《字节跳动秋招》专题
-
Webkit和jQuery可拖动跳跃
问题内容: 作为实验,我创建了一些div并使用CSS3对其进行了旋转。 然后,我随机设置它们的样式,并使其通过jQuery可拖动。 拖动有效,但我注意到仅在webkit浏览器中拖动div时突然跳了一下,而在Firefox中一切正常。 如果我删除 职位:绝对 风格,那么“跳跃”就更糟了。我以为webkit和gecko之间的转换起源可能有所不同,但是默认情况下它们都位于元素的中心。 我已经搜索过了,但
-
mysqli自动递增跳转数
我遇到了一些问题,从mysql返回的id不正确。我的代码创建了一个集合,然后将从数据库返回的id传递给另一个函数,该函数将项目添加到数据库中,并将集合的id作为参数传递,以建立关系。 问题是一段时间后,从数据库返回的ID不正确 数据库中没有id为数百的集合。我不太确定为什么mysqli返回不存在的错误数字。
-
忽略跳过动作常量
const SKIP_NONE = 0x00; // 不忽略任何单元格、行 const SKIP_EMPTY_ROW = 0x01; // 忽略空行 const SKIP_EMPTY_CELLS = 0x02; // 忽略空单元格(肉眼观察单元格内无数据,并不代表单元格未定义、未使用) const SKIP_EMPTY_VALUE = 0X100; // 忽略单元格空数据
-
 25届大三实习 字节跳动抖音智能创作后端开发实习生一二面面经
25届大三实习 字节跳动抖音智能创作后端开发实习生一二面面经一面面试时长1h20min 1、学习路线和项目选型 2、拷打我的开源分布式项目(25min),master单点故障有考虑吗?如果有请求打到当前worker上了但worker宕机了怎么保证一个处理平滑?....一系列问题很深很杂。问为什么用grpc,grpc一次服务调用中间会经历什么?服务发现怎么做的?负载指标怎么设计的?有监控吗?数据存储的格式是怎么样的?定期拉取更新吗? 3、操作系统进程间通信方
-
字节流和字符流
问题内容: 请解释什么是字节流和字符流。这些到底是什么意思?Microsoft Word文档是面向字节还是面向字符? 谢谢 问题答案: 流是顺序访问文件的一种方式。字节流逐字节访问文件。字节流适用于任何类型的文件,但不适用于文本文件。例如,如果文件使用unicode编码,并且一个字符用两个字节表示,则字节流将分别处理这些字节,您需要自己进行转换。 字符流将逐字符读取文件。必须为字符流提供文件的编码
-
通过套接字Java发送字节数组、字符串和字节
我需要通过Java socket发送一个文本消息到服务器,然后发送一个字节数组,然后是一个字符串等等。到目前为止,我所开发的内容还在工作,但客户端只读取发送的第一个字符串。 从服务器端:我使用发送字节数组,使用发送字符串。 问题是客户机和服务器不同步,我的意思是服务器发送字符串然后字节数组然后字符串,而不等待客户机消耗每个需要的字节。 我的意思是情况不是这样的:
-
从字节数组中删除前16个字节
问题内容: 在Java中,如何获取byte []数组并从数组中删除前16个字节?我知道我可能必须通过将阵列复制到新阵列中来执行此操作。任何例子或帮助将不胜感激。 问题答案: 参见Java库中的类:
-
字节vs字节数组在Python 2.6和3中
问题内容: 我正在Python中测试vs。我不明白某些差异的原因。 一个迭代器返回的字符串: 给出: 但是迭代器返回s: 给出: 为什么会有所不同? 我想编写可以很好地转换为Python 3的代码。那么,Python 3中的情况是否相同? 问题答案: 在Python中,2.6字节只是str的别名 。 引入此“伪类型”是为了(部分地)准备要与Python 3.0转换/兼容的程序(和程序员!),在Py
