-
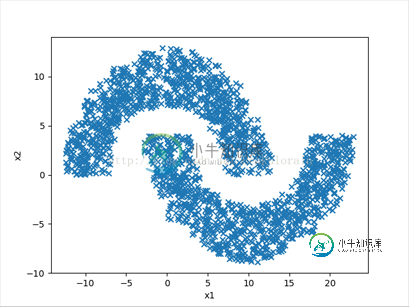 利用TensorFlow训练简单的二分类神经网络模型的方法
利用TensorFlow训练简单的二分类神经网络模型的方法本文向大家介绍利用TensorFlow训练简单的二分类神经网络模型的方法,包括了利用TensorFlow训练简单的二分类神经网络模型的方法的使用技巧和注意事项,需要的朋友参考一下 利用TensorFlow实现《神经网络与机器学习》一书中4.7模式分类练习 具体问题是将如下图所示双月牙数据集分类。 使用到的工具: python3.5 tensorflow1.2.1 numpy matp
-
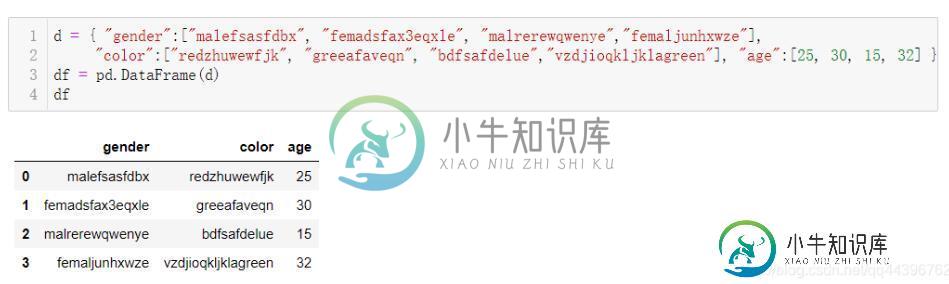 Pandas 模糊查询与替换的操作
Pandas 模糊查询与替换的操作本文向大家介绍Pandas 模糊查询与替换的操作,包括了Pandas 模糊查询与替换的操作的使用技巧和注意事项,需要的朋友参考一下 主要用到的工具:Pandas 、fuzzywuzzy Pandas:是基于numpy的一种工具,专门为分析大量数据而生,它包含大量的处理数据的函数和方法, 以下为pandas中文API: 缩写和包导入 在这个速查手册中,我们使用如下缩写: df:任意的Pandas D
-
如何计算滚动idxmax
问题内容: 考虑 我想获取滚动窗口3的最大值的索引 我想要的是 我做了什么 这显然不是我想要的 问题答案: 没有简单的方法可以执行此操作,因为传递给rolling-applied函数的参数是一个普通的numpy数组,而不是pandas Series,因此它不了解索引。此外,滚动函数必须返回浮点结果,因此,如果它们不是浮点的,则不能直接返回索引值。 这是一种方法: 这个想法是采用argmax值,并通
-
在不规则网格上进行插值
问题内容: 因此,我有三个numpy数组,它们在网格上存储纬度,经度和一些属性值-也就是说,我有LAT(y,x),LON(y,x)和温度T(y,x) ),对于x和y的某些限制。网格不一定是规则的-实际上,它是三极的。 然后,我想将这些属性(温度)值插值到一堆不同的纬度/经度点上(分别存储为lat1(t),lon1(t),大约10,000 t …),这些点不属于实际的网格点。我已经尝试过matplo
-
遍历numpy.array的任意维度
问题内容: 是否有函数可以在numpy数组的任意维度上获得迭代器? 在第一维上迭代很容易… 但是,要遍历其他维度很难。例如,最后一个维度: 我正在自己生成一个发生器来执行此操作,但令我惊讶的是,没有像numpy.ndarray.iterdim(axis = 0)这样的函数可以自动执行此操作。 问题答案: 您提出的建议相当快,但是可以通过以下更清晰的形式来提高可读性: 或者更好(更快,更通用,更明确
-
numpy.where(condition)的输出不是数组,而是数组的元组:为什么?
问题内容: 我正在尝试该功能。 从numpy文档中,我了解到,如果仅给出一个数组作为输入,它应该返回该数组非零的索引(即“ True”): 如果仅给出条件,则返回元组condition.nonzero(),其中condition为True的索引。 但是,如果尝试一下,它将返回一个包含两个元素的 元组 ,其中第一个是所需的索引列表,第二个是空元素: 所以问题是:为什么?这种行为的目的是什么?在什么情
-
如何将模型对象列表转换为pandas数据框?
