《交流讨论》专题
-
Spring云流Azure事件中心绑定器中的消息消耗后没有DB提交
我有一个事件侦听器Spring boot应用程序,它执行从Azure事件中心主题读取操作- 我只是遵循了链接eventhubs活页夹示例中的示例。 在@StreamListener注释方法内执行的任何JPA save操作都不会将数据插入DB中。。 非常感谢您的任何提示。。我想我必须对事务同步(KafkaTransactionManager-JPATransactionManager)做些什么,但不
-
如何创建具有交互式通知的Web无线电流的Android前台服务?
我正在尝试构建一个极其简单的广播流应用程序,它存储一个web广播URL列表,可以选择这些URL来流式传输音频;使用服务允许在应用程序未处于活动状态时继续播放,以避免收到通知。 我需要的控件非常简单:播放/暂停和停止,当清除通知或在应用程序中按下停止按钮时,这些控件应该会终止服务并被诱导。 我为大量代码道歉,但这就是我的目的: 这是从谷歌的媒体播放讲座、Android文档、UAMP等示例应用程序和其
-
 交互式经纪人API-执行多笔交易
交互式经纪人API-执行多笔交易我正在尝试为API创建一个程序,一次进行多个交易,然后获取股票价格,然后每隔一段时间重新平衡一次。我使用了一个在线教程来获取一些代码,并做了一些调整。 但是,当我运行代码时,它经常连接,如果我重新启动IB TWS,它会下订单。但是如果我再次运行代码,它就不起作用,或者显示它将连接的任何指示。有人能帮我弄清楚如何保持连接,这样我就可以运行main.java文件,它会执行多个交易,然后结束连接吗?我需
-
Apache Camel:聚合交换完成时完成交换
在我的Apache Camel应用程序中,我有一条非常简单的路线: 也就是说,它从AWS SQS获取消息,以100条为一批进行分组,然后通过HTTP发送到某个地方。 与来自SQS的消息的交换在进入聚合阶段时成功完成,此时将它们从队列中删除。 问题是,聚合的交换可能会出现问题(传递时可能会出错),消息将丢失。我真的希望这些原始交换只有在它们所在的聚合交换也成功完成(传递了一批消息)时才能成功完成(从
-
递归流
问题内容: 我想使用Java 8递归列出计算机上的所有文件。 Java 8提供了一种返回所有文件和目录但不递归的方法。如何使用它来获取完整的文件递归列表(不使用变异集合)? 我尝试了下面的代码,但仅深入了一层: 而且使用不会编译(不确定原因)… 注意:我对涉及FileVisitors或外部库的解决方案不感兴趣。 问题答案: 通过递归遍历文件系统生成路径路径流的新API是。 如果您真的想递归地生成流
-
流和parallelStream
问题内容: 我有这样的测试代码: 运行此命令,我得到了正确的输出:1000000。 但是,如果我将更改为,则如下所示: 我得到了一个随机输出,例如:920821。 怎么了? 问题答案: An 未同步。没有定义尝试同时向其添加元素。来自: 对于并行流管道,此操作不能保证尊重流的遇到顺序,因为这样做会牺牲并行性的好处。 对于任何给定的元素,可以在库选择的任何时间和线程中执行该操作 。 在第二个示例中,
-
system.reactive 节流
本文向大家介绍system.reactive 节流,包括了system.reactive 节流的使用技巧和注意事项,需要的朋友参考一下 示例 假设您需要实现一个自动搜索框,但是搜索操作的成本较高,例如发送Web请求或建立数据库。您可能想限制搜索的数量。 例如,用户在搜索框中输入“ C#Reactive Extensions”: 现在,我们不想在用户每次按键时都执行搜索。取而代之的是,只要用户停止输
-
Xamarin.Forms NavigationPage流
本文向大家介绍Xamarin.Forms NavigationPage流,包括了Xamarin.Forms NavigationPage流的使用技巧和注意事项,需要的朋友参考一下 示例
-
流定义
问题内容: 我正在阅读Java I / O流,但对与之关联的正确定义感到困惑。 有人说流是一种传输数据的传送带… 有人说流是数据流或数据序列… 有人说流是到输入或输出源的连接… 那么正确的定义是什么? 问题答案: 流是一个概念,但并不是那么严格,只有一个描述是正确的。 I / O流 代表 输入源或输出目的地。流可以表示许多不同种类的源和目标,包括磁盘文件,设备,其他程序和内存阵列。流 支持 许多不
-
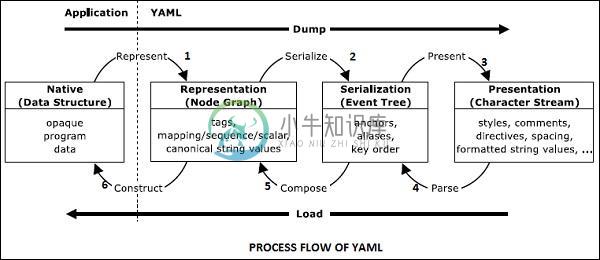 YAML流程
YAML流程主要内容:表示,序列化,表示,解析YAML遵循流程的标准程序。YAML中的本机数据结构包括简单表示,例如:节点。 它也称为表示节点图。 它包括映射,序列和标量,正在序列化以创建序列化树。通过序列化,对象将使用字节流进行转换。 序列化事件树有助于创建字符流的表示,反向过程将字节流解析为序列化事件树。 之后节点将转换为节点图。之后在YAML本机数据结构中转换这些值。 如下图解释 - YAML中的信息以两种方式使用:机器处理和人类消费。
-
数据流
严格的单向数据流是 Redux 架构的设计核心。 这意味着应用中所有的数据都遵循相同的生命周期,这样可以让应用变得更加可预测且容易理解。同时也鼓励做数据范式化,这样可以避免使用多个且独立的无法相互引用的重复数据。 如果这些理由还不足以令你信服,读一下 动机 和 Flux 案例,这里面有更加详细的单向数据流优势分析。虽然 Redux 不是严格意义上的 Flux,但它们有共同的设计思想。 Redux
-
张量流
我试图在张量流图中使用条件随机场损失。 我正在执行序列标记任务: 我有一系列元素作为输入。每个元素可以属于三个不同类中的一个。类以一种热编码方式表示:属于类0的元素由向量[表示。 我的输入标签(y)有大小(xx)。 我的网络产生相同形状的日志。 假设我所有的序列都有长度4。 这是我的代码: 我得到以下错误: 文件“/usr/local/lib/python2.7/dist-packages/ten
-
角HttpClient流
-
Redis流NOMKSTREAM
在redis stream中这是什么?我查阅了文件。可惜的是,他们连简单的描述都没有。 https://redis.io/commands/xadd 有人能解释一下吗?
-
Python,tweepy流
我使用的代码类似于下面的代码,来自:https://github.com/tweepy/tweepy/blob/master/examples/streaming.py 该API允许您跟踪多个过滤器术语,在本例中track=['usa','canada']。这基本上意味着该流将收集提到“加拿大”或“美国”的推文。 问题是函数on_data()打印数据,但是它没有指定数据属于哪个过滤条件。当您只按一