《贝壳找房》专题
-
Swift数组分配不一致(不是引用还是深拷贝)是有原因的吗?
问题内容: 我正在阅读文档,并且在语言的一些设计决策中不断摇头。但是真正让我感到困惑的是如何处理数组。 我冲到操场上,尝试了一下。您也可以尝试。所以第一个例子: 这里和都是,我都可以接受。引用了数组-确定! 现在看这个例子: 是BUT 的。也就是说,在上一个示例中看到了更改,但在此示例中没有看到它。文档说那是因为长度改变了。 现在,这个呢? 是,这很酷。拥有多索引替换很不错,但是即使长度没有变化,
-
如何制作复杂列表的完全不共享的副本?(深拷贝还不够)
问题内容: 看一下下面的Python代码: 请注意,修改其中的一个元素如何在各处进行修改。也就是说,如果附加到,它也会附加到。我猜这是因为Python巧妙地为和 引用 了 同一对象 。(那是他们的 id() 相同。) __ 问题: 是否可以做一些事情,以便可以安全地在本地修改其列表元素?上面仅是一个示例,我的实际问题列表更加复杂,但存在类似的问题。 (对上面格式不正确的问题深表歉意。Python专
-
如何设置贝宝沙盒“卖家”帐户、“买家”帐户和应用程序教程
我正在尝试建立一个使用贝宝的网站。不幸的是,PayPal开发者站点/概念发生了重大变化,所以我发现的所有教程似乎都没有用。例如,这个(非常好的)youtube教程,它是非常清楚的使用不是现有的页面和功能... 所以请尝试帮助我只与最新的信息/教程。 请注意,我的问题不是关于使用API,而是关于如何设置一个应用程序,以及一个从地面测试沙箱配置。 1)据我所知,我必须有一个真正的PayPal帐户,因为
-
最佳实践 - 不要将大型 RDD 的所有元素拷贝到请求驱动者
如果你的驱动机器(submit 请求的机器)内存容量不能容纳一个大型 RDD 里面的所有数据,不要做以下操作: val values = myVeryLargeRDD.collect() Collect 操作会试图将 RDD 里面的每一条数据复制到驱动机器(submit 请求的机器)上,这时候会发生内存溢出和崩溃。 相反,你可以调用 take 或者 takeSample 来确保数据大小的上限。或
-
Android编程实现将压缩数据库文件拷贝到安装目录的方法
本文向大家介绍Android编程实现将压缩数据库文件拷贝到安装目录的方法,包括了Android编程实现将压缩数据库文件拷贝到安装目录的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Android编程实现将压缩数据库文件拷贝到安装目录的方法。分享给大家供大家参考,具体如下: 希望本文所述对大家Android程序设计有所帮助。
-
NPM启动(或纱线启动)错误与巴贝尔创建反应应用程序时
我正在试着写这篇文章,在我设置包的时候使用react计算器。带有提供了更多详细信息,错误消息显示在此处。 max@DESKTOP-4J1U771 MINGW64~/Documents/react计算器(主)$纱线开始纱线运行v1。7.0警告包。json:没有许可证字段$babel节点/服务器/服务器。js C:\Users\max\Documents\react calculator\node\u
-
BN层的作用,为什么要在后面加伽马和贝塔,不加可以吗
本文向大家介绍BN层的作用,为什么要在后面加伽马和贝塔,不加可以吗相关面试题,主要包含被问及BN层的作用,为什么要在后面加伽马和贝塔,不加可以吗时的应答技巧和注意事项,需要的朋友参考一下 参考回答: BN层的作用是把一个batch内的所有数据,从不规范的分布拉到正态分布。这样做的好处是使得数据能够分布在激活函数的敏感区域,敏感区域即为梯度较大的区域,因此在反向传播的时候能够较快反馈误差传播。
-
