《海尔》专题
-
javascript - 如何使用JS调用海康威视身份证阅读器?
本地已经有海康威视的身份证阅读器设备 如何实现,设备读取身份证信息,然后JS来调用获取数据显示在网页之中。 设备与电脑通过USB数据线连接
-
 上海华勤技术网络工程师实习技术面分享
上海华勤技术网络工程师实习技术面分享中午boss投了简历,已读不回;晚上8点左右突然一个电话,聊了27分钟,第一次面试毫无准备,巨紧张;结束时面试官说过问题不大,明天还有HR面,但第二天就停止招聘了(估计是我外地西安,实习本意3个月有点短,招其他人了😥) 下面分享电话面过程,序号不分先后 1、 Vlan的作用 Vlan主要是隔离广播域,起到安全和便于管理的作用 Vlan起源于802.1q,本质是对标签操作,有access、trun
-
你来说说亚马逊的海外购与竞品的海淘业务,包括京东全球购、天猫国际、网易考拉等有什么区别。
本文向大家介绍你来说说亚马逊的海外购与竞品的海淘业务,包括京东全球购、天猫国际、网易考拉等有什么区别。相关面试题,主要包含被问及你来说说亚马逊的海外购与竞品的海淘业务,包括京东全球购、天猫国际、网易考拉等有什么区别。时的应答技巧和注意事项,需要的朋友参考一下 1 亚马逊的海外购 亚马逊的海外购属于全球直采性自营模式,由平台统一调配,统一在海外仓发货。亚马逊的海外购业务 对接各大亚马逊海外网站(包括
-
随着我国游戏行业的发展,越来越多优秀的国产手游已经走出国门,打入海外市场。请你简要分析一下国产手游在海外推广时,应如何保证海外用户的游戏体验?
本文向大家介绍随着我国游戏行业的发展,越来越多优秀的国产手游已经走出国门,打入海外市场。请你简要分析一下国产手游在海外推广时,应如何保证海外用户的游戏体验?相关面试题,主要包含被问及随着我国游戏行业的发展,越来越多优秀的国产手游已经走出国门,打入海外市场。请你简要分析一下国产手游在海外推广时,应如何保证海外用户的游戏体验?时的应答技巧和注意事项,需要的朋友参考一下
-
怎么在海量数据中找出重复次数最多的一个?
本文向大家介绍怎么在海量数据中找出重复次数最多的一个?相关面试题,主要包含被问及怎么在海量数据中找出重复次数最多的一个?时的应答技巧和注意事项,需要的朋友参考一下 做法相同,先hash到小文件,然后hashmap计数比较
