《数梦工场》专题
-
大数据工程师技能图谱
大数据通用处理平台 Spark Flink Hadoop Drill 分布式协调 ZooKeeper 分布式存储 HDFS Alluxio(tachyon) Ignite 存储格式 Parquet ORC CarbonData Kudu 数据库 HBase 资源调度 Yarn Mesos Kubernetes 工作流调度 Oozie Azkaban 机器学习工具 Mahout Spark Mlib
-
 收钱吧(数仓工程师)一面
收钱吧(数仓工程师)一面开局自我介绍,然后她也介绍了一下部门工作;问了一下数据库和数据仓库的区别,我说是回答八股文还是回答自己的经历;然后她让我结合自己的经历说了一下;接着问我对数仓分层了解的多少,对维度建模了解多少,对数仓的模型(星形,雪花,星座)之类的了解的多吗?之后问我对数仓的每个方向的具体分层有什么认识吗?我都没听明白这个问题,只好老老实实回答了一句这些东西并不是我负责的,接着她说结合我自己的理解谈一谈.....
-
 minimax数据引擎工程师一面
minimax数据引擎工程师一面秋招第一次面试,以此留作纪念 1. 背景情况了解 2. 实验室项目介绍,cv项目里如何评估准确率。 3. 问最了解的经历介绍,没说实习,说了电商数仓。 4. 数仓如何分层。 5. ods,dwd,aws层,为什么要分这3层。 6. redis主要用的数据类型。项目里是怎么设计的。sortset主要用在什么场景。并发量多大 7. 缓存击穿 8. kafka如何保证生产者端不重复和不丢失。 9. my
-
 大数据研发工程师面经
大数据研发工程师面经公司:广州网易互娱 面试时间:2024.07.23,共计65分钟 共两位技术面试官,轮流提问 流程:自我介绍、项目、基础知识(Java基础方面、数据库方面、计算机基础方面(操作系统)、计算机网络方面)、算法笔试。 问题 自我介绍 项目方面 成本治理中负责的工作内容 数据平台中,任务计算成本的计费维度 Spark作业从哪些方面可以发现能够优化? Spark作业可以从哪些方面进行优化? 从哪些配置入手
-
 百度-大数据工程师一面
百度-大数据工程师一面#百度#面试官很好,总体感觉问的比较简单,但是好久不看八股感觉很多都忘记...理解还是比较浅层,一些实战方面的内容还比较欠缺...要努力了!!!
-
 测试实习,理工数传面试
测试实习,理工数传面试不推荐去,因为他们的测试加班好像很严重。 #找实习多的是你不知道的事#
-
Java中的基数参数是什么,它如何工作?
问题内容: 我知道该函数的基数是将字符串转换为基数的基础。不应该将11的基数10与基数/基数16转换成a 而不是? 以下代码根据教科书打印17: 问题答案: 使用基数执行操作时,以11为底的16将被解析为17,这是一个简单的值。然后将其打印为基数10。 你要: 这将采用十进制值11(此刻没有底数,就像有“十一”个西瓜(比一个人的手指数多一个)),并用基数16进行打印,结果为。 当我们采用一个值时,
-
如何陆续执行参数化的工作(无参数)
问题内容: 我在詹金斯(Jenkins)有一份工作,有2个参数。我要运行另一个没有参数的计划,并从该计划中启动所需的现有计划多次。 新计划需要安排为每15分钟运行一次(将由Jenkins的Scheduler选项完成),该计划的代码将: 连接到数据库 获取所需的记录集 开始循环记录集 存储键/值对(现有作业的参数) 结束循环 完成此操作后,我需要对存储的每个键/值对运行现有作业。我可以使用Jenki
-
管道参数和jenkins GUI参数如何协同工作?
问题内容: 我在jenkinsfile中使用管道,但不确定如何在Jenkins和管道中正确链接作业。 我在jenkinsfile中定义了参数(有些具有默认值,有些 没有 ),并使用来自jenkins gui的参数进行初始化。问题是,它接缝了管道中的参数以覆盖我的作业参数, 即使在 管道中 未指定默认值时也是如此, 这意味着管道正在覆盖jenkins中的作业设置。 例如,我的一项工作是设置为使用一些
-
python的排序函数中的key参数如何工作?
