
ScrapydWeb 是一个用于 Scrapyd 集群管理的 web 应用,支持 Scrapy 日志分析和可视化。
特性:
-
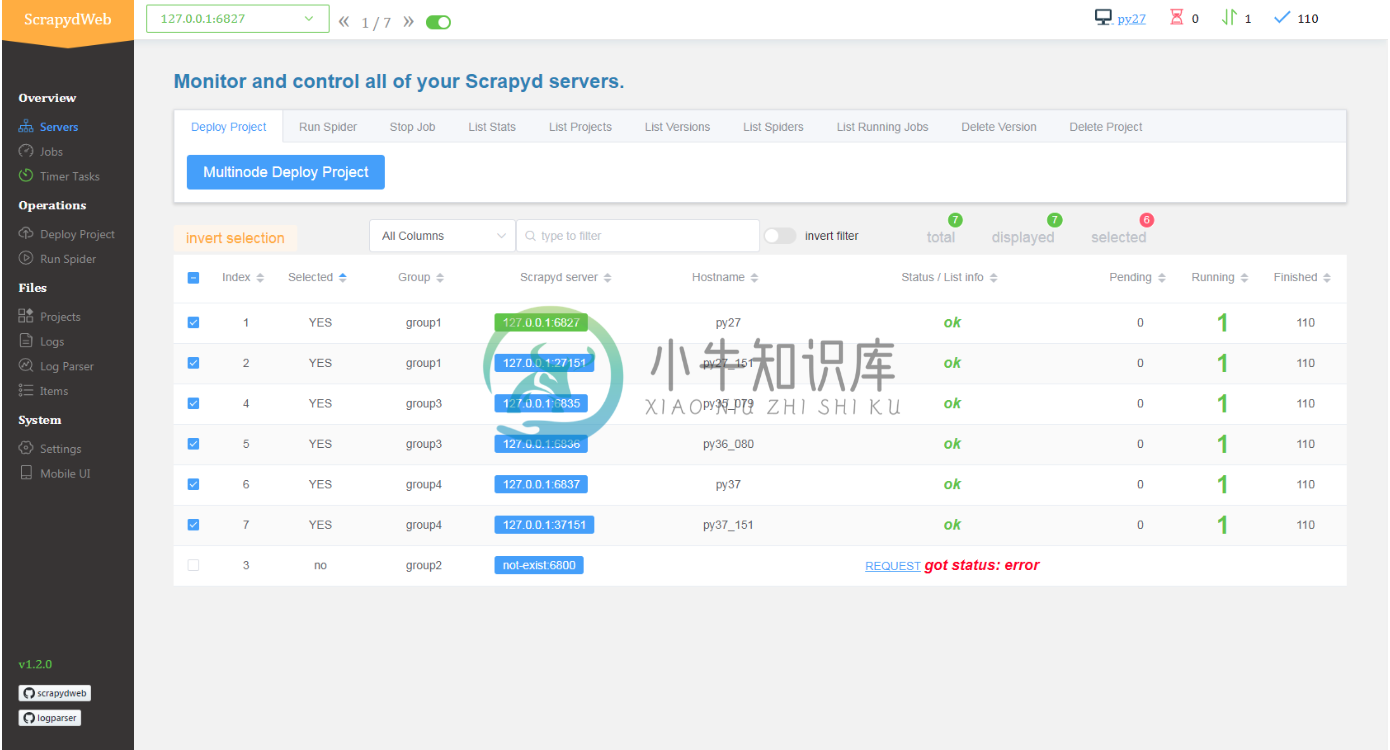
Scrapyd 集群管理
- 支持所有 Scrapyd JSON API
- 支持通过分组和过滤来选择若干个节点
- 一次操作, 批量执行
-
Scrapy 日志分析
- 数据统计
- 进度可视化
- 日志分类
-
增强功能
- 自动打包项目
- 集成 LogParser
- 定时器任务
- 监控和警报
- 移动端 UI
- web UI 支持基本身份认证
框架依赖:
- 前端
- Element
- ECharts
- 后端
- Flask
-
安装python3.6.5 安装依赖 yum -y install python-devel openssl-devel bzip2-devel zlib-devel expat-devel ncurses-devel sqlite-devel gdbm-devel xz-devel tk-devel readline-devel gcc 下载python3.6.5.tgz /usr/local/
-
文章开始,先摘录一下文中各软件的官方定义 Scrapy An open source and collaborative framework for extracting the data you need from websites.In a fast, simple, yet extensible way. Scrapyd Scrapy comes with a built-in servic
-
scrapyd + scrapydweb 安装部署 scrapydweb 启动目录为:/etc/init.d 一、安装和配置 参考安装地址:https://github.com/my8100/files/blob/master/scrapydweb/README_CN.md?tdsourcetag=s_pctim_aiomsg 1.安装: pip3 install scrapyd pip3
-
可视化爬虫ScrapydWeb的安装(Linux)(python3及以上) 官方文档:https://github.com/my8100/files/blob/master/scrapydweb/README_CN.md 首先需要安装 scrapyd(可移步安装) 安装 pip3 install scrapydweb 在scrapyd挂起的状态下运行scrapydweb 在python scrap
-
查了很多有说是python版本的问题,需要降低到3.6,经试验,应该是多个包版本不匹配的问题,最终解决了问题,把过程分享下来,有用的点个赞吧~ 新建一个requirements.txt文件: pip>=19.1.1 APScheduler>=3.5.3 flask>=1.0.2 flask-compress>=1.4.0 Flask-SQLAlchemy>=2.3.2 logparser==0.8
-
scrapydweb启动报错UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xc1 计算机名不能带中文
-