问题内容: 我有一个此类的对象数组 打印时,数组看起来像这样 我想将其转换为数据帧,以便我可以以更适合我的方式进行操作-进行汇总,计数,求和等。我希望这个数据框看起来像这样: 有没有一种方法可以轻松地使用numpy / pandas来实现,而无需手动处理输入数组? 问题答案: 导致预期结果的代码: 感谢@Serbitar为我指出正确的方向。
-
Dataset.from_tensors和Dataset.from_tensor_slices有什么区别?
问题内容: 我有一个表示为NumPy形状矩阵的数据集,我希望将其转换为TensorFlow类型。 我正在努力尝试理解这两种方法之间的区别:和。什么是正确的,为什么? TensorFlow文档(link)表示,这两种方法都接受张量的嵌套结构,尽管使用张量时在第0维上应具有相同的大小。 问题答案: 合并输入并返回具有单个元素的数据集: 为输入张量的每一行创建一个具有单独元素的数据集:
-
 matplotlib bar()实现百分比堆积柱状图
matplotlib bar()实现百分比堆积柱状图本文向大家介绍matplotlib bar()实现百分比堆积柱状图,包括了matplotlib bar()实现百分比堆积柱状图的使用技巧和注意事项,需要的朋友参考一下 使用matplotlib创建百分比堆积柱状图的思路与堆积柱状图类似,只不过bottom参数累计的不是数值而是百分比,因此,需要事先计算每组柱子的数值总和,进而求百分比。 未使用numpy版本 适用于少量数据,数据结构需要手动构造。
-
从上一次在Pandas DataFrame中发生以来,还剩下几天吗?
问题内容: 假设我有一个Pandas DataFrame : 对于每一行,我想有效地计算自上次出现以来的天数。 这样: 我可以做一个循环: 但是,对于庞大的数据集而言,效率似乎很低,而且可能还是不正确。 问题答案: 这是NumPy的方法- 很少有关于数组数据的示例来展示涉及触发器和起始值的各种场景的用法: 用它来解决我们的情况: 样本输出- 运行时测试 方法- 时间-
-
Keras顺序模型的多个输入
问题内容: 我正在尝试合并两个模型的输出,并使用keras顺序模型将它们作为第三模型的输入。型号1: 型号1: 型号3: 直到这里,我的理解是,来自两个模型的输出x和y被合并并作为第三模型的输入。但是当我全都喜欢的时候 in1和in2是尺寸为10000 * 750的两个numpy ndarray,其中包含我的训练数据,而np_res_array是相应的目标。 这给了我错误,因为“列表”对象没有属性
-
Python-集成Java GUI和python代码的最佳方法
问题内容: 我想制作一个与用户文件交互的桌面GUI(当然要经过许可)。我下载文件并将其放在用户选择的目录中的代码全部用python编写。这段代码还有很多,但所有内容都是用python编写的。 我希望GUI部分成为桌面应用程序,以便客户端可以轻松地交互和运行程序。 我想用Java制作此GUI,并在有人按下按钮后使其与python代码交互。 实现此目标的最佳方法是什么? 问题答案: 我会这样: 您还可
-
Python-从类定义中的列表理解访问类变量
问题内容: 如何从类定义中的列表理解中访问其他类变量?以下内容在Python 2中有效,但在Python 3中失败: Python 3.2给出了错误: 尝试Foo.x也不起作用。关于如何在Python 3中执行此操作的任何想法? 一个稍微复杂的激励示例: 在此示例中,apply()这是一个不错的解决方法,但可悲的是它已从Python 3中删除。 问题答案: 类范围和列表,集合或字典的理解以及生成器
-
在现代Python中声明自定义异常的正确方法?
问题内容: 在现代Python中声明自定义异常类的正确方法是什么?我的主要目标是遵循其他异常类具有的任何标准,以便(例如)我捕获到异常的任何工具都可以打印出我包含在异常中的任何多余字符串。 “现代Python”是指可以在Python 2.5中运行但对于Python 2.6和Python 3. 是“正确”的方式。所谓“自定义”,是指一个Exception对象,该对象可以包含有关错误原因的其他数据:字
-
Python-在Python中,比较float与几乎相等的最佳方法是什么?
问题内容: 在Python中,比较float与几乎相等的最佳方法是什么? 问题答案: Python 3.5添加了PEP 485中描述的和功能。 如果你使用的是Python的早期版本,则等效功能在文档中给出。 是一个相对容差,它乘以两个参数中的较大者;当值变大时,它们之间的允许差异也会变大,同时仍将它们视为相等。 是在所有情况下均按原样应用的绝对公差。如果差异小于这些公差中的任何一个,则认为值相等。