《兴业数金面试》专题
-
 阿里数分面试题
阿里数分面试题1、淘宝服装品类如果构建指标体系评估业绩情况,如何构建? 2、如何搭建天猫的业务监控指标体系? 请问有大佬可以分析一下思路吗
-
ebay-数据仓库面试
英文自我介绍和项目介绍 Good Afternoon, my name is Wang Longjiang,graduated from Anhui University. I have been working in the Institute of Aerospace Information, Chinese Academy of Sciences for two years. Focus o
-
 数仓实习生面试
数仓实习生面试总体问的都是蛮基础的,也是根据简历来问的,你简历上写熟悉哪些,就会问哪些 1.自我介绍 2.项目来源,自己做的还是网上找来做的 3.离线数仓介绍 4.项目遇到的问题(提到kafka的重复数据) 5.为什么kafka会出现重复数据 6.你项目中怎么处理的 7.数仓分层的好处 8.数仓分了哪几个数据域 9.讲一些维度建模 10.常见的维度模型(雪花、星型) 11.使用场景 12.除了维度建模,还有哪些
-
 360数分面试记录
360数分面试记录1.大数据概念? 2.用接口啥啥的爬过数据吗? 3.linux的指令会不会? 4.hadoop了解吗? 5.sql怎么优化? 我:………… 还需努力。。。。。。
-
企业招聘面试题难倒众求职者 10道题无人全对
ter> 一份只有10道题的面试考卷,没有一个求职者答对。试卷在朋友圈不停被转发,它到底有多难?国学、茶道、养生、诗词、佛学全部涵盖。昨天,出题的重庆某公司项目负责人说,出这套试题的目的,一是考察求职者的综合素养,同时也是在面试中观察求职者在面对难题时的态度。 求职者 允许上网查,但有些题找不到答案 回忆起刚看到试卷的那一刻,求职者吴林(化名)说仿佛“五雷轰顶”。“一眼瞄下去,有些简直听都没听说过
-
 测试开发 - 面经 - 字节跳动(国际化商业产品与技术)
测试开发 - 面经 - 字节跳动(国际化商业产品与技术)自我介绍 在介绍中说了解广告是,具体讲讲 是在抖音或者头条上有推送过广告么 讲讲实习,有什么问题,如何解决的,有什么样的效果 当时对于日志和脚本的监控是怎么做的 日志信息一般用什么命令看呢 git相关,基本操作,拉分支推分支当时是如何操作的 get请求和post请求有什么区别 Python装饰器 算法:ACM模式 最长字符子串的长度,力扣原题 思路是什么样的 目前大三可以出来实习是吗 反问环节 需
-