问题内容: 说我有 我明白 会导致 [(’Able’,10),(’Dog’,15),(’Baker’,20),(’Charlie’,20)]] 但这如何工作? 问题答案: 传递给您的函数将获得要排序的每个项目,并返回Python可以排序的“键”。因此,如果要按字符串的 相反顺序 对字符串列表进行排序,可以执行以下操作: 这使您可以指定每个项目的排序依据值,而不必更改项目。这样,您不必构建反向字符串
-
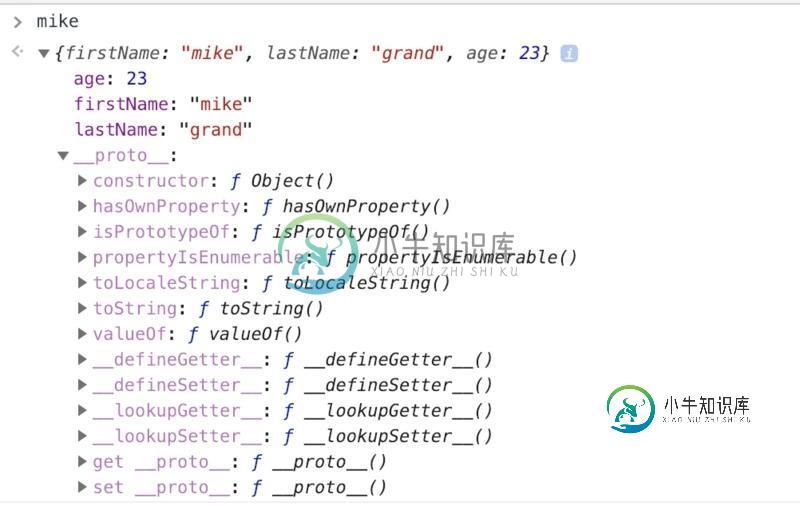 JavaScript中工厂函数与构造函数示例详解
JavaScript中工厂函数与构造函数示例详解本文向大家介绍JavaScript中工厂函数与构造函数示例详解,包括了JavaScript中工厂函数与构造函数示例详解的使用技巧和注意事项,需要的朋友参考一下 前言 当谈到JavaScript语言与其他编程语言相比时,你可能会听到一些令人困惑东西,其中之一是工厂函数和构造函数。 工厂函数 所谓工厂函数,就是指这些内建函数都是类对象,当你调用他们时,实际上是创建了一个类实例”。意思就是当我调用这个函
-
Java8数组构造函数引用是如何工作的?
使用Java8泛型,可以使用构造函数引用初始化该变量,如下所示: Java编译器如何将其转换为字节码? 我知道对于其他类型,比如,它可以使用一个指令,该指令指向字符串构造函数,这只是一个具有特殊含义的方法。
-
Azure数据工厂-按日期筛选Mongodb源数据集
这种情况非常简单,如ADFv2文档和示例中所述,我已经创建了一个复制管道来从MongoDB集合中获取数据,并将其写入AzureSQL数据库。 已成功传输完整采集数据,并且所有映射都已正确设置。当我试图过滤源数据集以仅从MongoDB获取最后n天时,问题就开始了。我尝试了几个查询,并与MongoDB Compass进行了交叉检查,以确定它们是否真的在执行Mongo-side,事实就是这样。归结起来就
-
 兴业数金 数据工程师 综合面试(2面)
兴业数金 数据工程师 综合面试(2面)史无前例的快,整个面试流程,从进去会议室到结束,共计6分钟! 不知道是不是拿我刷KPI 简单记录下 自我介绍 为什么想来上海 自身的不足 有没有想过怎么去改变 有什么想问的?(问了两个问题) #兴业数金校招##面试流程#
-
 蔚来 数字化业务 大数据开发工程师
蔚来 数字化业务 大数据开发工程师投nlp挂,转岗大数据开发 一面 算法题:一个只包含1,2,3的数组,排序使得3在最前,2在中间,1在最后。要求时间复杂度O(n),空间复杂度O(1)。 用双指针,类似快排的思路。 二面 算法题:数组中,第一个非0的数位置索引,时间复杂度O(log n)。 二分查找。 两个面试官都很nice,没有因为岗位不匹配为难。#我的秋招日记#