-
如何显示同一个月的名称,两年在X轴的海图
我的应用程序中有一个Highcharts图表。我需要显示一年中每个月售出的汽车数量,此图表显示了 13 个月时间段(例如:2017 年 6 月至 2018 年 6 月)的汽车销量,以便显示同月(两年)两次。X 类别应该是这样的(6 月、7 月、8 月、9 月、10 月、11 月、12 月、1 月、2 月、3 月、4 月、5 月、6 月) 但问题是图表中只显示了一个“六月”月份。我认为类别名称重复是
-
rsync备份海量文件时占用大量内存的解决方法
本文向大家介绍rsync备份海量文件时占用大量内存的解决方法,包括了rsync备份海量文件时占用大量内存的解决方法的使用技巧和注意事项,需要的朋友参考一下 linux发行版中大多都自带rsync,不过版本比较低,一般都是2.6.X 在2.X的版本中,rsync备份时都是先列表再备份(添加或者删除),在处理大量文件时,会耗费比较多的内存。 备份的时候,rsync扫描到的每个文件(目录也一样),在它的
-
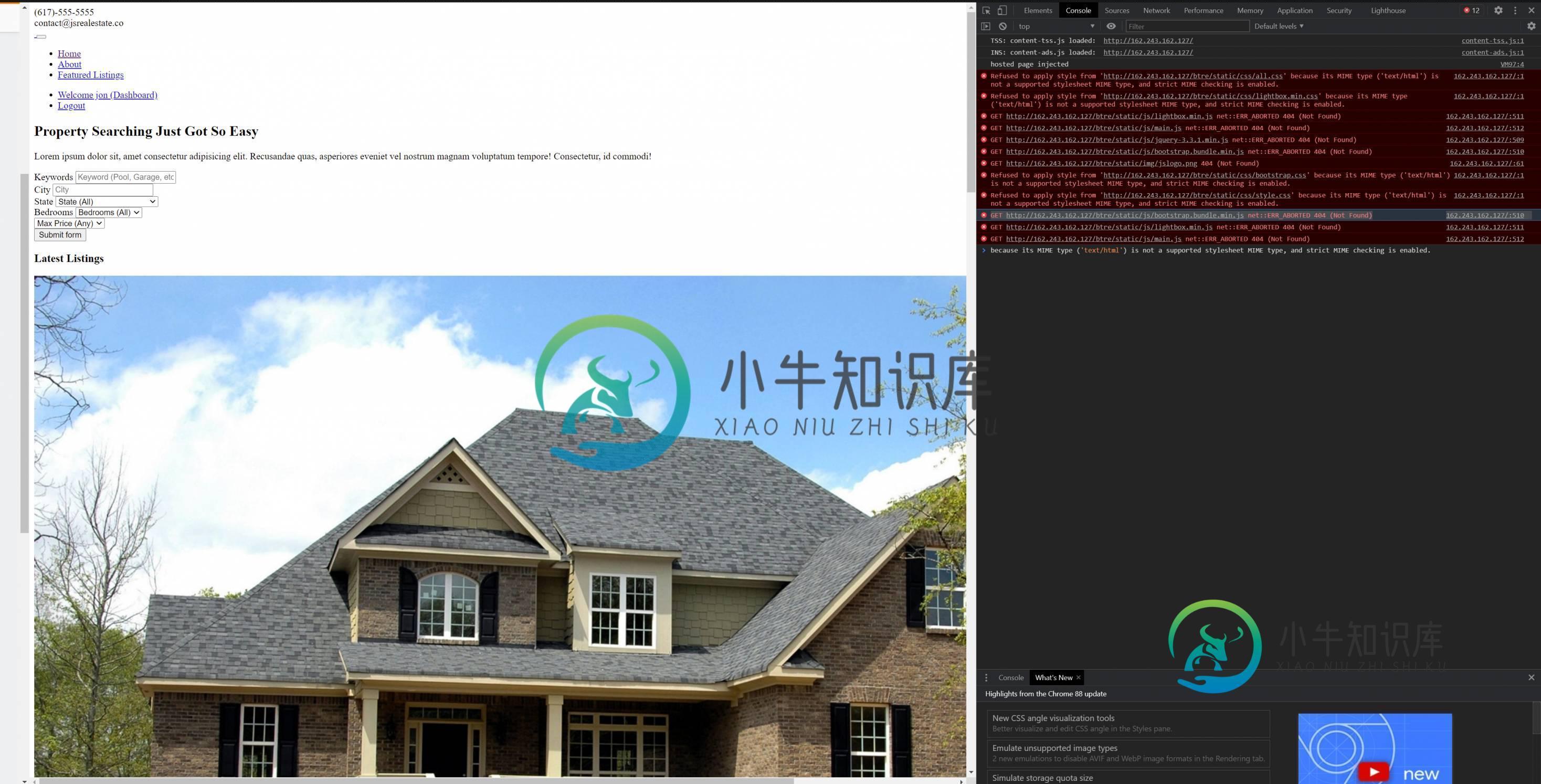 Nginx数字海洋部署中加载静态文件时出现问题
Nginx数字海洋部署中加载静态文件时出现问题Django初学者在这里... 在最终部署到数字海洋液滴时加载静态文件时遇到问题 我用的是Nginx和Gunicorn。 我遵循了Traversy Media的教程,但我无法通过我的Digital Ocean ipv4在浏览器中显示静态文件。检查后,它会抛出这些多个错误。 这是我的nginx设置 这是我的枪角设置 我曾多次尝试在终端中运行collectstatic,但它不起任何作用。。表示它有“0
-
可以通过API为YouTube合作伙伴上传海报帧图像吗?
我的一个客户是YouTube合作伙伴,可以在他们通过应用编程接口上传和管理的视频中上传/设置后帧。但是,他们希望能够在为他们编写的应用程序中上传和设置这些图像,以管理他们所有的视频资产。 我希望能够上传海报图像(或者更糟的是提供时间码来获取大致的视频帧),以便在上传和/或上传后通过更新来设置海报帧。 这对伴侣来说可能吗?或者合作伙伴是否受限于必须在YouTube用户界面中手动执行此操作?