尝试在linux中构建Azure函数应用程序,以下错误返回“未找到作业函数。请尝试将作业类和方法公开”
当我尝试在Linux(Ubuntu 18.04)中构建azure函数时,返回错误。以下是我在从git克隆存储库process.After中遵循的步骤。 在输出返回之后, 下面是关于我的系统的信息,
-
一位交易商记录了以下交易:a)以现金卢比开始业务。30000 b)购买了卢比的证券(现金)。9000 c)购买商店,价格为卢比。30000(10000现金,贷款剩余)d)出售
本文向大家介绍一位交易商记录了以下交易:a)以现金卢比开始业务。30000 b)购买了卢比的证券(现金)。9000 c)购买商店,价格为卢比。30000(10000现金,贷款剩余)d)出售,包括了一位交易商记录了以下交易:a)以现金卢比开始业务。30000 b)购买了卢比的证券(现金)。9000 c)购买商店,价格为卢比。30000(10000现金,贷款剩余)d)出售的使用技巧和注意事项,需要的朋
-
 数字马力-测试-长沙二面面经
数字马力-测试-长沙二面面经#24秋招#(面试官很和蔼,可惜我太菜了) 1、自我介绍 2、我现在说一个场景昂,淘宝双十一用户下单支付的时候,假如有1000个人同时下单,请求支付宝的接口,这1000人选择银行卡支付,支付宝再调用银行的接口,银行的接口只能承受800个人同时下单,如何处理?(太菜了,坑坑巴巴说了几个方法) 3、你自己做的项目有没有遇到什么难点,项目登录用到加盐算法,如何实现的?我感觉这面试官比我还懂我的项目(哈哈
-
 数字马力-质量测试-一面面经
数字马力-质量测试-一面面经大约30min 1、自我介绍; 2、Spring、SpringBoot和SpringMVC的区别; 3、说一下归并排序的思想,归并排序和快速排序那个速度更快; 4、说一下二叉树的应用场景,前序遍历和后序遍历的区别以及应用场景; 5、Mysql事务和索引有了解吗?说一下Mysql的索引; 6、sql语句到Mysql的整个执行流程; 7、说一下你对Mysql数据库的使用,像聚集函数、外连接、group
-
大数据数仓高级面试题 3
主要内容:1.建模锯齿,2.数据粒度的锯齿操作,3.下游表依赖上游表问题,4.数仓数据域划分方式,5.数仓一致性是如何保证的,6.数仓优化,7.数据全生命周期,8.数仓建模问题,9.数仓建模过程1.建模锯齿 建模锯齿是指在建模过程中的一种常见的效应,其中模型的输出可能会产生锯齿状的波动。这种效应通常是由于模型的不稳定性或过度拟合导致的。 在建模过程中,锯齿可能会使模型的表现变差,并且在预测新数据时也可能出现不一致的结果。因此,在建模时需要注意避免出现锯齿状的波动。 一种常用的方法是使用正则化来限