-
jupyterlab互动情节
问题内容: 我正在使用Jupyter笔记本中的Jupyterlab。在我以前使用的笔记本中: 用于交互式地块。现在给我(在jupyterlab中): 我还尝试了魔术(安装了jupyter-matplotlib): 但这只是返回: 内联图 工作正常,但我想要交互式地块。 问题答案: 完成步骤 1. 安装nodejs,例如。 2. 安装ipympl,例如。 3. [可选,但推荐;更新JupyterLa
-
 23秋招星际悦动群面面经
23秋招星际悦动群面面经牛客没有这家的面经,甚至专区都没有,所以发一下群面的面经啦。 1、群面题目是常规的资源分配问题。 2、整场除自由讨论环节是不需要timer的,有hr在cue流程。 3、自我介绍+个人观点介绍一共是2分钟,有hr计时。所以自我介绍一句话就行,专注于发表观点,不用抢发言,one by one形式。这种形式下整场面试都会变得P&L。 4、群面结束没有问题环节和反问环节,所以在面试中专心于解决问题就
-
 秋招记录-自动驾驶pnc算法
秋招记录-自动驾驶pnc算法从七月初到现在也面了挺多场了,感觉招聘越来越看重对口实习或者对口的论文,也就是希望招进来就能立刻上手,对八股还有coding的考察可能没有那么严格(某几家除外......)。写个面经一方面记录一下秋招,另外也是写写面经攒攒人品。 更新ing 文远知行 具体面经之前发过了,总的来说就是三面挂,coding没写出来,前两面体验还是不错的,面试官人很好,三面只聊了5分钟,后面沉浸式coding写不出来,
-
了解Java字节
问题内容: 因此,在昨天的工作中,我不得不编写一个应用程序来计算AFP文件中的页数。因此,我整理了我的MO:DCA规范PDF,找到了结构化字段及其3个字节的标识符。该应用程序需要在AIX机器上运行,所以我决定用Java编写它。 为了获得最大效率,我决定读取每个结构化字段的前6个字节,然后跳过该字段中的其余字节。这会让我: 因此,我检查字段类型,如果是,则增加页面计数器,如果不是,则不增加。然后,我
-
Concat字节数组
问题内容: 有人可以指出以下更有效的版本吗 每个变量都是一个字节片,大小不一 : 码: : 基准测试结果: 问题答案: 如果已经分配了内存,则x = append(x,a …)的序列在Go中非常有效。 在您的示例中,初始分配(制造)的成本可能比附加序列的成本高。这取决于字段的大小。考虑以下基准: 在我的盒子上,结果是: 系统地重新分配缓冲区(甚至是很小的缓冲区)会使此基准测试速度至少慢5倍。 因此
-
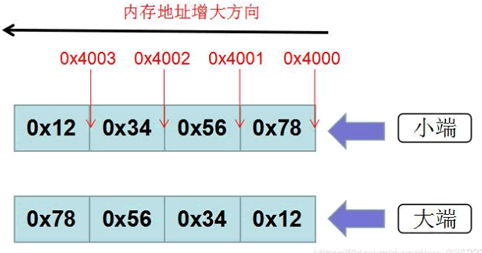 NumPy字节交换
NumPy字节交换主要内容:numpy.ndarray.byteswap()数据以字节的形式存储在计算机内存中,而存储规则可分为两类,即小端字节序与大端字节序。 小端字节序(little-endian),表示低位字节排放在内存的低地址端,高位字节排放在高地址段,它与大端字节序(big-endian)恰好相反。 对于二进制数 0x12345678,假设从地址 0x4000 开始存放,在大端和小端模式下,它们的字节排列顺序,如下所示: 图1:字节存储模式 小端存储后:0x
-
比较字节值?
问题内容: 我很好奇为什么,当我将一个数组与一个值进行比较时… …返回,而… …才不是?是一个数组 问题答案: 比较整数,因为0xFF是整数,此表达式 会将您的字节 扩展为int并将括号内的内容与第二int进行比较。至于你说的是,它将首先被调整为整数且相比于整数,所以这个作品。 将一个字节与int比较: 是一个字节(有符号),其值为。 不等于,因此这就是为什么在比较integer之前必须将data