
ApacheSpark:用户内存vs Spark内存

我正在构建一个Spark应用程序,我必须在其中缓存大约15GB的CSV文件。我在这里读到了Spark 1.6中引入的新UnifiedMemoryManager:
https://0x0fff.com/spark-memory-management/
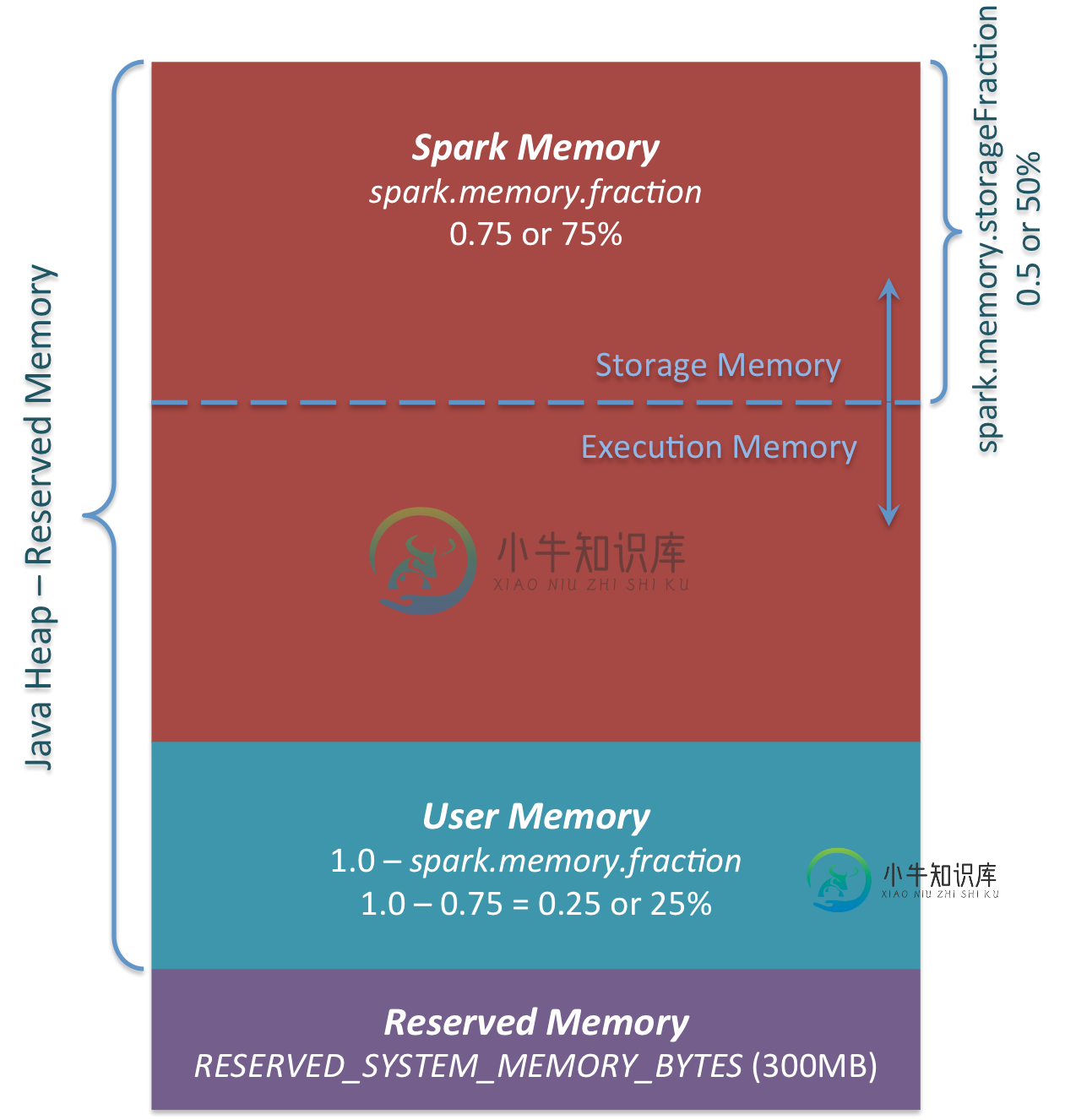
作者在用户内存和火花内存之间有所不同(火花内存又分为存储内存和执行内存)。正如我所了解的,Spark内存对于执行(洗牌、排序等)和存储(缓存)东西是灵活的——如果一个需要更多内存,它可以从另一个部分使用它(如果尚未完全使用)。这个假设正确吗?
