《研究生》专题
-
 面经|快手数据研发实习生
面经|快手数据研发实习生1.sqoop底层是怎么实现的 2.shuffle调优 3.数仓和数据集市的概念 4.数仓分层,各个层是做什么的 5.维度退化,为什么要维度退化 6.HDFS上文件用什么存储的,ORC底层是什么样的 7.sql,求TopN 8.从一个数组中求第N大的数(先手撕了一下快排,然后面试官问有没有更好的答案,然后说了一下用堆的做法) 反问 整体面试三十分钟左右,感觉是寄了
-
 中国农业银行北京研发中心软件研发岗面试
中国农业银行北京研发中心软件研发岗面试#农行北京研发中心实习面试 面试 1.冒泡排序和选择排序的相同点和不同点 2.当处理已经排好序的数组时,冒泡排序和选择排序的效率以及时间复杂度 3.折半查找的思想和时间复杂度 4.数据库的优化 5.数据库删除大量数据的时候如何进行优化 6.数据库删除的语句除了delete还有什么 7..... #中国农业银行研发中心#
-
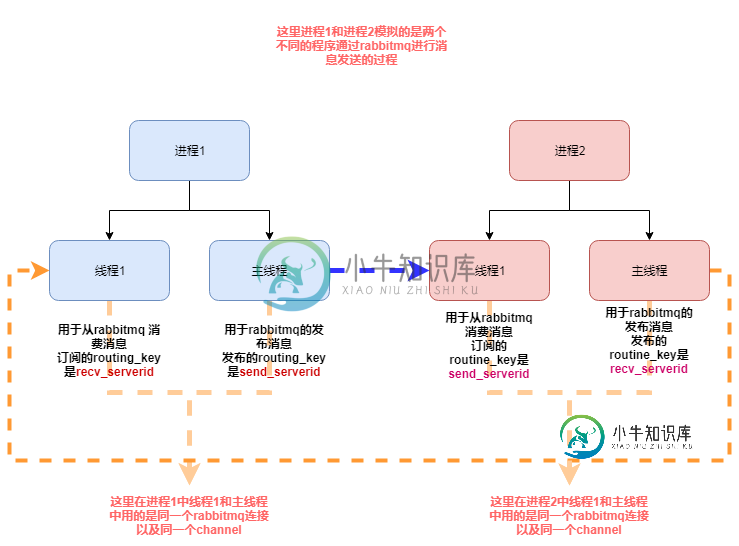 python中pika模块问题的深入探究
python中pika模块问题的深入探究本文向大家介绍python中pika模块问题的深入探究,包括了python中pika模块问题的深入探究的使用技巧和注意事项,需要的朋友参考一下 前言 工作中经常用到rabbitmq,而用的语言主要是python,所以也就经常会用到python中的pika模块,但是这个模块的使用,也给我带了很多问题,这里整理一下关于这个模块我在使用过程的改变历程已经中间碰到一些问题的解决方法 关于MQ: MQ全称为
-
 深入探究AngularJs之$scope对象(作用域)
深入探究AngularJs之$scope对象(作用域)本文向大家介绍深入探究AngularJs之$scope对象(作用域),包括了深入探究AngularJs之$scope对象(作用域)的使用技巧和注意事项,需要的朋友参考一下 这两天学习了AngularJs之$scope对象这个地方知识点挺多的,而且很重要,所以,今天添加一点小笔记。 一、作用域 AngularJs中的$scope对象是模板的域模型,也称为作用域实例.通过为其属性赋值,可以传递数据给模
-
第4章 探究分布式索引架构
在前面的章节里,我们已经学习了如何使用不同的打分公式,也了解了使用这些打分公式的好处。我们也学习了何如使用不同的倒排表结构来改变索引数据的方式。此外,我们也学习了自如应用近实时搜索和数据实时获取(real-time GET),了解了检索器(searcher)重启(reopen)背后的意义。我们也探讨了多语言数据的处理,也学习了配置事务日志来实现业务需求。最后,我们学习段合并(segments me
-
 美图C++研发实习(oc)
美图C++研发实习(oc)一面技术面-30min: 自我介绍 锁竞争优化 条件变量 项目介绍/相关问题 右值引用 vector有没有右值引用优化 push_back接口 kmp gdb 实习问题 反问 二面技术面-30min: 自我介绍 项目介绍/项目问题-效率和内存优化 智能指针 写个排序算法 项目问题 反问 三面hr面-25min: 对岗位的了解 职业规划 实习时长/目的 实习地点/岗位 所做项目的目的和来源 到岗时间
-
 多益二面—游戏研发
多益二面—游戏研发1.自我介绍 2.项目里最让你印象深刻的地方 3.如果让你实现一个消息队列,怎么做?需要考虑哪些因素 4.跨主机的消息队列怎么实现 5.如何保证消息的可达性 6.MySql和Redis的区别 7.Redis的持久化机制 8.项目里遇到大量用户同时登录的情况如何解决 9.如果服务器充足,又如何解决 10.什么是递归,递归算法要考虑哪些地方 11.了解过伪递归(还是尾递归?没问他 )吗,递归和伪递归的
-
 苏小研Python开发面经