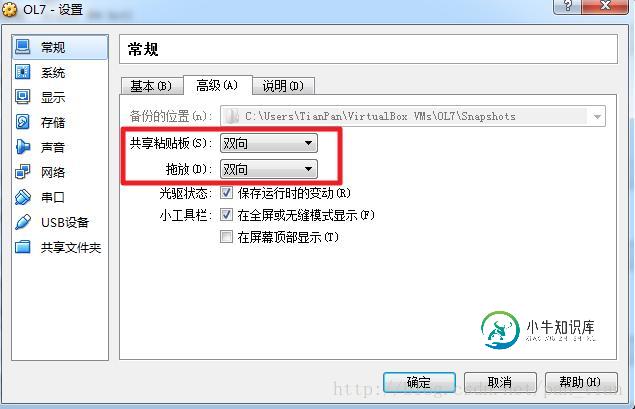 Virtualbox主机和虚拟机之间文件夹共享及双向拷贝(Windows<->Windows, Windows<->Linux)
Virtualbox主机和虚拟机之间文件夹共享及双向拷贝(Windows<->Windows, Windows<->Linux)本文向大家介绍Virtualbox主机和虚拟机之间文件夹共享及双向拷贝(Windows<->Windows, Windows<->Linux),包括了Virtualbox主机和虚拟机之间文件夹共享及双向拷贝(Windows<->Windows, Windows<->Linux)的使用技巧和注意事项,需要的朋友参考一下 最近学习Virtualbox的一些知识,记录下,Virtualbox下如何实现主
-
如何在stanford分类器中使用朴素贝叶斯分类器、SVM和最大熵
目前,我正在用朴素贝叶斯算法、支持向量机和最大熵做一个引文句分类器,目前我的数据是110个非引文句和10个引文句。我用代码从斯坦福分类器的例子中进行分类,结果很好。但是分类器是拟牛顿的。如何使用朴素贝叶斯分类器、支持向量机和最大熵?我已经尝试编辑道具文件并添加“usenb=true”,但结果发现所有数据都是非引用语句类的。我已经在http://nlp.stanford.edu/nlp/javado
-
Item 41 : 对于那些可移动总是被拷贝的形参使用传值方式
对于C++中的通用技术,总是存在适用场景。除了本章覆盖的两个例外,描述什么场景使用哪种通用技术通常来说很容易。这两个例外是传值(pass by value)和 emplacement。决定何时使用这两种技术受到多种因素的影响,本书提供的最佳建议是在使用它们的同时仔细考虑清楚,尽管它们都是高效的现代C++编程的重要角色。接下来的Items提供了是否使用它们来编写软件的所需信息。 Item41.Con
-
房间+找不到实现DB+DB_Impl不存在
我在运行应用程序时得到以下错误 我的build.gradle有以下配置: 有人尝试使用androidX API吗?有人能帮忙找到解决办法吗?
-
tensorflow和火炬。cuda可以找到GPU,但只有Keras找不到
我试过如何检查keras是否使用了tensorflow的gpu版本?答复但我只认出keras没有看到GPU。 我重新安装了整个需求,包括tensorflow gpu、keras模块,甚至CUDA。 我用的是Jupyter remote ipython。 下面的列表是我安装的模块版本 我检查了以下内容: 结果: =============已添加========== 此外,我还了解了如何从python
-
什么是C ++中的“依赖于参数的查找”(“ Koenig查找”)?
本文向大家介绍什么是C ++中的“依赖于参数的查找”(“ Koenig查找”)?,包括了什么是C ++中的“依赖于参数的查找”(“ Koenig查找”)?的使用技巧和注意事项,需要的朋友参考一下 依赖参数的查找(ADL)是一种用于在函数调用表达式中查找不合格函数名称的协议。 这些函数调用表达式包括对重载运算符的隐式函数调用。 除了通常的非限定名称查找所考虑的范围和命名空间之外,还在其参数的命名空间
-
为什么Curl/OpenSSL不能找到Chrome+Firefox能找到的网站?
-
在编译CUDA时既找不到.cubin也找不到.ptx文件
我正在使用Visual Studio2013进行CUDA(7.0)项目。该项目为64bit。我正在使用驱动程序API,需要从ptx或cubin文件加载模块。但我找不到文件。在VS I go properties->cuda C/C++->common->nvcc编译类型中,将其更改为-cubin或ptx。编译器完成ok但我找不到那个文件。我只能在output debug目录中看到kernel.cu