用户内存描述如下:
用户内存。这是Spark内存分配后剩下的内存池,完全由你决定以你喜欢的方式使用它。你可以在那里存储你自己的数据结构,这些结构将用于RDD转换。例如,你可以通过使用映射分区转换来重写Spark聚合,为该聚合运行维护哈希表,这将消耗所谓的用户内存。[...]再说一遍,这是用户内存,它完全取决于你将在这个内存中存储什么以及如何存储,Spark完全不考虑你在那里做什么以及你是否尊重这个边界。代码中不尊重此边界可能会导致OOM错误。
我如何访问这部分内存,或者Spark如何管理这部分内存?
为了达到我的目的,我只需要有足够的存储内存(因为我不做类似于shuffle,加入等事情)?那么,我可以将spark.memory.storageFraction属性设置为1.0吗?
对我来说,最重要的问题是,用户内存如何?为什么,尤其是为了我上述的目的?
当我将程序更改为使用一些自己的类时,使用内存是否有区别,例如RDD
下面是我的代码片段(在基准测试应用程序中多次从Livy Client调用它。我使用的是Spark 1.6.2和Kryo序列化。
JavaRDD<String> inputRDD = sc.textFile(inputFile);
// Filter out invalid values
JavaRDD<String> cachedRDD = inputRDD.filter(new Function<String, Boolean>() {
@Override
public Boolean call(String row) throws Exception {
String[] parts = row.split(";");
// Some filtering stuff
return hasFailure;
}
}).persist(StorageLevel.MEMORY_ONLY_SER());
共有1个答案

统一内存管理器
1) 堆上:对象在JVM堆上分配,并由GC绑定。
2) 堆外:对象通过序列化在JVM之外的内存中分配,由应用程序管理,不受GC绑定。这种内存管理方法可以避免频繁的GC,但缺点是必须编写内存分配和内存释放的逻辑。
堆上:
存储内存:主要用于存储Spark缓存数据,如RDD缓存、广播变量、展开数据等。
执行内存/洗牌内存:主要用于存储洗牌、联接、排序、聚合等计算过程中的临时数据。
用户内存:主要用于存储RDD转换操作所需的数据,如RDD依赖关系的信息。
保留内存:内存是为系统保留的,用于存储Spark的内部对象。
堆外内存:-1)存储内存(洗牌内存)2)执行内存
-
问题内容: 我正在尝试打电话 直接,但获得EFAULT错误代码。出现此错误是因为 buf 指向内核空间中的内存。 那么,是否有可能从内核分配用户空间内存? 与 内核内存相似并返回指向内核内存的指针。 问题答案: 您可以使用以下方法临时禁用内存地址有效性检查:
-
问题内容: 我的问题是关于将数据从内核传递到用户空间程序。我想实现一个系统调用“ get_data(size,char * buff,char ** meta_buf)”。在此调用中,buff由用户空间程序分配,并且其长度在size参数中传递。但是,meta_buf是可变长度的缓冲区,已分配(在用户空间程序的vm页面中)并由内核填充。用户空间程序将释放该区域。 (我无法在用户空间中分配数据,因为用
-
【内存占用】页面主要展示项目运行过程中内存的使用情况,主要包括以下几个部分: 数据汇总 该项主要展示项目运行过程中的 “总内存峰值”、“堆内存峰值”、“GFX内存峰值” 和 “泄露风险”。其中,总内存为Unity引擎所统计的真实物理内存分配,并不包含系统缓存和第三方库的自身分配内存; 堆内存所指的是 Mono 管理和分配的托管堆内存; GFX内存为用于渲染的资源所占用的内存,主要包括纹理资源、网格
-
我想了解为什么多次动态分配调用的数据比直接在代码中指定的或通过的单个调用分配的数据使用如此多的内存。 例如,我用C编写了以下两个代码: 测试1.c:int x用malloc分配 我在这里没有使用free来保持简单。当程序等待交互时,我查看另一个终端中的顶级功能,它向我显示了以下内容: test2. c: int x不是动态分配的 顶部显示: 我还编写了第三个代码,其结果与test2相同,我在tes
-
内存 [KNL,BOOT] mem=nn[KMG] 强制指定内核使用多少数量的内存。仅在你想限定内存使用量时,才需要指定这个选项。同时为了避免PCI设备使用指定范围之外的内存,你还应该配合"memmap="一起使用。 [KNL] memmap=exactmap 表示将要使用随后的"memmap=..."等选项进行精确的E820内存映射(因为有时候E820报告的并不准确),同时禁止内核进行任何自动的
-
我是新来的谷歌应用程序引擎,但试图找到我的应用程序消耗多少软内存的真正来源。 我正在标准环境中运行F1实例类(128MB内存限制),尚未出现“软内存超出”错误。 我用来检查内存的工具有: GoogleAppEngine仪表板(内存使用量图表)——显示了过去一周内存使用量从250MB逐渐增加到1GB以上。请参阅下面的第一张图片 GoogleAppEngine仪表板(实例摘要表)-显示122MB的平均