《存储》专题
-
有没有办法将响应实体存储在redis缓存中?
我尝试了以下代码,但出现了错误-spring web ResponseEntity无法序列化。 org.springframework.data.redis.serializer.SerializationException:无法序列化;嵌套异常org.springframework.core.serializer.support.SerializationFailedException:无法使用
-
我的变量在C中存储在内存的什么地方?
我认为它们的分配如下: 全局变量-------->数据 静态变量-------->数据 常量数据类型------>代码 局部变量(在函数中声明和定义)---------->堆栈 在main函数中声明和定义的变量------>堆 指针(例如,、)-------->heap 动态分配的空间(使用malloc和calloc)-------->stack 我只是从C的角度提到这些变量。 如果我不对,请指正
-
如果内存存储已满,EhCache将新元素放入磁盘
我想结合内存和磁盘缓存使用EhCache。当内存已满时,EhCache应将新元素移动到磁盘。e、 g.我在ehCache内存存储中有100个元素,并尝试放入第101个元素,如果内存已满,则将第101个单元放入磁盘,而不是第一个单元。 你能让我知道实现这一点的缓存配置吗?
-
Bouncy Castle密钥存储(BKS):java.io.IOException:密钥存储的版本错误
我必须连接到一个基于REST的WebService。 (https://someurl.com/api/lookup/jobfunction/lang/en) 在IE或chrome浏览器中,当我尝试访问这个URL时,我会得到一个证书,我必须信任它并接受它才能继续,然后我必须输入用户名和密码,然后我会得到JSON响应。 同样的事情,我必须为一个android应用程序编程。 > 尝试使用自定义Easy
-
将证书添加到密钥存储区和信任存储区
证书、私钥(客户端)和客户端证书都是pem格式的,我必须将它们添加到信任存储区和密钥存储区中。我该怎么做呢?到目前为止,我在cmd(windows)中有命令: > 要生成PKC(key:客户端私钥,cert:客户端cert,CA:CACERT):openssl pkcs12-inKey key.pem-in cert.pem-export-out keystored.p12-certfile CA
-
在Azure表存储中存储应用程序日志的策略
我要确定一个在Azure表存储中存储日志信息的好策略。我有以下内容: PartitionKey:日志的名称。 ROWKEY:倒置的日期时间刻度, 这里唯一的问题是分区可能会变得非常大(数百万个实体),并且大小会随着时间的推移而增加。 但尽管如此,所执行的查询类型将始终包括(不扫描)和筛选器(小扫描)。 例如(在自然语言中): 如果查询同时在和上完成,那么我理解分区的大小并不重要。
-
如何将spark DataFrame作为CSV存储到Azure Blob存储器中
我正试图从本地Spark集群将Spark DataFrame存储为Azure Blob存储中的CSV 首先,我用Azure Account/Account键设置配置(我不确定什么是正确的配置,所以我已经设置了所有这些) 似乎这个问题已经在数据库论坛上报告了!! 在Azure Blob上存储DataFrame的正确方法是什么?
-
Android-在移动存储上保存位图图像,无需压缩
从远程url保存位图图像的典型方法(基于研究)是: 我无法保存位图,除非它被压缩(位图总是未压缩)。远程图像大小为32KB,压缩后为110KB。我知道我必须降低压缩参数以获得更小的尺寸,但远程图像经过优化,效率更高。 有没有一种方法可以在不压缩远程图像的情况下将其保存到移动存储上? 我的问题的答案===== 首先,我为误导内容道歉;我只想保存可以是png | jpeg | gif |等格式的图像。
-
将文件列表从S3存储桶复制到S3存储桶
有没有一种方法可以将文件列表从一个S3存储桶复制到另一个存储桶?两个S3存储桶都在同一个AWS帐户中。我可以使用aws cli命令一次复制一个文件: 然而,我有1000份文件要复制。我不想复制源存储桶中的所有文件,因此无法使用sync命令。有没有一种方法可以用需要复制的文件名列表来调用一个文件,从而自动化这个过程?
-
Spring数据Neo4j存储库缺少分页和排序存储库
我已经实现了一个小用例来评估Spring Data Neo4j。我有一个接口,它扩展了GraphRepository。 界面是这样的: 这给了我错误< code >“类型PublicRepository的层次结构不一致”。 这种类型的错误是因为当前类扩展/实现的类/接口之一不存在,而当前类又在扩展/实现另一个类/接口。 查看核心库的包我发现库中没有扩展为CRUDRepository的接口。我在Ne
-
Java:mybatis一级缓存、二级缓存
1、一级缓存:指的是mybatis中sqlSession对象的缓存,当我们执行查询以后,查询的结果会同时存入sqlSession中,再次查询的时候,先去sqlSession中查询,有的话直接拿出,当sqlSession消失时,mybatis的一级缓存也就消失了,当调用sqlSession的修改、添加、删除、commit()、close()等方法时,会清空一级缓存。 2、二级缓存:指的是mybati
-
Spring Boot可缓存-缓存空值
我正在使用注释来缓存我的方法的结果。出于性能原因,我想缓存从方法返回的和非null值。 但是这里的问题是Spring缓存非空值,但由于某种原因没有缓存空值。 这是我的密码: 我什么都试过了。就连我 但这也没什么帮助。有关于这个的指示吗?
