《贝壳》专题
-
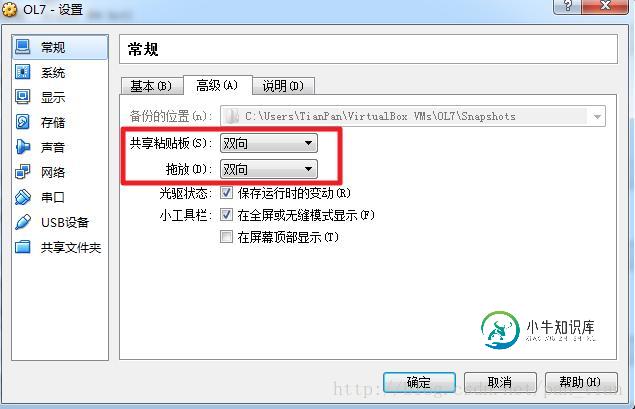 Virtualbox主机和虚拟机之间文件夹共享及双向拷贝(Windows<->Windows, Windows<->Linux)
Virtualbox主机和虚拟机之间文件夹共享及双向拷贝(Windows<->Windows, Windows<->Linux)本文向大家介绍Virtualbox主机和虚拟机之间文件夹共享及双向拷贝(Windows<->Windows, Windows<->Linux),包括了Virtualbox主机和虚拟机之间文件夹共享及双向拷贝(Windows<->Windows, Windows<->Linux)的使用技巧和注意事项,需要的朋友参考一下 最近学习Virtualbox的一些知识,记录下,Virtualbox下如何实现主
-
如何在stanford分类器中使用朴素贝叶斯分类器、SVM和最大熵
目前,我正在用朴素贝叶斯算法、支持向量机和最大熵做一个引文句分类器,目前我的数据是110个非引文句和10个引文句。我用代码从斯坦福分类器的例子中进行分类,结果很好。但是分类器是拟牛顿的。如何使用朴素贝叶斯分类器、支持向量机和最大熵?我已经尝试编辑道具文件并添加“usenb=true”,但结果发现所有数据都是非引用语句类的。我已经在http://nlp.stanford.edu/nlp/javado
-
Item 41 : 对于那些可移动总是被拷贝的形参使用传值方式
对于C++中的通用技术,总是存在适用场景。除了本章覆盖的两个例外,描述什么场景使用哪种通用技术通常来说很容易。这两个例外是传值(pass by value)和 emplacement。决定何时使用这两种技术受到多种因素的影响,本书提供的最佳建议是在使用它们的同时仔细考虑清楚,尽管它们都是高效的现代C++编程的重要角色。接下来的Items提供了是否使用它们来编写软件的所需信息。 Item41.Con
-
如何在使用minimax算法实现2048 AI代理时应用阿尔法-贝塔修剪?
我正在为2048年开发一个人工智能,并且即将应用极大极小算法。 然而,2048的搜索树实际上就像一棵没有民角色的期望极小树。我想知道如果我没有民角色,我怎么能在实践中应用α-β剪枝? 如果我不应该在这个场景中应用alpha-beta修剪,我怎么能减少无用的搜索分支? 任何想法将不胜感激。谢谢你。
-
如果消费者(库贝pod)重新启动,则Spring云流手动偏移提交行为
嗨,我们一直在使用旧的spring版本和kafka 1.1,并有以下依赖项 我在应用程序中有以下配置。yaml文件 我在stackoverflow中找到了链接。答案有 首先,我不确定您对SpringApplication.ext(applicationContext,())的期望是什么- 这是否意味着Kafka不知道消费者已关闭,在这种情况下没有来自消费者的通信。我认为会发生重新平衡,此外,由于k
-
库伯内特斯在米尼库贝用“需要杀死吊舱”重新启动Statefolset吊舱
迷你库版本v0.24.1 kubernetes 1.8.0版 我面临的问题是,我在minikube中创建了几个,每个都有一个pod。 有时,当我启动minikube时,我的吊舱会先启动,然后由kubernetes重新启动。它们将一次又一次地从创建容器状态到运行状态,再到终止状态。 现在,我已经看到kubernetes杀死和重启的东西之前,如果kubernetes检测到磁盘压力,内存压力,或其他类似
-
赛贝斯ASE到HSQLDB JUnitjava.sql.SQLSyn的错误异常:未找到类型或用户缺乏特权
在我继承的一个项目中,有一个准备好的语句,定义为: 此SQL语句在运行时使用数据库时工作正常。 但是执行它的JUnit(作为构建的一部分)一直失败 我将此错误跟踪到 CASE THEN 转换语句: 即下面的预准备语句,不会产生所述错误: 我怀疑这可能与有关,我遇到了这个SO答案,它表明要使用非HSQLDB方言运行HSQLDB,必须首先在HSQLDB上启用该语法兼容模式。 在这个SO答案中发现了类似
-
我如何检查我的库贝上有什么入口控制器,默认的是什么
谢谢:)
-
操作方法:访问本地迷你库贝集群,并在 VSCode 开发容器内运行?
