《贝壳》专题
-
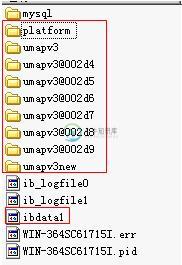 mysql 通过拷贝数据文件的方式进行数据库迁移实例
mysql 通过拷贝数据文件的方式进行数据库迁移实例本文向大家介绍mysql 通过拷贝数据文件的方式进行数据库迁移实例,包括了mysql 通过拷贝数据文件的方式进行数据库迁移实例的使用技巧和注意事项,需要的朋友参考一下 mysql通过拷贝数据文件的方式进行数据库迁移 --环境windows 将源机器A数据库拷贝到目标机器B: 我先在目标机器B上安装MySQL,停止mysql服务,然后将源机器A的data下关于数据库的文件和ibdata1拷贝过去,其
-
C#中序列化实现深拷贝,实现DataGridView初始化刷新的方法
本文向大家介绍C#中序列化实现深拷贝,实现DataGridView初始化刷新的方法,包括了C#中序列化实现深拷贝,实现DataGridView初始化刷新的方法的使用技巧和注意事项,需要的朋友参考一下 winfrom中DataGridView在的单元格在编辑时候会修改它的数据源的,如果我们遇到这样一种情景,刷新数据源到原始状态,这个时候要么数据源的重新获取绑定,要么通过拷贝一份原始档的数据再绑定处理
-
Kubernetes (迷你库贝) pod OOM 杀戮,显然节点中留下了大量内存
我正在使用迷你库贝,从 对于节点的 8Gb 内存。我正在分配具有资源约束的 Pod 因此,每个节点都有256Mb的RAM,这将给我,我假设,在达到8Gb内存限制之前,会有32个pod,但问题是,每当我到达要部署的第8个pod时,第9个永远不会运行,因为它不断被OOMKilled。 对于上下文,每个pod都是一个Java的应用程序,使用frolvlad/alpian-oraclejdk8: Slim
-
强化学习:基本概念,马尔可夫,贝尔曼方程,动态规划
在机器学习范畴内,根据反馈的不同,学习技术可以分为监督学习、非监督学习和强化学习三大类。强化学习是处于完全监督和完全缺乏预定义标签之间,又称为增强学习、加强学习和激励学习,是一种从环境状态到行为映射的学习,目的是使动作从环境中获得的累计回报(奖励)值最大。强化学习主要是智能体(Agent)与环境(Environment)的交互过程。强化学习有一个很大的优势,它可能是超越人类的。监督学习中,比如分类问题,最好的结果就是人类的标注水平,这是一个上界。
-
最好的开源Java贝叶斯垃圾邮件过滤器库是什么?[关闭]
问题内容: 在的其他答案中,有人建议说Weka很好,但还有其他一些(Classifier4j,jBNC,Naiban)。 有人在这些方面有实际经验吗? 问题答案: Weka很棒,但是Classifier4J可能更接近您想要的东西,因为它更着眼于文本识别。
-
使用Weka J48和朴素贝叶斯多项式分类器改进分类结果
我一直在使用Weka的J48和Naive Bayes多项式(NBM)分类器对RSS提要中的关键字频率进行分类,以将提要分类为目标类别。 例如,我的一个。arff文件包含以下数据提取: 以此类推:总共有570行,每行都包含一天的提要中关键字的频率。在这种情况下,10天内有57条feed,总共有570条记录需要分类。每个关键字都以代理项编号作为前缀,并以“频率”作为后缀。 我在“黑盒”的基础上对J48
-
一篇文章读懂拿了图灵奖和诺贝尔奖的概率图模型
首先我们说说什么是图论 能点进这篇文章说明你一定是有一定数学基础的,所以我做个比喻,你来看看是不是这么回事。糖葫芦吃过吧?几个山楂串在一根杆上,这其实就是一个图。 稍稍正式一点说:图就是把一些孤立的点用线连起来,任何点之间都有可能连着。它区别于树,树是有父子关系,图没有。 再深入一点点:从质上来说,图可以表达的某些事物之间的关联关系,也可以表达的是一种转化关系;从量上来说,它能表达出关联程度,也能
-
前端 - vue3怎么深拷贝ref和reactive对象让其保持 响应式属性?
vue3怎么深拷贝ref和reactive对象让其保持 响应式属性? 因为用json.parse(json.stringify())的话会使其失去响应式
-
Swift数组分配不一致(不是引用还是深拷贝)是有原因的吗?
