《数梦工场》专题
-
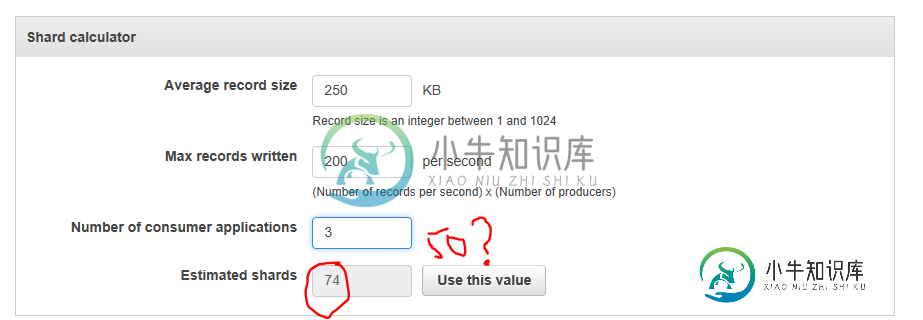 amazon streams动画片计数计算器公式如何工作
amazon streams动画片计数计算器公式如何工作我正在尝试学习aws运动流,并按照aws运动流留档。每个分片最多摄取1MB/秒或1000条记录/秒,并允许读取高达2MB/秒和每秒5个事务进行读取。 所以有人能解释一下这里的逻辑吗?谢谢。
-
谷歌数据流“工作流失败”,没有任何原因
我在谷歌云平台上运行数据流作业,我得到的一个新错误是“工作流失败”,没有任何解释。我得到的日志如下: 我该怎么找出哪里出了问题?对象上的权限不应该有问题,因为类似的作业会成功运行。当我试图从谷歌云控制台重新运行模板时,我会收到消息: 找不到此模板的元数据文件 但是我能够启动模板,现在它成功运行。这可能与超额配额有关吗?我们刚刚增加了数据流的CPU和IP配额,我将并行运行的作业从5个增加到15个,以
-
在Google工作表中将数组添加为EmbeddedChart的“范围”
简介:我想通过使用嵌入的Google脚本中生成的数组来更改Google sheets EmbeddedChart中的数据,而无需先将数据倒入单元格。 Long:我有一个绑定脚本,可以更新先前存在的电子表格。我修改了js中的数据,并希望更改一个嵌入式图表以使用生成的数据数组,而不将数据放在表中。从技术上讲,我不在乎它是一个嵌入的图表,我只想用一个图表制作一个摘要页面,而不想用额外的表格污染文档。不希
-
firebase实时数据库只在第二次请求时工作
我到处都在使用异步函数,但仍然不能很好地工作,我使用express来调用这个函数
-
如何限制Nexus中已部署快照工件的数量?
问题内容: 我们正在使用Nexus部署快照工件。我们的构建服务器使用以下命令在每次构建期间部署它们:mvn deploy。结果,在每个构建上都部署了工件的较新版本。已经将大约数十个工件部署到存储库的问题,当然我们只需要最后一个工件。有什么方法可以限制Nexus中已部署快照工件的数量?谢谢迈克尔的帮助 问题答案: 创建计划任务以清除旧快照。 以下链接描述了功能: Nexus预定任务 管理计划的任务-
-
计算Excel工作表列中的行数(提供Java代码)
问题内容: 关于我以前的问题,如何使用Java计算Excel文档的一列中的行数,我能够计算给定工作表中的总列数。现在, 由于我想计算特定列中的行数,因此尚需 完成一半的工作。可能的解决方案是使用2d数组并存储列索引和总行数或使用map等。我如何实现这一目标?这里提供了Java代码。我的演示文件计数正确(列计数)。请根据需要修改/建议更改。 (编辑):我已经用hasp映射来计算存储列索引作为键,行计
-
请你讲解一下数据连接池的工作机制?
