《汉得》专题
-
如何编写python脚本对Azure DevOps REST API进行身份验证并获得访问令牌?
使用个人访问令牌(PAT) 使用OAuth 2.0 我正在使用第二种方法。按照本文档中的步骤进行操作:https://docs.microsoft.com/en-us/azure/devops/integration/get-start/authentication/oauth?view=azure-devops 我编写这个函数是为了使用OAuth2.0实现azure DevOps: 我对pyth
-
如何合并子数组中的对象,使得在javascript中只剩下一个数组中有多个对象
我有下面的数组在数组1看到完整,我需要每个子数组合并其中的对象,这样它就像这样。 数组FINAL 因此最终结果是一个包含6个对象的数组。上面的...代表其余的对象。 我试过,但它并不完全符合我的要求。我将在数组2的数组下面发布它的操作 阵列1 这是我不想要的输出,但到目前为止我所能做的一切。在ARRAY FINAL的顶部看到我想要的输出 阵列2 感谢您提前提供的帮助
-
我想建立AEM项目与maven我得到一个错误
我试图用mvn组织构建一个aem项目。阿帕奇。专家插件:maven原型插件:2.4:generate-DarchetypeGroupId=com。土砖花岗岩原型-DarchetypeArtifactId=aem项目原型-DarchetypeVersion=12-DarchetypeCatalog=https://repo.adobe.com/nexus/content/groups/public/
-
当尝试使用Eclipse颠覆性插件提交时,得到“只能在版本资源上执行签出”
我在Mac 10.7.5,SVN 1.7和Eclipse Subversive插件上使用Eclipse Juno。偶尔,当我尝试从我的项目中提交更改时(通过右键单击包资源管理器中的项目,选择“团队” - 我已经验证了我已经签出了我的项目的最新版本。我如何处理这些重复的错误?
-
为什么我会得到不完整的监视器异常[重复]
我收到一个非法监视器异常。我在谷歌上搜索了一下,但没有什么能说明我做错了什么。 从这个normalclass中,我为其他类创建了一个对象,并将该对象交给thread和同步thread。为什么我会得到这个例外?
-
此生产者与消费者得监视状态异常非法?[副本]
在Java尝试使用一个简单的计数器来实践生产者和消费者。不知道为什么我会在这段代码上得到一个非法的监视器状态异常。 我有计数器rest和计数器Consumer方法,它们在自己的线程中运行。计数器本身是一个静态的int volatile字段。counter类还为您提供了一个锁 如果将wait naotify更改为: 代码起作用了。dosen't wait()和notify()自动获得锁synchro
-
在cdm提示Windows7中,我得到了一个“错误:无法找到或加载主类”
我昨天写了这个问题,但是我复制了错误的输出: 我试图在Windows7中的cmd提示符中运行一个java文件 我得到了错误: 错误:找不到或加载主类 在本例中,我只在记事本中保存了一个普通文件,虽然我可以编译该文件,并且它似乎创建了类文件,但它仍然在返回这个错误。 这是dir,它似乎表明类在那里: c:\users\user5\documents\eclipse\test>java Example
