《高途》专题
-
获取Android中的屏幕高度
在Android系统中如何获得屏幕的可用高度?我需要的高度减去状态栏/菜单栏或任何其他可能在屏幕上的装饰,我需要它为所有设备工作。另外,我需要在onCreate函数中了解这一点。我知道这个问题以前有人问过,但我已经尝试过他们的解决方案,但没有一个奏效。以下是我尝试过的一些事情: 我已经在API7-17上测试了这段代码。不幸的是,在API 13的底部水平和垂直都有额外的空间,而在API 10、8和7
-
高负载项目中的Java OOM
以下是hs_err_filepart中的错误(已附加完整文件): 内存不足,Java运行时环境无法继续。本机内存分配(mmap)无法映射1633681408字节以提交保留内存。 可能的原因: 系统在32位模式下没有物理RAM或交换空间,进程大小限制已达到 可能的解决方案: 减少系统上的内存负载 增加物理内存或交换空间 检查交换后备存储区是否已满 在64位OS上使用64位Java 减少Java堆大小
-
使用PDFKit删除高亮注释
用户可以正常选择文本,然后从UIMENU中选择“高亮显示”或“删除高亮显示”。 为了在选择文本时自定义pdfView,我已经更改了出现的菜单-首先通过删除默认操作: 然后在viewDidLoad()中设置了自定义UIMenuItems: 当我选择突出显示的文本时,我希望用户能够通过点击“删除突出显示”来删除突出显示注释,但我根本无法想出如何仅仅删除隐藏在所选文本“后面”的注释。 这段代码正在工作,
-
堆栈高度不一致%1!=2
因此,我试图在Jasmin中创建一个简单的for循环,每次hello world通过该循环时,它都会打印出来。问题是,每当我试图通过添加一个来增加它时,我会得到这样的错误:“错误:无法初始化主类测试由:java.lang.verifyerror:(class:test,method:main signature:([ljava/lang/string;)V)不一致的堆栈高度1!=2”当我不试图添加
-
Apache Storm-Spout/Bolt高延迟崩溃
当我的拓扑使用Storm 1.1.0时,我遇到了一个问题,当拓扑具有高延迟的Bolt时,Storm会重新安排Bolt和spout或者让Bolt和spout崩溃。 现在我创建了一个LatencyTest-Topology来测试和处理这个问题。
-
Spring无功高负荷性能差
我有一个spring boot webflux应用程序,默认情况下使用Netty。其中一个业务需求,我们有要求,要求应超时在2秒内。 当很少的请求被发送到应用程序时,一切都很好,但是当请求负载增加时(比如Jmeter每秒并发超过40或50次),由于每个请求的时间超过2秒阈值,有时所有请求都会超时。 如果有人能告诉我该做什么,那将是一个巨大的帮助。在这一点上,我没有更多的改进,并认为我可能已经看错了
-
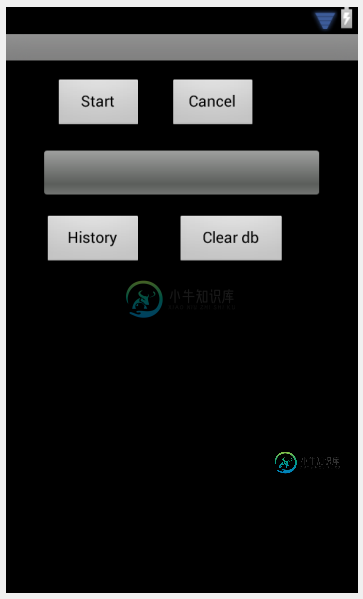 如何设置Android progressbar的高度?
如何设置Android progressbar的高度?我的如下所示,高度设置为40度。 在MyEclipse中,它如下所示: 但是当我在手机上运行它时,它看起来像下面这样: 所以我的问题是为什么进度条的真实高度不是我设置的高度?如何增加进度条的高度?