问题内容: 我正在阅读文档,并且在语言的一些设计决策中不断摇头。但是真正让我感到困惑的是如何处理数组。 我冲到操场上,尝试了一下。您也可以尝试。所以第一个例子: 这里和都是,我都可以接受。引用了数组-确定! 现在看这个例子: 是BUT 的。也就是说,在上一个示例中看到了更改,但在此示例中没有看到它。文档说那是因为长度改变了。 现在,这个呢? 是,这很酷。拥有多索引替换很不错,但是即使长度没有变化,
-
如何制作复杂列表的完全不共享的副本?(深拷贝还不够)
问题内容: 看一下下面的Python代码: 请注意,修改其中的一个元素如何在各处进行修改。也就是说,如果附加到,它也会附加到。我猜这是因为Python巧妙地为和 引用 了 同一对象 。(那是他们的 id() 相同。) __ 问题: 是否可以做一些事情,以便可以安全地在本地修改其列表元素?上面仅是一个示例,我的实际问题列表更加复杂,但存在类似的问题。 (对上面格式不正确的问题深表歉意。Python专
-
如何设置贝宝沙盒“卖家”帐户、“买家”帐户和应用程序教程
我正在尝试建立一个使用贝宝的网站。不幸的是,PayPal开发者站点/概念发生了重大变化,所以我发现的所有教程似乎都没有用。例如,这个(非常好的)youtube教程,它是非常清楚的使用不是现有的页面和功能... 所以请尝试帮助我只与最新的信息/教程。 请注意,我的问题不是关于使用API,而是关于如何设置一个应用程序,以及一个从地面测试沙箱配置。 1)据我所知,我必须有一个真正的PayPal帐户,因为
-
最佳实践 - 不要将大型 RDD 的所有元素拷贝到请求驱动者
如果你的驱动机器(submit 请求的机器)内存容量不能容纳一个大型 RDD 里面的所有数据,不要做以下操作: val values = myVeryLargeRDD.collect() Collect 操作会试图将 RDD 里面的每一条数据复制到驱动机器(submit 请求的机器)上,这时候会发生内存溢出和崩溃。 相反,你可以调用 take 或者 takeSample 来确保数据大小的上限。或
-
Android编程实现将压缩数据库文件拷贝到安装目录的方法
本文向大家介绍Android编程实现将压缩数据库文件拷贝到安装目录的方法,包括了Android编程实现将压缩数据库文件拷贝到安装目录的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Android编程实现将压缩数据库文件拷贝到安装目录的方法。分享给大家供大家参考,具体如下: 希望本文所述对大家Android程序设计有所帮助。
-
NPM启动(或纱线启动)错误与巴贝尔创建反应应用程序时
我正在试着写这篇文章,在我设置包的时候使用react计算器。带有提供了更多详细信息,错误消息显示在此处。 max@DESKTOP-4J1U771 MINGW64~/Documents/react计算器(主)$纱线开始纱线运行v1。7.0警告包。json:没有许可证字段$babel节点/服务器/服务器。js C:\Users\max\Documents\react calculator\node\u
-
BN层的作用,为什么要在后面加伽马和贝塔,不加可以吗
本文向大家介绍BN层的作用,为什么要在后面加伽马和贝塔,不加可以吗相关面试题,主要包含被问及BN层的作用,为什么要在后面加伽马和贝塔,不加可以吗时的应答技巧和注意事项,需要的朋友参考一下 参考回答: BN层的作用是把一个batch内的所有数据,从不规范的分布拉到正态分布。这样做的好处是使得数据能够分布在激活函数的敏感区域,敏感区域即为梯度较大的区域,因此在反向传播的时候能够较快反馈误差传播。