苏小研Python开发面经一面: 两个面试官,一男一女 全程聊项目和实习,但是也只是让介绍一下 一些开放性问题,比如项目存在的问题等等 印象里没有八股,但是有类似于Python的应用场景,Python跟其他语言的区别等等 最后还问了本场面试你得到了什么 体验很好,聊的很开心,许愿有二面,喜欢苏小研捏 二面9.25,只有10分钟的hr面 9.26收到三面通知,在9.28,待更新 #中移苏州云能力中心苏小研#
-
 苏小研 2023 一二三面
苏小研 2023 一二三面#面经# #校招# #秋招# #中移苏州云能力中心苏小研# C/C++ 一面 30min+ [1]自我介绍 [2]纯项目30分钟 问的东西有一部分不会 但知道是什么 [3]有什么想问的(部门预期 怎么知道的苏研) 二面 10min [1]自我介绍 [2]常规问题 如何看待压力 如何解决困难 [3]怎么知道的苏研 [4]职业规划 三面 20min [1]介绍实习工作 [2]项目 [3]反问(工作部门
-
 广发银行研发中心
广发银行研发中心一面(10.07 35min) 1. 自我介绍; 2. 教研室项目中使用什么语言; 3. 为什么学Java; 4. 做开发的话,图像处理领域的一些研究会不会是浪费了(也不会,科研重在锻炼思维和解决问题的能力,后续开发工作中肯定有帮助); 5. JVM,JRE,JDK三者是什么关系; 6. Java中常见的异常有哪些; 7. 了解GC吗,GC的调优有做过吗; 8. Spring的框架中,介绍下Spr
-
 苏小研 python 一面面经
苏小研 python 一面面经HR提前一个半小时就打电话催促让进去等,还以为会提前呢 这也是第一次遇到盲面,全程不能提名字,会给你一个编号 共有两个面试官,看着都还挺年轻的 1. 自我介绍 2. 非科班是怎么学python的? 3. python 深拷贝浅拷贝 4. python去重方法及原理 5. django与flask差别 6. 数据库增删改查操作命令 7. tcp与udp区别 8. http数据头状态码?(这个实
-
 1018 中移杭研专业面
1018 中移杭研专业面记录珍贵的面试凉经 10月24号更新 收到了笔试信息了 三个面试官,只有一个稳定输出,一个问了两个问题,另一个全程沉默 -------------------------- 自我介绍 项目介绍 遇到的问题怎么解决的 一堆项目问题 会不会其他语言,我说Python 问会不会C/C++,Golang,臣妾确实不会 #中移杭研#
-
 苏小研 python 二面 面经
苏小研 python 二面 面经晚了约定时间一个小时,可能是我进去晚了,排序就靠后了 这一轮主要看的可能也就是仪容仪表之类的,之前邮件上说,需要“从镜头外走进来,展示身份证”,我还以为没有那么严格呢,谁知道确实需要这样 面试总共不到10分钟,大概问了这几个问题: 1. 自我介绍 2. 有offer吗?如何选择公司? 3. 对苏研的了解,来过苏州吗? 4. 成绩?排名?挂过科吗? 5. 反问 #校招##面经##中移苏州云能力中心苏
-
 苏小研-java后端三面
苏小研-java后端三面苏研三面,时长20分钟。 自我介绍; 询问学历; 从哪里得知苏小研的,手里有offer吗,为什么选择苏小研,是看重 稳定 吗; 如何看待加班(暗示加班很严重); 团队发生分歧如何解决; 实习期间遇到的最大的困难是什么,最有成就感的事情; 对云计算技术的了解; 未来3-5年规划; 反问: 多久开始发放 offer(面试官说到11中旬); 最后面试官让我多看看云相关的技术 #苏小研#
-
 滴滴后端研发一面
滴滴后端研发一面主要工作:基础架构(中台) 开始还是项目拷问(但是没有深入) 项目(学校的全校数据库是怎么交互的?) 外卖项目(缓存优化) (验证码、先访问Redis,主从复制怎么实现的?) 做这些项目遇到的难点和收获 解决问题的思路 RocketMQ用在项目什么地方?(做消息队列缓存一致性balalbala) RocketMQ(特性)(解耦、削峰) RocketMQ: NameServer:整个MQ集群提供服务