-
Spring缓存:驱逐多个缓存
我使用Spring缓存抽象,定义了多个缓存。有时,当数据更改时,我想逐出多个缓存。是否可以使用Spring的CacheExit注释逐出多个缓存?
-
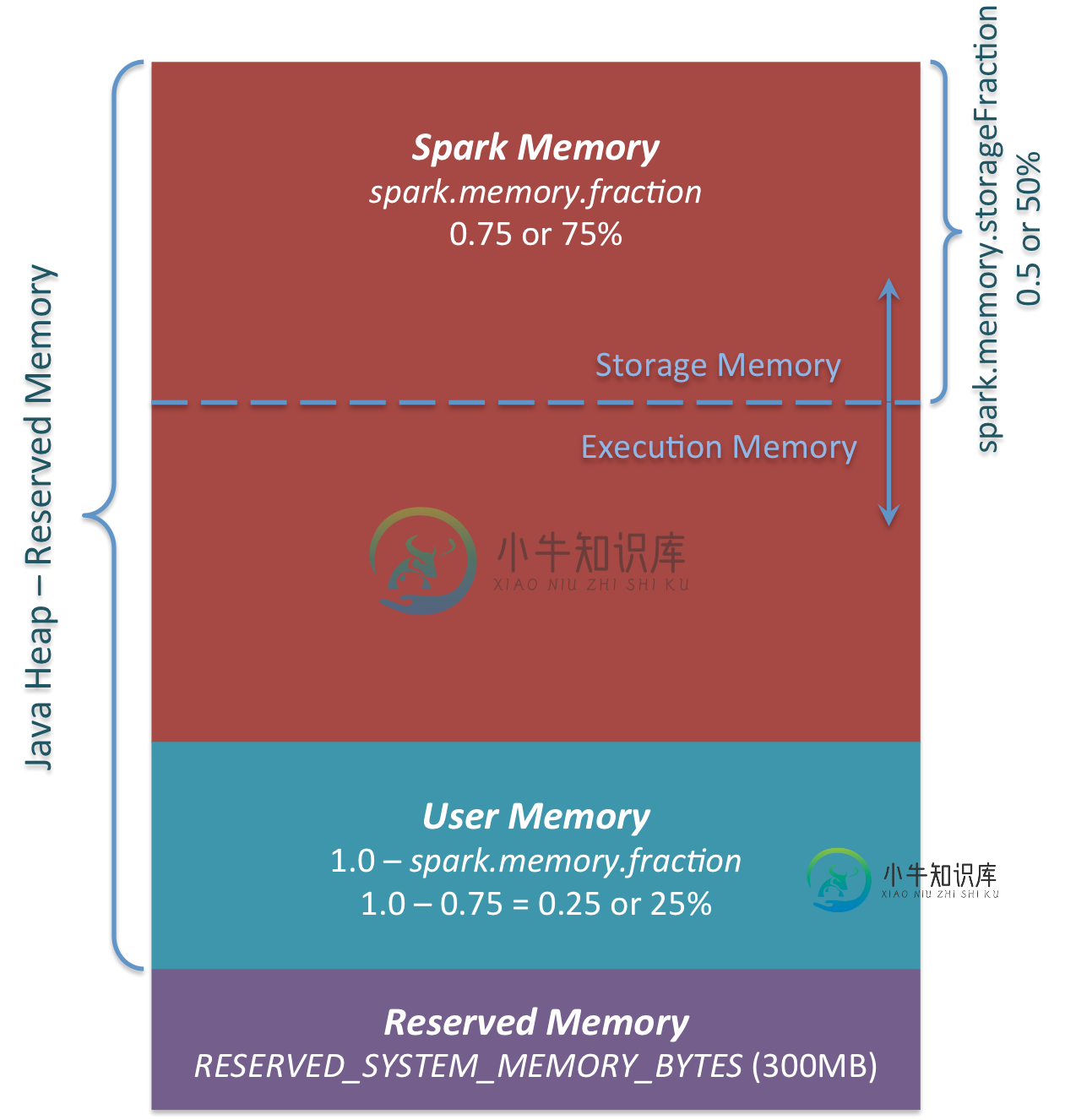 ApacheSpark:用户内存vs Spark内存
ApacheSpark:用户内存vs Spark内存我正在构建一个Spark应用程序,我必须在其中缓存大约15GB的CSV文件。我在这里读到了Spark 1.6中引入的新: https://0x0fff.com/spark-memory-management/ 作者在和之间有所不同(火花内存又分为)。正如我所了解的,Spark内存对于执行(洗牌、排序等)和存储(缓存)东西是灵活的——如果一个需要更多内存,它可以从另一个部分使用它(如果尚未完全使用)
-
WebAPI-Redis缓存vs输出缓存
我一直在研究Redis(完全没有经验,只是研究了理论),在做了一些研究之后,发现它也被用作缓存。例如StackOverfolow it self。 有什么好处吗? 我试图直接浏览这个答案redis-cache-vs-using-memory-,但我想我没有得到答案中的关键行: “基本上,如果您需要您的应用程序在共享相同数据的几个节点上进行扩展,那么将需要类似Redis(或任何其他远程键/值存储)的