《小米集团》专题
-
 面题集
面题集高德前端一面24级校招: 一、回答: 如何学习前端,为什么学前端 具体的一个项目介绍 BFC HTTP状态码 盒子模型 跨域实现方法 浏览器本地缓存机制 Vue生命周期,父子组件生命周期 Vue组件间通信 Vue设计原理 React了解吗 二、代码题: 1.数组扁平化+去重 2.查找重复最多的字母及长度 3.对象数组转为树结构 对以后工作的规划 三、反问: 阿里云GIS面24级校招: 一、互相介绍
-
Apache Flink中的事件时间临时连接仅适用于小型数据集
背景:我正在尝试使用从CSV文件读取的两个“大(r)”数据集/表(左表中16K行,右表中少一些)进行事件时临时联接。这两个表都是仅附加的表,即它们的数据源当前是CSV文件,但将成为Debezium在Pulsar上发出的CDC变更日志。我使用的是相当新的语法SYSTEM\u TIME。 问题:连接结果只有部分正确,即在执行查询的开始(前20%左右),左侧的行与右侧的行不匹配,而理论上应该匹配。几秒钟
-
可变大小堆栈框架的程序集(关于局部变量的堆栈)
我有vframe函数并生成了如下的汇编代码 如果我们看到从8到11行,我们没有在堆栈上推送p的地址,但汇编已经假设 如果我们希望某些参数不被破坏,我们会推送一些寄存器并将被调用者保存的寄存器移动到推送的寄存器。但是,在这种情况下,似乎不是。关于局部变量还有其他约定吗,比如i和
-
缓冲区长度小于 mysql percona 集群中预期的有效负载长度
我试图在corda中设置一个percona集群(mysql)以实现高可用性,我配置了其他所有内容,同时试图引入corda节点(公证),我得到以下错误:
-
Java集合-使用Java 8计算总大小,然后不添加重复记录
一个存储容器中大约有500万条记录。我需要在一个集合对象中获取它们。我得到了下面的列表: 预期结果(需要计算特定“版本”的总大小): “Java”的总尺寸示例: "56" "58" "46" "56" "29"="245" 如何使用Java 8实现这一点?
-
 在android中按大于或小于的值仅显示arrayadapter中列表的子集
在android中按大于或小于的值仅显示arrayadapter中列表的子集我在arrayadapter中有一个列表,如下所示, 我只想筛选那些值小于、大于和介于值之间的列表。如何实现?
-
将Java集合转换为Scala集合
问题内容: 问题 与新HashSet(Collection)等效的Scala)相关,如何将Java集合(例如)转换为Scala集合? 我实际上是在尝试将Java API调用转换为Spring的 (返回a )成Scala不可变。因此,例如: 这似乎有效。欢迎批评! 问题答案: 您的最后一条建议有效,但您也可以避免使用: 请注意,默认情况下,由于提供了此功能。
-
操作etcd集群 - 搭建etcd集群
注:内容翻译自 Clustering Guide 概述 启动 etcd 集群要求每个成员知道集群中的其他成员。在一些场景中,集群成员的 IP 地址可能无法提前知道。在这种情况下,etcd 集群可以在发现服务的帮助下启动。 一旦 etcd 集群启动并运行,通过 运行时重配置 来添加或者移除成员。为了更好的理解运行时重配置背后的设计,建议阅读 运行时重配置的设计。 这份指南将覆盖下列用于启动 etcd
-
计算满足min(子集)max(子集)
在一次采访中被问及这个问题,没有比生成所有可能的子集更好的答案了。例子: 采访者试图暗示对数组进行排序应该会有所帮助,但我仍然无法找到比暴力更好的解决方案。非常感谢您的意见。
-
Spring集成5.1-集成流测试-dsl
我已经建立了一个简单的Spring集成流程,该流程由以下步骤组成: 然后定期轮询一个rest api 对有效载荷做一些处理 并将其置于Kafka主题上。 请遵守以下代码: 这非常有效,然而,我正在努力想出一些好的测试。 我应该如何模拟外部RESTAPI
-
采集帮助 - 管理采集节点
管理采集节点: 更改节点 导入/导出节点 配置文件
-
采集帮助 - 创建采集节点
创建采集节点: 网址索引 内容配置
-
集群部署 - NFS 下集群安装
Seafile 集群中,各seafile服务器节点之间数据共享的一个常用方法是使用NFS共享存储。在NFS上共享的对象应该只是文件,这里提供了一个关于如何共享和共享什么的教程。 如何配置NFS服务器和客户端超出了本wiki的范围,提供以下参考文献: Ubuntu: https://help.ubuntu.com/community/SettingUpNFSHowTo CentOS: http://
-
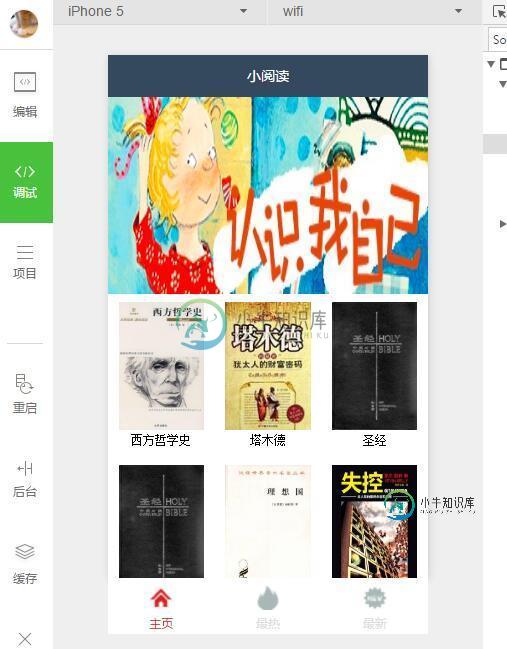 微信小程序-小说阅读小程序实例(demo)
微信小程序-小说阅读小程序实例(demo)本文向大家介绍微信小程序-小说阅读小程序实例(demo),包括了微信小程序-小说阅读小程序实例(demo)的使用技巧和注意事项,需要的朋友参考一下 今天和朋友聊天说到小程序,然后看在看书,然后我们就弄了个小读书的demo,然后现在分享一下。 一、先来上图: 二、然后下面是详细的说明 首先先说下边的tabBar,项目采用json格式的数据配置,不得不说,现在这个是趋势,.net core的配置也是这
-
python 划分数据集为训练集和测试集的方法
本文向大家介绍python 划分数据集为训练集和测试集的方法,包括了python 划分数据集为训练集和测试集的方法的使用技巧和注意事项,需要的朋友参考一下 sklearn的cross_validation包中含有将数据集按照一定的比例,随机划分为训练集和测试集的函数train_test_split 得到的x_train,y_train(x_test,y_test)的index对应的是x,y中被抽取