
如何从摘要报告中识别吞吐量

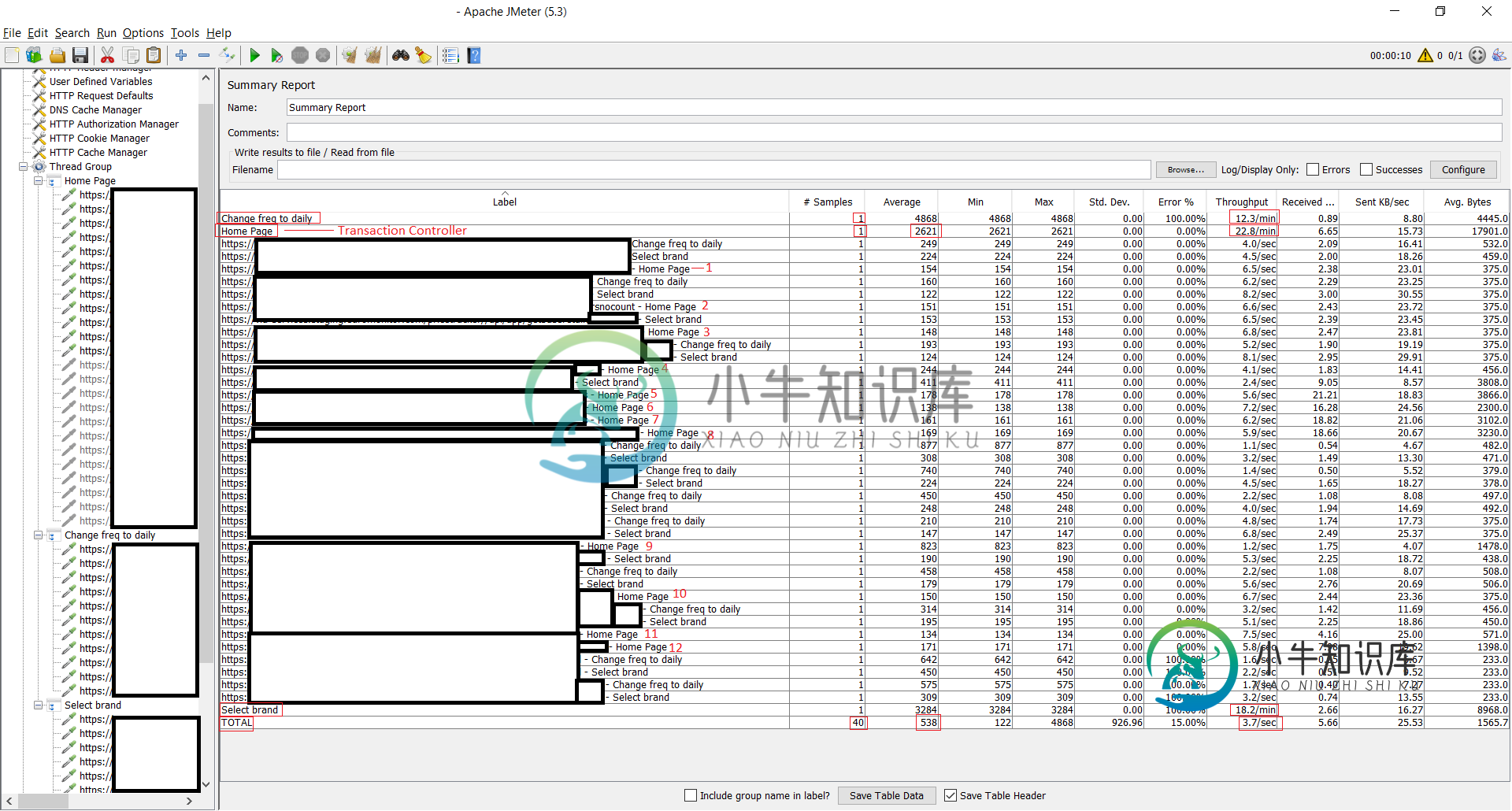
事务控制器“主页”中有12个请求。已启用的请求总数为12。事务控制器“将频率更改为每日”中有11个请求。交易控制器“选择品牌”中有14个请求。
所有3个事务控制器的设置相同,如下所示。我只使用了1个线程组。线程数为1,循环计数也为1