我创建了两个java web应用程序,一个使用mysql,另一个使用oracle。我在glassfish4.0服务器中部署了这些应用程序,并且工作正常。然后,我在服务器中创建集群,其中1个实例位于本地节点,1个实例来自远程节点。该集群和实例成功运行 然后我将应用程序部署到集群,当我在浏览器中运行web时, 应用程序使用mysql显示错误“类名错误或未为com.mysql.jdbc.jdbc2.op
-
主要内容:使用简介 Docker Swarm 是 Docker 的集群管理工具。它将 Docker 主机池转变为单个虚拟 Docker 主机。 Docker Swarm 提供了标准的 Docker API,所有任何已经与 Docker 守护程序通信的工具都可以使用 Swarm 轻松地扩展到多个主机。 支持的工具包括但不限于以下各项: Dokku Docker Compose Docker Machine Jen
-
集群管理架构概述。 { "clusters": [], "sds": "{...}", "local_cluster_name": "...", "outlier_detection": "{...}", "cds": "{...}" } clusters (required, array) 群集管理器将执行服务发现,健康检查和负载平衡的上游群集列表。 sds (someti
-
集群管理架构概述 v1 API 参考 v2 API 参考 统计 概述 健康检查统计 离群检测统计 动态HTTP统计 动态HTTP交叉树统计 按服务区动态HTTP统计 负载均衡统计 负载均衡子集统计 运行时设置 主动健康检查 离群异常检测 核心 区域负载均衡 熔断 集群发现服务 统计 健康检查 TCP健康检查 熔断 运行时配置
-
Envoy的集群管理器管理所有配置的上游集群。就像Envoy配置可以包含任意数量的监听器一样,配置也可以包含任意数量的独立配置的上游集群。 上游集群和主机从网络/HTTP过滤器堆栈中抽象出来,因为上游集群和主机可以用于任意数量的不同代理任务。集群管理器向过滤器堆栈公开API,允许过滤器获得到上游集群的L3/L4连接,或者到上游集群的抽象HTTP连接池的句柄(无论上游主机是支持HTTP/1.1还是H
-
用户除了通过控制台管理集群外,还可以通过ssh直接登陆到主节点上进行操作。主节点上已经完成了集群环境的相关配置,您可以直接在主节点上执行命令。 您还可以通过ssh架设SOCKS5代理服务器后,访问到集群内原生的hadoop管理页面。 生成密钥对 在自己机器上,执行命令如下 ssh-keygen -f ./hadoop_key -C "emr public key" 其中-f指定文件,-C添加
-
本文向大家介绍Java基于elasticsearch实现集群管理,包括了Java基于elasticsearch实现集群管理的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了java基于elasticsearch实现集群管理,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 本篇文章主要是查看集群中的相关信息,具体请看代码和注释 以上就是本文
-
在本书的最佳实践部分,我们在CentOS上部署了kuberentes集群,其中最开始又重要的一步就是创建TLS认证的,查看创建TLS证书和秘钥。很多人在进行到这一步时都会遇到各种各样千奇百怪的问题,这一步是创建集群的基础,我们有必要详细了解一下其背后的流程和原理。 概览 每个Kubernetes集群都有一个集群根证书颁发机构(CA)。 集群中的组件通常使用CA来验证API server的证书,由A