本文向大家介绍请你讲解一下数据连接池的工作机制?相关面试题,主要包含被问及请你讲解一下数据连接池的工作机制?时的应答技巧和注意事项,需要的朋友参考一下 考察点:连接池 J2EE 服务器启动时会建立一定数量的池连接,并一直维持不少于此数目的池连接。客户端程序需要连接时,池驱动程序会返回一个未使用的池连接并将其表记为忙。如果当前没有空闲连接,池驱动程序就新建一定数量的连接,新建连接的数量由配置参数
-
将datetime转换为float时,SQL的convert函数如何工作?
问题内容: 为什么输出此查询: …是40183吗? 因此,对于那些对我的问题感到困惑的人,我的问题是如何在不执行上述查询的情况下知道上述查询的结果? 问题答案: DateTime通常表示为从整数部分上的预定日期(通常称为纪元)开始的天数,而在小数部分上表示从午夜开始经过的一天的百分比。 SQL Server也不例外,因此转换为Float非常有意义。第0天是1900年1月1日00:00:00(AFA
-
Flask-SQLAlChemy-会话如何与多个数据库一起工作?
我正在处理一个Flask项目,我正在使用Flask SQLAlchemy。 我需要处理多个已经存在的数据库。 我创建了“app”对象和SQLAlchemy对象: 在配置中,我设置了默认连接和附加绑定: 然后,我使用声明性系统创建了表模型,并在需要时设置参数以指示表位于哪个数据库中。 例如: 通过这种方式,当我在正确的数据库上进行查询时,一切都正常工作。 阅读SQLAlchemy文档和Flask S
-
查询字符串参数不工作在我的wordpress项目
我正在从事WordPress项目。在我的服务器上运行PHP7.0并安装WordPress 4.9.4。我面临的问题是:我已经创建了一个模板文件,我正在尝试打印url中的查询字符串变量,然后返回Array()空数组。 当我在根文件夹的另一个文件上尝试print_r语句时,它可以正常工作,但在functions.php或模板文件(在WordPress页面上)上它不能工作。 有人能告诉我这是怎么回事吗?
-
使jfreechart数据点中的工具提示显示得更快
是否有一种方法可以使jfreechart数据点中的tooltip显示得更快?以下是我如何自定义工具提示:
-
数据流如何自动扩展和分配工作负载?
读完这个问题后,我仍然对DataFlow/Apache Beam如何分配工作负载有一些疑问。我遇到的问题可以用下面的代码演示: 比较使用1个worker和5个worker时的最大吞吐量,而不是后者的效率高5倍,它只是稍微高一点。这让我对以下问题产生了疑问: 假设每个工作线程使用4个vCPU,那么每个线程是否绑定到特定的DoFn,或者如果需要提高性能,可以在给定时刻对所有线程调用相同的DoFns?
-
Azure工作者角色+消息队列使用者的数量
我试图理解当以azure工作者角色托管消息队列使用者时的最佳实践。我有许多不同类型消息使用者,它们订阅不同的azure服务总线订阅(或者队列,如果您愿意这样称呼的话)。我想知道是应该在一个Worker角色中为每个使用者实例化多个线程,还是应该为每个使用者部署多个Worker角色。
-
selenium webdriver未使用apache poi将数据写入excel工作表
我正在尝试使用java selenium web驱动程序apache poi从excel读取和写入数据。但我的代码是从excel表中读取数据,但没有将数据写入excel表。我已经包含了poi-4.0.1中的所有jar文件,这是我的代码 }
-
JPA Projection@OneTomany不工作“找不到适当的构造函数”
我有一个很大的实体类,有很多很多的字段,还有一个投影类,它应该是这个大实体的一部分。 除了@OneTomany字段之外,所有的东西都运行得很好。@OneTomany字段应该是一个地址列表,但当将其转换为投影类时,我总是得到错误“无法定位适当的构造函数[...]预期参数为:long,[...],***.Entity.Address”。 转换器正在搜索单个address对象,而不是address对象列