-
大数据数仓高级面试题 1
主要内容:1.数仓高内聚低耦合,2.多重粒度,3.如何提高查询效率,4.数仓数据域划分几种方式,5.粒度操作,6.SQL实现,7.数仓中ODS层命中多少为合理,8.数仓价值链的体现和实现,9.建立数仓的步骤,10.指标生命周期的评估,11.数据治理,12.数仓的目的1.数仓高内聚低耦合 一般复杂的公共逻辑可以采用抽象类和抽象方法的方式下沉到共有模块中,然后由相关子类去实现抽象方法,来实现不同的功能。这样可以将复杂的逻辑拆分成各个子类,使得类之间的耦合度降低,提高代码的可维护性。 2.多重粒度 在
-
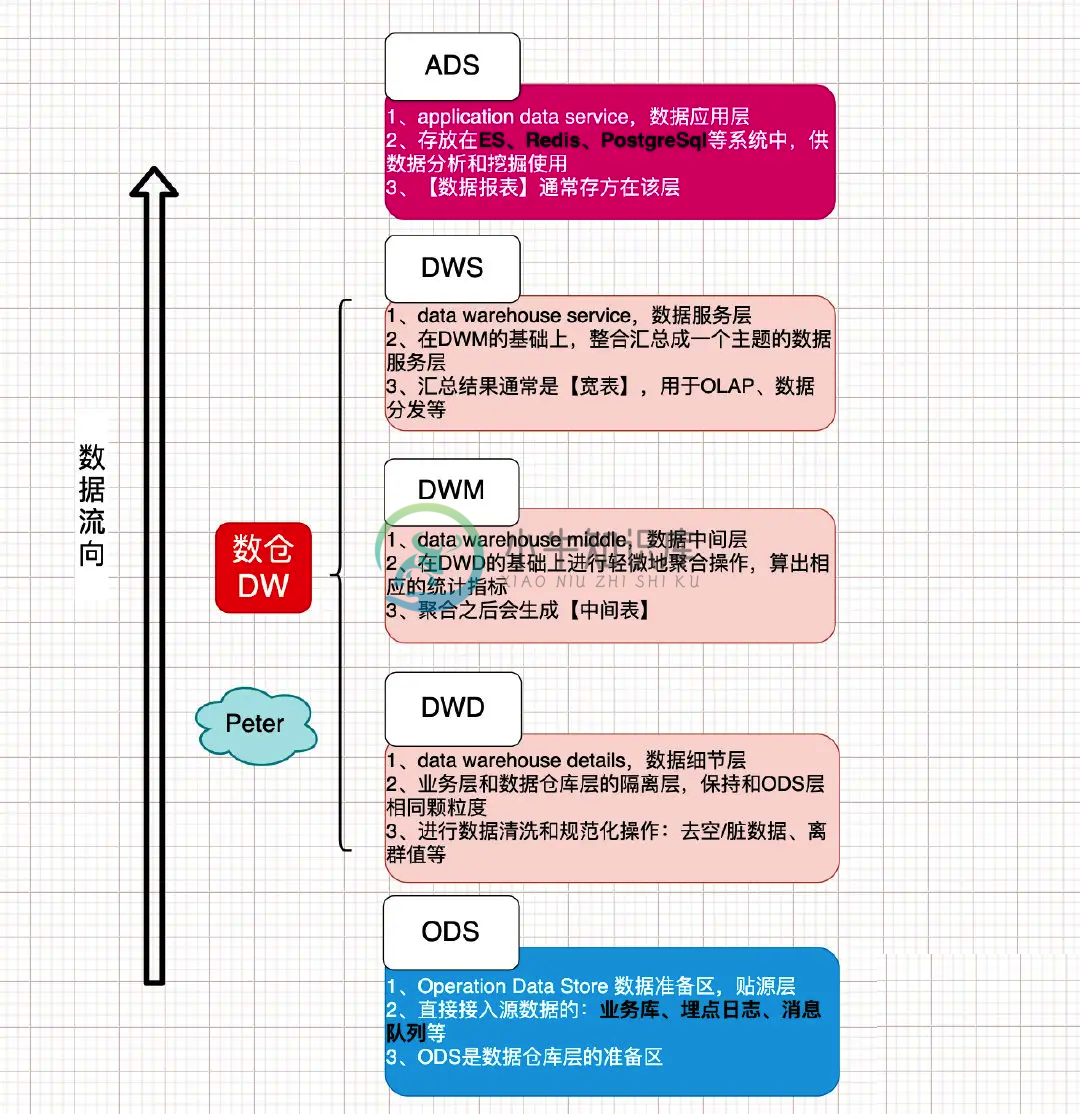 大数据数仓高级面试题 4
大数据数仓高级面试题 4主要内容:1.数仓构建,2.数仓最重要的是什么,3.如何保证数据的准确性,4.如何做数据治理?数据资产管理呢,5.如何控制数据质量,6.元数据的理解?元数据管理系统,7.数仓如何分层的?及每一层的作用,8.为什么要分层1.数仓构建 1). 前期业务调研 需求调研 数据调研 技术选型 2). 提炼业务模型,总线矩阵,划分主题域; 3). 定制规范 命名规范、开发规范、流程规范 4). 数仓架构分层:一般分为操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括
-
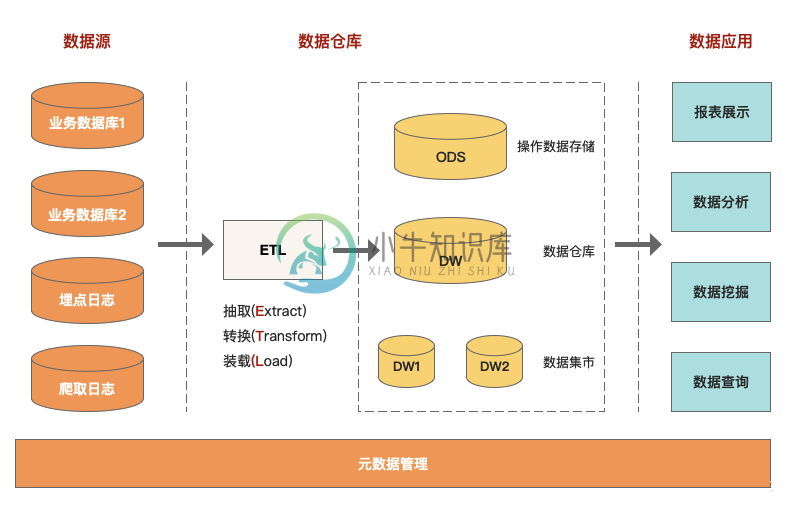 大数据数仓高级面试题 2
大数据数仓高级面试题 2主要内容:1、什么是数据仓库?,2、数据仓库和数据库的区别?,3、如何构建数据仓库?,4、什么是数据中台?,5、数据中台、数据仓库、大数据平台、数据湖的关键区别是什么?,6、大数据有哪些相关的系统?,7、如何建设数据中台?,8、数据仓库最重要的是什么?,9、概念模型、逻辑模型、物理模型分别介绍一下?,10、SCD常用的处理方式有哪些?,11、怎么理解元数据?,12、数仓如何确定主题域?,13、如何控制数据质量?,,,,1、什么是数据仓库? 权威定义:数据仓库是一个面向主题的、集成的、相对稳定的、
-
 爱数二面
爱数二面1、自我介绍 2、软件测试的流程,问到了是怎样学到这些流程的? 3、测试用例设计方法,我说了参考同类型的产品,然后又让我说怎么样找到同类型产品的测试用例 4、编写测试用例的要素 5、使用过那些操作系统,Linux 修改文件权限的命令,又问到是自己确实用过还是就是纯背诵的; 6、了解Linux磁盘阵列吗 7、关系型数据库的对象 8、数据库事务,我说了一些书本知识,又被问到是不是背诵的概念; 9、个人