
如何追踪熊猫系列中的连续高点?

我想追踪连续的高点,如这张照片所示,在熊猫的时间序列中。见下图:
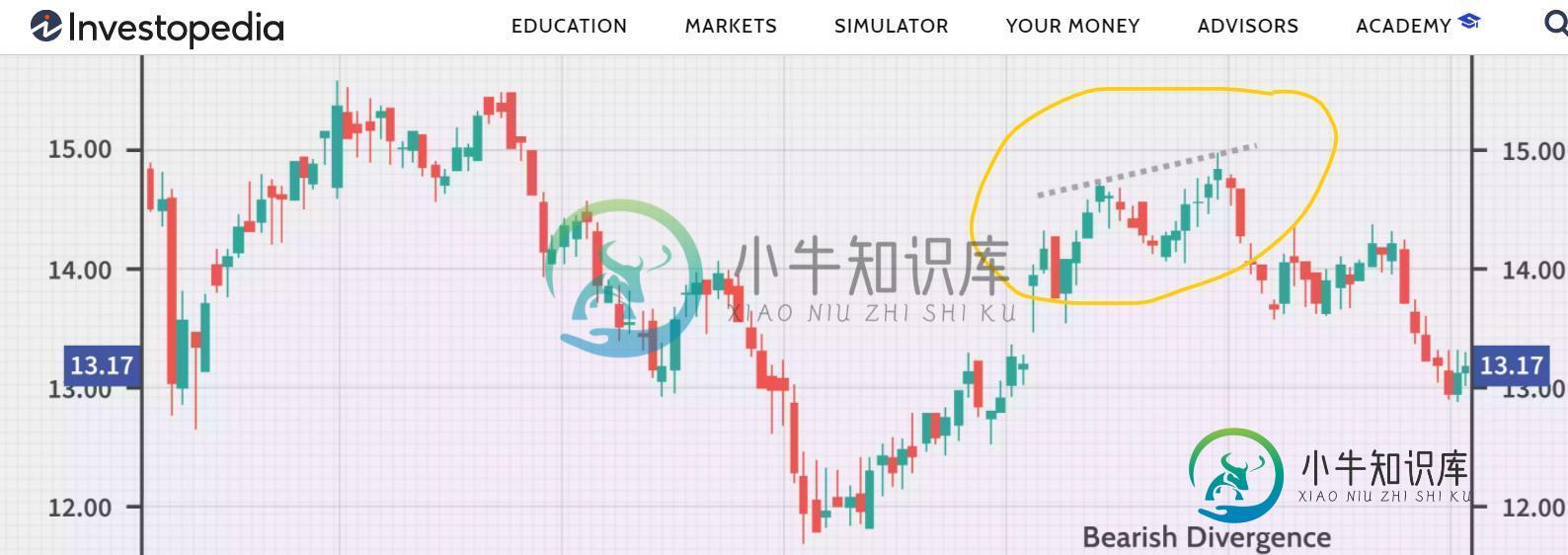
熊猫怎么能做到这一点?
如果你想玩一个真实的例子,你可以下载股票的价格,说“MSFT”,然后用“close”作为例子。有多种方法可以下载股票价格,但这里有一种:
import yahooquery
ticker = Ticker('MSFT', asynchronous=True)
df = ticker.history()
共有1个答案

没有返回足够的数据来执行所需的操作。如果数据集有连续的局部最大值,那么使用SO查找最小/最大值技术可以通过分析max列来工作。
import yahooquery
import matplotlib.pyplot as plt
import pandas as pd, numpy as np
from scipy.signal import argrelextrema
ticker = yahooquery.Ticker('MSFT', asynchronous=True)
df = ticker.history()
df = df.reset_index()
n = 5
df['min'] = df.iloc[argrelextrema(df.close.values, np.less_equal,
order=n)[0]]['close']
df['max'] = df.iloc[argrelextrema(df.close.values, np.greater_equal,
order=n)[0]]['close']
plt.scatter(df["date"], df['min'], c='r')
plt.scatter(df["date"], df['max'], c='g')
plt.plot(df["date"], df["close"])
plt.show()
-
问题内容: 如何获得系列中最常出现的物品? 考虑系列 返回值应该是 问题答案: 您可以使用并提取第一个值: 这不一定是低效率的。与往常一样,对您的数据进行测试以查看适合的数据。
-
我在一个公认的缓慢配置中设置了Kafka——但我不期待我看到的数字。 我将集群设置为<code>LogAppendTime</code>,因此我正在测量事件写入Kafka(由代理决定)与服务接收到事件之间的时间。代理和应用程序都位于“同一位置”,因此服务器之间的ping时间很短,时钟应该同步或接近。 我看到延迟在 到 600ms 之间,很多是 ......巨大的差异让我觉得我的设置出了问题。它因消
-
持续心率追踪功能全天候测量您的心率。它能够更准确地测量每日卡路里消耗量和总体活动量,因为可以追踪诸如骑自行车等很少需要手腕运动的身体活动。 手表上的持续心率追踪 在手表的设置 > 一般设置 > 持续心率追踪中,您可以打开、关闭持续心率追踪功能,或切换至仅夜间模式。如果选择仅限夜间模式,请将心率追踪的开始时间设置为您最早的睡觉时间。 默认情况下,此功能关闭。在手表中始终开启持续心率追踪功能将更快地耗
-
持续心率追踪功能全天候测量您的心率。它能够更准确地测量每日卡路里消耗量和总体活动量,因为可以追踪诸如骑自行车等很少需要手腕运动的身体活动。 手表上的持续心率追踪 在手表的设置 > 一般设置 > 持续心率追踪中,您可以打开、关闭持续心率追踪功能,或切换至仅夜间模式。如果选择仅限夜间模式,请将心率追踪的开始时间设置为您最早的睡觉时间。 默认情况下,此功能关闭。在手表中始终开启持续心率追踪功能将更快地耗
-
问题内容: 这可能很容易,但是我有以下数据: 在数据框1中: 在数据框2中: 我想要一个具有以下形式的数据框: 我尝试使用该方法,但是得到了交叉连接(即笛卡尔积)。 什么是正确的方法? 问题答案: 通常看来,您只是在寻找联接:
-
第一科伦:武器 第二栏:Pepetrator_年龄 例如,y轴应该是案件数量x轴犯罪人的年龄 线是犯罪者使用的武器类型 您可以将其复制粘贴到jupyter以初始化数据集 此处的数据集:https://www.kaggle.com/jyzaguirre/us-homicide-reports