-
IntelliJ社区版JSP语法高亮
我刚刚下载了IntelliJ 15.0.1社区版,因为我厌倦了Eclipse,它在我的笔记本电脑(Ubuntu 14.04 LTS)上看起来很糟糕。一切都很顺利,直到我看到JSP文件中的语法高亮不起作用。 我转到了设置/编辑器/文件类型 在可识别的文件类型中,除了其他选项之外,我还有这个选项: JSP 文件(仅语法突出显示) 当我选择它时,我可以在注册的模式中看到:*.jsp,*.tag,这正是我
-
 PHPStorm JSX/React 语法高亮显示
PHPStorm JSX/React 语法高亮显示我目前的项目使用PHPStorm 8.0.3,但不幸的是它不支持JSX。在我的React组件(然后由Browserify编译)中,HTML用红色加下划线并被无效: 这只是一个小组件,但对于更大的组件来说,它肯定会变得非常烦人。代码格式化也不能按预期工作。 是否有(难以找到的)设置可以启用正确的语法突出显示? 如果没有这样的设置,是否可以下载相应的包? 如果根本没有支持,我如何扩展PHPStom(可
-
基于联接的高级查询
我的架构如下所示: 这是你的小提琴 图式的快速解释:我有广告: 每个广告都有洞察力,这些洞察力告诉我们某个广告何时处于活动状态(=>ad_clicks必须>0)。 每个ad都有产品(MANY2MONE-表)。每个产品都有,它告诉我们该产品在某一天产生了多少销售额。 现在,我想获取时间范围-的所有广告,这些广告的>0(我已经做了),并计算每个广告在活动时产生了多少销售额。因此,只有当广告的ad_in
-
将EAX复制到RAX的高位?
我想知道是否有任何指令序列不使用任何其他寄存器来复制RAX的低32位到其高32位。当然,我也希望EAX完好无损。 最好也不使用任何堆栈存储器。
-
Hazelcast Mancenter提高了cpu使用率
我有: a)1台服务器(4vcpu,8GB)运行hazelcast节点, b)1台(4vcpu,8MB)运行tomcat 7上的hazelcash性能中心。 两台服务器都在同一个本地网络中。 我已经测试了2个场景:< br >场景1)我已经开始了a)和b)。没有传输数据。a)上的cpu使用率为0-10%。< br >情景2)我已经开始了a)和b)。我已经将大量数据转移到a)上进行处理,并一直等到它
-
如何提高cassandra的写性能?
我有一个名为Emails的列族,我正在将邮件保存到这个CF中,编写5000封邮件需要100秒。 我使用的是i3处理器,8gb内存。我的数据中心有6个节点,复制因子=2。 我们存储在卡桑德拉中的数据大小会影响性能吗?影响写入性能的所有因素是什么,如何提高性能? 预先感谢..
-
提高spring批量作业绩效
我正在为我们的文件上传过程执行一个spring批处理工作。我的要求是读取平面文件,应用业务逻辑,然后将其存储在DB中,然后发布一个Kafka消息。 我有一个基于块的步骤,它使用自定义的读取器、处理器和写入器。这个过程工作得很好,但是处理一个大文件需要很多时间。 处理一个有60k条记录的文件需要15分钟。我需要减少到5分钟以下,因为我们将消耗比这更大的文件。 根据https://docs.sprin
-
JPA/Hibernate提高批插入性能
我有一个数据模型,在一个实体和11个其他实体之间有一对多的关系。这12个实体一起代表一个数据包。我遇到的问题是,在这些关系的“多”端发生的插入数量。其中一些可以有多达100个单独的值,因此要在数据库中保存一个完整的数据包,最多需要500次插入。 我在InnoDB表中使用MySQL 5.5。现在,通过对数据库的测试,我发现在处理批插入时,它可以轻松地每秒执行15000次插入(对于加载数据,插入次数甚