《阿里lazada》专题
-
python3中波斯语或阿拉伯语的unicode和编码
问题内容: 像这样的一些代码块: 此代码的输出是: 如果我删除了encode(’utf-8’)输出更改,如下所示: 这种输出语言是波斯语(像阿拉伯语),我想知道为什么python3中的字符串类没有任何解码方法?您对此问题有解决方案吗? 谢谢 问题答案: 好的,我找到了解决方案,它的运行就像一个魅力 更新:ZSH脚本环境中的此问题,我使用bash,一切都找到了。
-
阿帕奇卡拉夫洞穴不工作与保险丝
我已经安装了cave-repository来融合,然后我创建了一个新的存储库。当我试图通过http访问repository时,我从Undertow收到以下错误。 注意:我没有改变底拖设置。它是一个默认的保险丝包。 java.lang.ILLegalStateException:UT010026:此请求不支持Async,因为并非所有筛选器或servlet都标记为支持Async。handleReque
-
组织。阿帕奇。Kafka。常见的错误。超时异常
我有两个代理1.0.0Kafka集群,我正在针对这个Kafka运行1.0.0Kafka流API应用程序。我增加了制片人的要求。暂停。毫秒到5分钟来修复生产者超时异常。 目前,在运行一段时间后,我发现以下两种类型的异常。我试图按照ApacheKafka中的建议修复这些异常:TimeoutException,然后什么都不起作用 但不完整的解决方案就在这里。建议使用此解决方案(减少生产批量)。请帮忙。
-
阿帕奇。平民配置无法从URL加载配置
对于我正在处理的项目,我需要在运行时更改一些属性值并保存它们。在寻找解决方案时,我找到了apache commons配置。 我已经研究了一些其他主题来解决我的第一个问题,但现在,一个错误是: <代码>组织。阿帕奇。平民配置配置异常:无法从URL文件加载配置:/C:/Users/sensor/Documents/NetBeansProjects/HermanWijn/dist/run17766770
-
我不能让滑动手势在阿皮亚使用Java
我不能让刷卡动作起作用。我在网上浏览了几天,发现了许多类似的问题,但没有有效的答案。我也试过TouchAction类,不工作以及。 我有Appium版本1.4.13(Draco),并使用Java、TestNG框架。 顺便说一句,我使用(您可以使用与拉刷新相同的逻辑)实现了滚动,下面是代码示例。
-
HDFS、HBase、猪、蜂巢和阿兹卡班之间的关系?
我对Apache Hadoop有些陌生。我已经看到了关于Hadoop、HBase、Pig、Hive和HDFS的这个和这个问题。两者都描述了上述技术之间的比较。 但是,我已经看到,Hadoop环境通常包含所有这些组件(HDFS、HBase、Pig、Hive、Azkaban)。 有人能以架构工作流的方式解释那些组件/技术与其在Hadoop环境中的职责之间的关系吗?最好是举个例子?
-
无法在PDF-PDFBox Java中保存阿拉伯语单词
试图将阿拉伯语单词保存在可编辑的PDF中。它在英语单词中都很好用,但当我使用阿拉伯语单词时,我得到了一个例外:
-
使用stanford词性标记器的阿拉伯语标记
我是完全新的NLP的世界,我需要你的帮助开始标记阿拉伯语句子使用漂亮的斯坦福pos标签。 我已经安装了一个完整的版本,其中包含两个阿拉伯语培训的标签。 请指导我使用java和eclipse在阿拉伯语中应用此标记器, 我应该导入什么? 我该给模特们加些什么 处理阿拉伯语的函数和库 即使它不在训练集中,这个标记器也能给出正确的标记吗? 事实上,我已经浏览了斯坦福大学的官方网站,但它没有那么大的帮助 先
-
使用 MLib 的阿帕奇火花中的分类变量
我对Apache Spark的世界比较陌生。我正在尝试使用LinearRegressionWithSGD()来估计一个大规模模型,我希望在不需要创建庞大的设计矩阵的情况下估计固定效果和交互项。 我注意到在决策树中有一个支持分类变量的实现 https://github.com/apache/spark/blob/master/mllib/src/main/scala/org/apache/spark
-
如何检索 pptx 幻灯片名称与阿帕奇 poi
Powerpoint幻灯片具有可通过VBA访问和修改的内部名称。参见例如Powerpoint:手动设置幻灯片名称 我想通过apache poi访问该名称。我尝试了: 但只有当幻灯片名称只有默认名称时,才以这种方式获取空字符串。 在阿帕奇POI中获取(甚至设置)pptx文件的幻灯片名称的正确方法是什么?
-
 ExoPlayer-奇怪的阿拉伯语/波斯语字幕格式
ExoPlayer-奇怪的阿拉伯语/波斯语字幕格式我正在尝试创建一个带有字幕的视频播放器。除了一件事,一切都设置好了,工作正常。我的阿拉伯语字幕显示不正确。他们用符号之类的东西看起来很奇怪。。比如: 以下是我的ExoPlayer设置和子倾斜: 有什么解决办法吗?
-
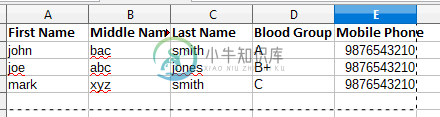 使用标题读取Excel文件阿帕奇POI Spring Boot
使用标题读取Excel文件阿帕奇POI Spring Boot如何使用标题读取Excel文件(xlsx)阿帕奇POI,Spring Boot!!!。我知道我们可以使用行迭代器和单元格迭代器来读取。我想用标题阅读。 这就是我使用行迭代器和单元格迭代器读取xlsx文件的方式 但是如何使用标题阅读? 法典: 参考 1 的图像: 参考图片2:
-
从Kafka到另一个Kafka的阿帕奇骆驼之路
我正在使用Apache Camel使用来自kafka主题的消息,然后处理该消息,同时处理如果发生异常,我将该消息重定向到另一个kafka主题,并以单独的路由处理该消息。所以我有一个如下所示的路线。 上面的代码实际上是以相同的kafka(kafka1)发送错误消息。 我通过在进程中设置解决了这一问题。这是预期的行为吗?它为什么忽略kafka2而使用kafka1? > 使用的 版本的camel-2.1
-
在PDF iText中得到错误的阿拉伯语翻译
我正在从我的超文本标记语言字符串生成PDF文件,但当生成PDF文件时,超文本标记语言和PDF中的内容不匹配。内容是PDF是一些随机内容。我在谷歌上读到过这个问题,他们建议使用Unicode表示法,如。但我正在将其放入我的超文本标记语言中,它正在按原样打印。 相关问题:使用itext在pdf中编写阿拉伯语
-
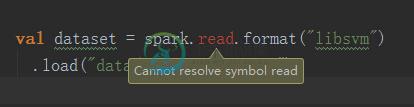 value read不是组织的成员。阿帕奇。火花SparkContext
value read不是组织的成员。阿帕奇。火花SparkContextscala的版本是2.11.8;jdk为1.8;spark是2.0.2 我试图在spark apache的官方网站上运行一个LDA模型的示例,我从以下句子中得到了错误消息: 错误按摩是: 错误:(49,25)读取的值不是组织的成员。阿帕奇。火花SparkContext val dataset=spark。阅读格式(“libsvm”)^ 我不知道怎么解决。