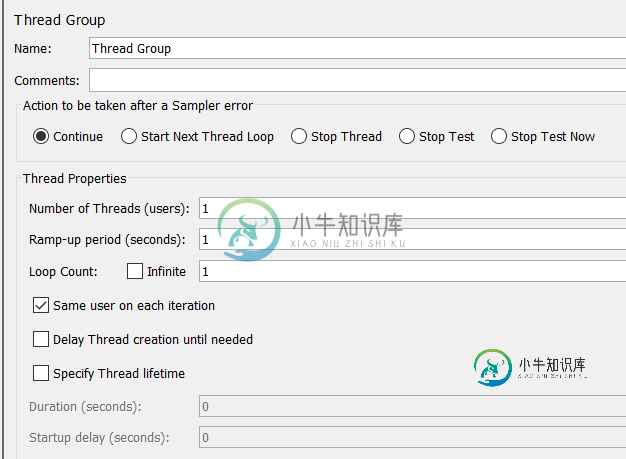
根据执行总结报告,我有以下问题,如果有人能正确回答,我将不胜感激。
>
从图像中可以看出,主页事务控制器显示的样本数为1。它不应该显示执行的样本总数为12个吗?
“主页”事务控制器的吞吐量为22.8/min。那么,这是否意味着在“主页”事务中,每分钟处理22.8个请求?22.8是如何计算的?这是“主页”事务控制器下所有12个请求的吞吐量之和吗?
在名为“总计”的行和“吞吐量”列中,它将总计显示为3.7/秒。如何计算数字3.7?这意味着什么?这是否意味着整个性能测试的吞吐量为3.7/秒?如何找到整个性能测试的吞吐量?
我猜主页交易控制器的“平均值”显示正确,这是12个api请求的所有12个平均值的总和。我说的对吗?
在名为“总计”的行和“平均”列中,总计显示为538。数字538是怎么计算出来的?这意味着什么?
在名为“总计”的行和“样本”列中,它显示了40个样本。这还包括事务控制器示例(共3个)。这是否具有误导性,因为预期只有37个样本(在所有3个事务控制器中添加样本=37)。为什么还要为事务控制器添加3个示例?我们是否可以不将计数视为37,这是实际执行的样本(发送到服务器的api请求)?
共有1个答案

>
它不应该这样做,它充当一个额外的“伪”采样器,保存其子级的累积响应时间,有关更多详细信息,请参阅使用JMeter的事务控制器
根据JMeter词汇表:
吞吐量按请求/时间单位计算。计算从第一个样本开始到最后一个样本结束的时间。这包括样本之间的任何间隔,因为它应该表示服务器上的负载。
公式是:吞吐量=(请求数)/(总时间)。
见第2点
它是12个子运行时间的算术平均值(所有响应时间之和除以12)
参见第4点,但不考虑12个取样器结果,而是考虑所有样本结果
参见第1点,这是事务控制器的工作方式,取决于它可以采用的模式:
- 要么添加一个额外的样本结果,包含其子级的累积响应时间
- 或用累积时间的单个样本结果替换其子级
因此,您可以选择拥有40个样本(37个3个事务控制器)或3个样本(仅限事务控制器)
-
汇总报告中最后一行显示的总吞吐量是否正确?我使用的是Jmeter 2.11 有人能帮我一下吗?
-
有人能帮我吗?
-
我需要从很多客户端通过网络套接字连接到java服务器来提取数据。 有很多web套接字实现,我选择了vert。x、 我做了一个简单的演示,在那里我听json的文本帧,用jackson解析它们,然后返回响应。Json解析器对吞吐量没有显著影响。 我的总速度是每秒2.5公里,有2到10个客户。 然后我尝试使用缓冲,客户端不会等待每个响应,而是在服务器确认后发送一批消息(30k-90k),速度提高到每秒8
-
假设我有一个每分钟200个事务(运行线程)的恒定吞吐量的JMeter测试脚本,并且我有两个由JMeter主机控制的从机来执行该脚本,那么产生的吞吐量会翻倍吗?还是JMeter会在从机之间共享负载,导致仍然是200TPM? 干杯凯
-
通常会创建一个或多个linux VM,并运行一个或多个jmeter主/从机。然后您可以收集threadgroups摘要报告侦听器的输出,其中包含诸如average、min、max、Std.Deviation、95percentile等字段。 当您在devops中“Load Tests”->New->“Apache jmeter Test”下运行jmeter项目时,它确实会在图表、摘要和日志下输出一
-
这些天我试图使用JMeter做负载测试。有一个非常令人困惑的点我不明白:分布式环境: 1。运行JMeter Server 2的3台8 CPU 16G服务器。4 CPU 8G服务器运行JMeter 3.这些服务器在同一个子网上。 线程组设置:线程数:2000爬升:0循环:10吞吐量为3000/s 另一个线程组:线程数:2000提升:1循环:10吞吐量为5000/s 另一个线程组:线程数:2000爬升