-
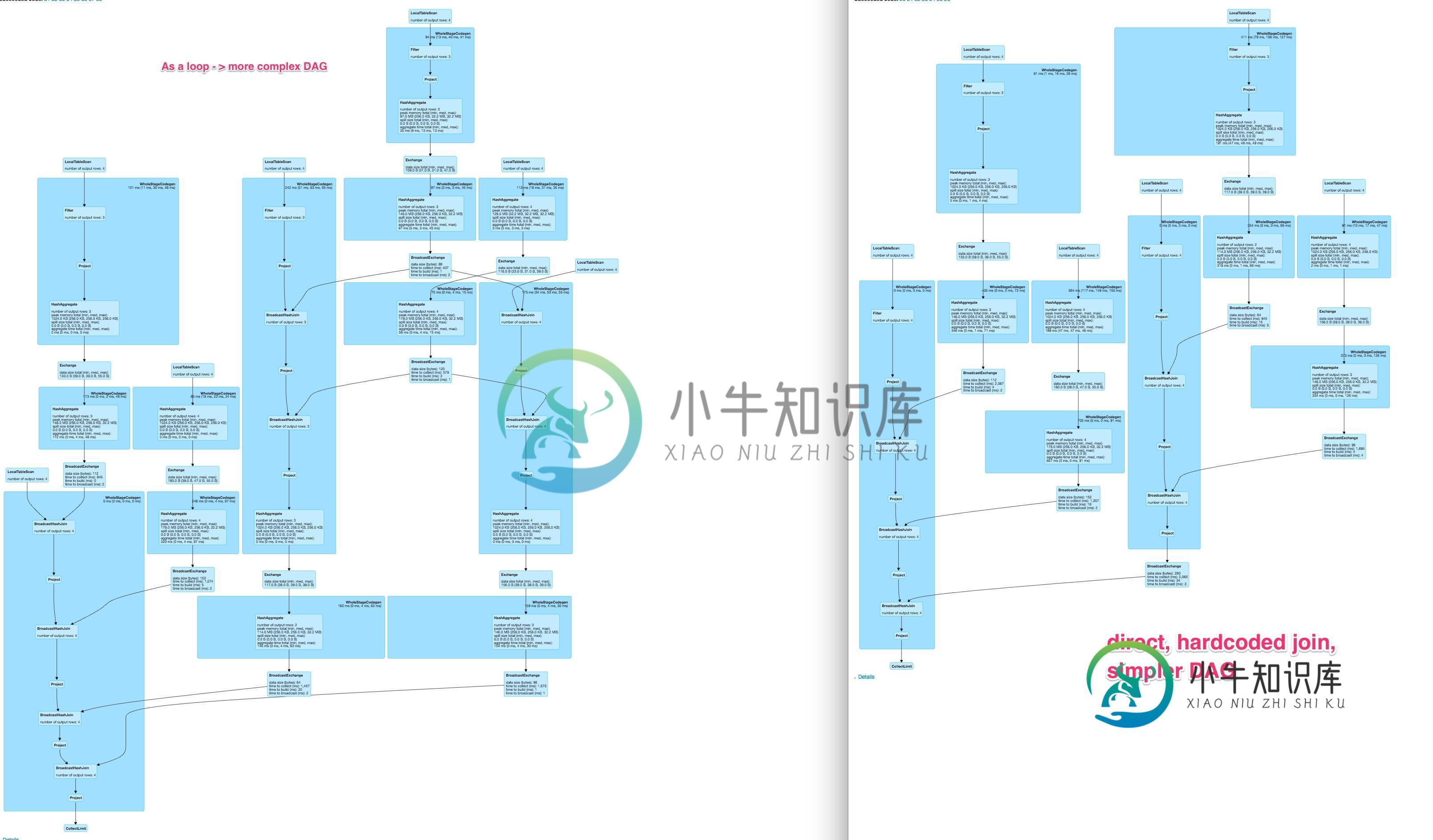 Spark dynamic DAG比硬编码DAG慢得多,而且不同于硬编码DAG
Spark dynamic DAG比硬编码DAG慢得多,而且不同于硬编码DAG我在spark中有一个操作,应该对数据帧中的几列执行。通常,有两种可能来指定这样的操作 hardcode 从colnames列表动态生成它们
-
线程获得级别
我不清楚的概念 Java Thread 在进入实例同步 java 方法时获取对象级锁,在进入静态同步 Java 方法时获取类级锁。 当它表示对象级锁定和类级锁定时,它意味着什么? 例如: 这里的getCount()将锁定Counter.class对象,而setCount()将锁定当前对象(this)。这是什么意思?这是否意味着当getCount()被调用时,另一个线程不能访问setCount(),
-
对象的Javascript数组获得单个值[重复]
假设我有一个对象数组: 是否有一个数组函数允许我获得一个属性作为数组,例如: 我知道如何得到期望的结果与一个循环,我只是希望一个数组函数或函数的组合存在,可以做到这一点在一行。
-
Angular2 Http与RXJS Observable TypeError:this。http。得到(…)。映射(…)。catch不是一个函数
我有以下服务,这是工作良好,直到今天我得到了这个错误 当我调试这段代码时,它会在捕获方法时崩溃。
-
第二种算法是如何变得比第一种算法更有效的,第二种算法中子阵列的右侧是如何移动的?
问题-给定一个n个数组,我们的任务是计算最大子数组和,即数组中连续值序列的最大可能和。当数组中可能有负值时,问题就很有趣了。数组={-1,2,4,-3,5,2,-5,2}。 第一种算法- 第二种算法- 这是它在书中说的--从算法1中去掉一个循环,就很容易让算法1变得更高效。这可以通过在子数组右端移动时同时计算和来实现。 第二种算法中子数组的右端是如何移动的,有人能给我解释一下吗?
-
如何在2.2.0中得到一个给定的Apache Spark Dataframe的Cassandra cql字符串?
看起来我可以创建一个新的TableDef,但是我必须自己完成整个映射,而且在某些情况下,像ColumnType这样的必要函数在Java中是不可访问的。例如,我试图创建一个新的ColumnDef,如下所示 目的:从Spark DataFrame中获取CQL create语句。 Input My dataframe可以有任意数量的列,这些列具有各自的Spark类型。假设我有一个有100列的Spark
-
在windows中配置CMake以从命令行使用clang来获得现代OpenMP支持
我有一个使用 OpenMP 进行并行化的小型测试项目。我的目标是编译它,以便它为库生成 和 (因为我的真实项目链接到使用这些类型分发的外部库),支持 OpenMP 4.5 或更高版本,并从命令行执行此操作,以便可以在 docker 上完成进行测试和检查(docker 部分超出了这个问题的范围, 它只是为了参考为什么我需要它从命令行工作)。我可以使用我不满意的不同编译器编译这个项目: < Li >
-
在Spark SQL中连接分区以获得更好的性能
我是Spark SQL的新手。我有一个关于联接期间分区使用的问题 假设有一个名为的表,它保存在分区(parquet)文件上。还假定。 谢谢