-
Spring启动(数据)海森布格与检测数据库驱动程序
在开发Spring BootRESTendpoint时,我的应用程序会遇到奇怪的(heisenbug)行为。我为每个endpoint项目制作了单独的模块,这也可能与此相关。在细节上,它可以运行一次,但在重新运行后会失败,可能运行一个endpoint,但不会运行另一个,反之亦然。 描述: 无法确定数据库类型 NONE 的嵌入式数据库驱动程序类 行动: 如果你想要一个嵌入式数据库,请在类路径上放置一个
-
 海信信动力 网络科技 一面二面 hr面面经 已拒
海信信动力 网络科技 一面二面 hr面面经 已拒查了下海信网络科技主要是做大数据相关的智慧交通和智慧城市。 35min 一位友善的大哥 自我介绍一下? 说一下你的项目是在哪搭建的?有上线吗?使用CDH吗? 数仓项目说一下你的项目是如何分层的? Spark 项目说一下为什么用 Spark 不用 Flink? 知道数仓中数据血缘关系的概念吗?你在项目中是怎么管理的?知道他的工具吗? 数据治理知道不?面试官说可以看一下 Atlas 你在数仓项
-
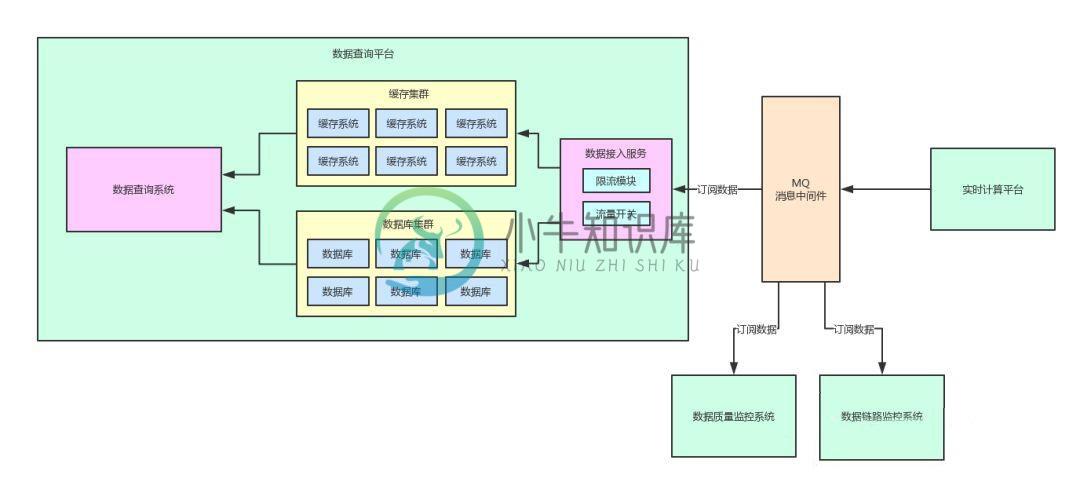 高并发+海量数据情况下如何实现系统解耦?【下】
高并发+海量数据情况下如何实现系统解耦?【下】主要内容:一、前情提示,二、基于消息中间件的队列消费模型,三、基于消息中间件的“Pub/Sub”模型,四、RabbitMQ中的exchange到底是个什么东西?,五、默认的exchange,六、将消息投递到fanout exchange,七、绑定自己的队列到exchange上去消费,八、整体架构图一、前情提示 上一篇文章《高并发+海量数据下如何实现系统解耦?【中】》分析了一下如何利用消息中间件对系统进行解耦处理。 同时,我们也提到了使用消息中间件还有利于一份数据被多个系统同时订阅,供多个系统来使
-
 高并发+海量数据情况下如何实现系统解耦?【上】
高并发+海量数据情况下如何实现系统解耦?【上】主要内容:一、写在前面,二、背景回顾,三、实时计算平台与数据查询平台之间的耦合,四、下集预告一、写在前面 之前更新过一个“亿级流量系统架构”系列,主要讲述了一个大规模商家数据平台的如下几个方面: 如何承载百亿级数据存储 如何设计高容错的分布式架构 如何设计承载百亿流量的高性能架构 如何设计每秒数十万并发查询的高并发架构 如何设计全链路99.99%高可用架构。 接下来,我们将会继续通过几篇文章,对这套系统的可扩展架构、数据一致性保障等方面进行探讨。 如果没看过本系列文章的同学可以先回过头看
-
 ⽹易云⾳乐海外直播产品面试4⾯复盘(已offer)
⽹易云⾳乐海外直播产品面试4⾯复盘(已offer)大家好,我是2023年毕业的应届生,马上要参加秋招了在找大厂的实习,有同样秋招的小伙伴欢迎大家多多交流哈。自己的专业是电子信息工程,之前没有任何产品相关的经验,后面拿到了快手的产品实习,现在实习满三个月,打算换实习,目前拿到了字节国际化达人平台和网易云音乐直播相关业务两个产品offer,这篇文章再来分享一下网易云音乐的面经,如果感兴趣欢迎关注~ ⼀⾯(25min) ⾯试官提问: 1. ⾃我介绍 2
-
 上海人工智能实验室后端开发实习面经(已oc)
上海人工智能实验室后端开发实习面经(已oc)一面 计算机基础你都学过了是吧,那我就不问了() 谈一谈你对hashmap的理解。 hashmap线程不安全的场景,如何去解决。 concurrenthashmap在1.6之后做了哪些改进。 hashmap在链表长度为8,数组长度为64时链表转红黑树,为什么设定这两个默认值。 synchronized 和 Lock的区别。 谈一谈在高并发的情况下,会遇到哪些问题,怎么去解决。 如果从线程池的角度去