我有一个在 Windows WSL2 上运行的迷你库贝集群,我有一个开发容器 https://code.visualstudio.com/docs/remote/create-dev-container)运行我的 React 应用程序和 Kubernetes CLI 工具。我的目标是容器化应用程序并在 minikube 集群上运行它。 所以现在我已经向我的Dev容器公开了minikube的本地配置
-
如何在CRI-O上运行的迷你库贝中加载本地多克程序映像?
要在 Docker 容器运行时上运行的 Minikube 中构建和运行 Docker 映像,我所要做的就是: 迷你库贝会找到图像。 但是如果我在cri-o模式下运行Minikube,这并不起作用,正如预期的那样。有没有办法加载本地Docker映像并使用它?理论上,任何符合OCI的容器映像都应该有效? 另外,如果有必要的话,我在苹果电脑上。
-
在Haskell中使用GNU / Linux系统调用`splice`进行零拷贝Socket到Socket的数据传输
问题内容: 更新:尼莫先生的回答帮助解决了这个问题! 下面的代码包含修复程序!请参见下面的和呼叫。 还有一个称为的新Haskell软件包(具有最著名的套接字到套接字数据传输循环的特定于操作系统的可移植实现) 。 我有以下(Haskell)代码: 注意: 上面的代码现在 可以正常使用! 感谢Nemo,下方不再有效! 我按照上面的定义使用两个开放和连接的套接字进行调用(已经使用套接字API 和调用将它
-
python检测文件夹变化,并拷贝有更新的文件到对应目录的方法
本文向大家介绍python检测文件夹变化,并拷贝有更新的文件到对应目录的方法,包括了python检测文件夹变化,并拷贝有更新的文件到对应目录的方法的使用技巧和注意事项,需要的朋友参考一下 检测文件夹,拷贝有更新的文件到对应目录 2016.5.19 亲测可用,若有借鉴请修改下文件路径; 学习python小一个月后写的这个功能,属于初学,若有大神路过,求代码优化~ newcopy.py: 检测文件夹中
-
使用scikit-learn在朴素贝叶斯分类器中混合分类数据和连续数据
问题内容: 我正在Python中使用scikit-learn开发分类算法,以预测某些客户的性别。除其他外,我想使用Naive Bayes分类器,但是我的问题是我混合使用了分类数据(例如:“在线注册”,“接受电子邮件通知”等)和连续数据(例如:“年龄”,“长度”成员资格”等)。我以前没有使用过scikit,但我想高斯朴素贝叶斯适用于连续数据,而伯努利朴素贝叶斯可以用于分类数据。但是,由于我想在模型中
-
赛贝斯ASE BulkCopy"不支持数据类型或函数"写入非空用户定义类型
我在将从Sql Server迁移到ASE(v16.0)中具有用户定义类型的的列时遇到问题。 我有简单的用户定义类型: 这在一个小表中使用: 我正在尝试使用。源值在SqlServer中定义为。我使用. net客户端进行ASE,我的应用程序代码是C#:
-
朴素贝叶斯算法和非结构化文本 - 非结构化文本的分类算法
在前几个章节中,我们学习了如何使用人们对物品的评价(五星、顶和踩)来进行推荐;还使用了他们的隐式评价——买过什么,点击过什么;我们利用特征来进行分类,如身高、体重、对法案的投票等。这些数据有一个共性——能用表格来展现: 因此这类数据我们称为“结构化数据”——数据集中的每条数据(上表中的一行)由多个特征进行描述(上表中的列)。而非结构化的数据指的是诸如电子邮件文本、推特信息、博客、新闻等。这些数据至