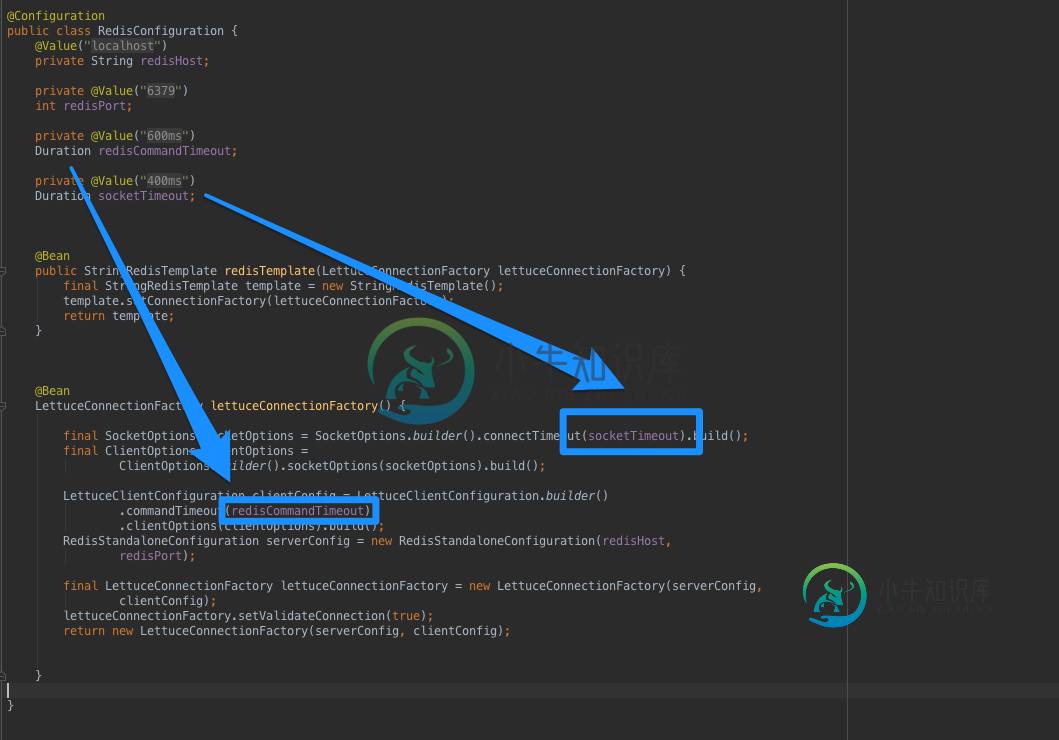 Redis客户端Lettuce命令超时与套接字超时
Redis客户端Lettuce命令超时与套接字超时我们已经定义了Lettuce客户端连接工厂,以便能够连接到定义自定义套接字和命令超时的Redis: 莴苣文档定义默认值: 默认套接字超时为10秒 默认命令超时为60秒 如果Redis服务中断,应用程序必须在300ms内接收超时。哪个值必须定义为最大值? Github示例项目:https://github.com/cristianprofile/spring-data-redis-lettuce
-
AWS执行-APIendpoint请求超时/拨号tcp I/O超时
我已经创建了一个execute-apiendpoint,并将443端口添加到安全组中。我还禁用了私有DNS名称,但仍然得到一个“endpoint请求超时”/拨号tcp 52.28...:443:I/O超时错误。我还用postman测试了我想要访问的API,它按预期工作。我错过了什么。
-
GAE超出了实例内存限制。超过2048个月?
我很好奇如何处理GAE中的内存限制。目前,我有这个应用程序,需要大量的CPU/内存。 我尝试在GAE上使用b8实例运行它(基本上是使用4.8GHz CPU的顶级实例) 我还尝试手动设置CPU的数量 但无论我做什么,我总是达到同样的记忆限制。。。(见下文) GET500 0 B 43 s Unknown/_ah/start在总共处理0个请求后,超过了2048 MB的软内存限制,达到3163 MB。考
-
okhttp客户端超时与apache超时之间的差异
在过去,我使用Apache的http客户端。我有以下设置: 连接请求超时 连接超时 读取/套接字超时 连接池大小 null
-
Keycloak会话和令牌超时:客户端登录超时
所以我的问题是:什么是“客户端登录超时”,什么是一个好的默认设置?对我来说,一个完美的答案是在工作流失败时从用户的角度描述工作流(比如用户在点击电子邮件验证链接之前喝了一分钟咖啡)和/或进一步阅读的链接
-
用推断的超类替换个体的当前超类
问候Ignazio Palmisano教授, 我有一个关于OWL-APIV5的问题 我添加了一个新的单独的“x”作为Thing的子类,并添加了单独的属性。 初始化reasoner和precomputeInferences() 目标: 子问题: 2)我是否必须保存新的推断本体,然后按照断言处理它,以便检索那个类?我不喜欢这样做,因为我的兴趣只是用推断的超类替换当前的单个超类。 我试图找到如何做到这一
-
如何声明outputChannel和处理超文本传输协议响应HttpRequest ExecutingMessageHandler在Spring集成
下面是HttpRequestExecutingMessageHandler的配置 我应该如何配置httpResponseChannel来处理httpResponse。如果http状态代码为201,我想将源文件移到成功文件夹,或者移到错误文件夹。 我将spring integration 5与spring boot结合使用。
-
JS实现的集合去重,交集,并集,差集功能示例
本文向大家介绍JS实现的集合去重,交集,并集,差集功能示例,包括了JS实现的集合去重,交集,并集,差集功能示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JS实现的集合去重,交集,并集,差集功能。分享给大家供大家参考,具体如下: 1. js 实现数组的集合运算 为了方便测试我们这里使用nodejs,代码如set_operation.js 2. 测试 我们这里使用nodejs来测试 测试