
python - scrapydweb 出现Not a directory?

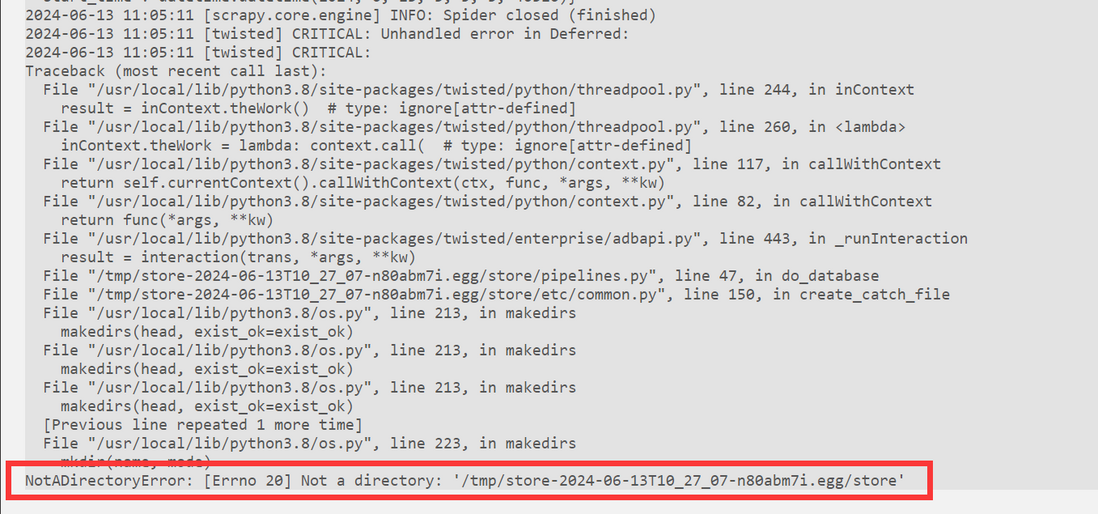
有没有大神遇到过类似问题,帮忙指点一二,有偿服务
谢谢
共有1个答案

参考这个:
https://github.com/scrapy/scrapyd-client?tab=readme-ov-file#egg-caveats

-
ScrapydWeb 是一个用于 Scrapyd 集群管理的 web 应用,支持 Scrapy 日志分析和可视化。 特性: Scrapyd 集群管理 支持所有 Scrapyd JSON API 支持通过分组和过滤来选择若干个节点 一次操作, 批量执行 Scrapy 日志分析 数据统计 进度可视化 日志分类 增强功能 自动打包项目 集成 LogParser 定时器任务 监控和警报 移动端 UI we
-
几天前不小心删了chrome浏览器,重装后出现问题,今天运行python代码时出现 init() got an unexpected keyword argument 'executable_path’ 错误,以前没有出现过的,于是我执行 后,出现更严重的问题 这个问题困扰我几天了,昨天重装浏览器后好了一阵,跑我的python代码没问题,今天又出现了前面提到的问题
-
本文向大家介绍Python中首次出现真数,包括了Python中首次出现真数的使用技巧和注意事项,需要的朋友参考一下 在本文中,我们需要在给定的数字列表中找到第一个出现的非零数字。 与枚举和下一个 我们起诉枚举以获取所有元素的列表,然后应用下一个函数以获取第一个非零元素。 示例 输出结果 运行上面的代码给我们以下结果- 与下一个和过滤器 将next和filter条件以及lambda表达式应用于条件不
-
昨天出现 got an unexpected keyword argument 'executable_path’问题后, 改成 后跑代码没有问题,可今天又出现新的问题, 跟前几次错误好像又不一样了,一失足成千古恨,真不该乱删c盘文件,请高人救命!
-
本文向大家介绍python实现将内容分行输出,包括了python实现将内容分行输出的使用技巧和注意事项,需要的朋友参考一下 #python版一行内容分行输出 再给大家一个读取文件内容并分行输出的方法 好了,小伙伴们自己好好研究下吧,很有意思。
-
问题内容: 使用@jit装饰器运行代码时出现错误。似乎无法找到函数scipy.special.gammainc()的某些信息: 没有@jit装饰器,代码将正常运行。也许需要一些使scipy.special模块的属性对Numba可见的东西? 在此先感谢您的任何建议,评论等。 问题答案: 问题在于这不是Numba固有的一小部分函数(请参阅http://numba.pydata.org/numba- d