
数据帧中的对象值的KeyError

有人能解释为什么“路易斯维尔”会返回一个键错误吗?据我所知,这是在数据框架内。我错过了什么?
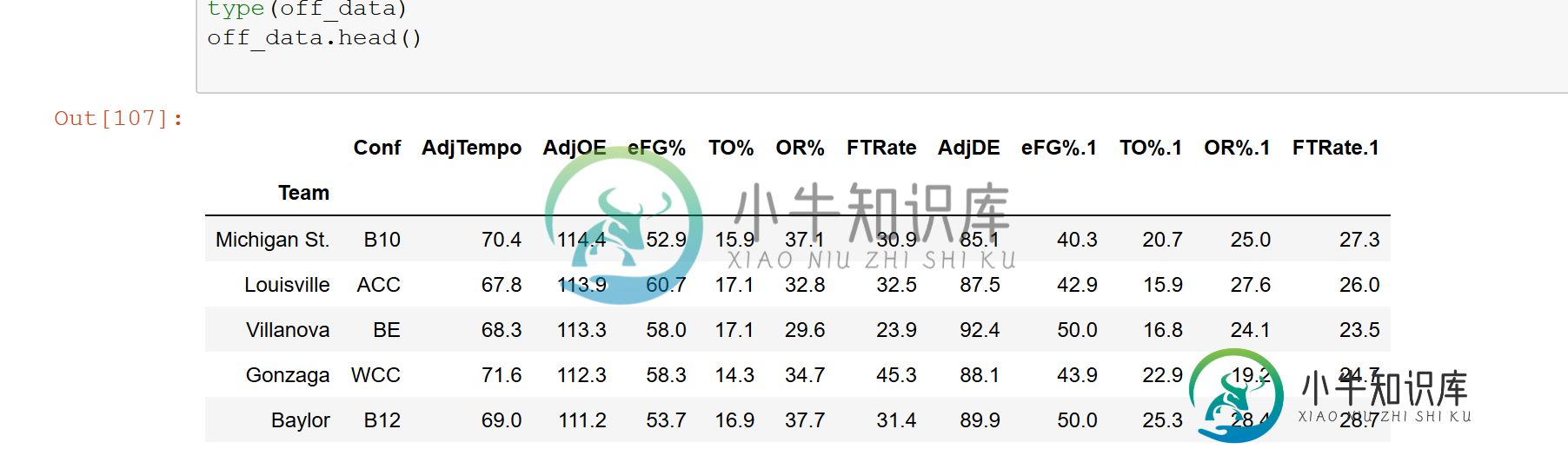
下面是数据的样子。这是一个CSV。

这就是关闭数据的内容。head()看起来像
off_data.index代码

off_data.columns

off_data[0:2].to_dict()

Rajith Thennakoon的建议

{'Conf': {'Michigan St. ': 'B10', 'Louisville ': 'ACC'},
'AdjTempo': {'Michigan St. ': 70.4, 'Louisville ': 67.8},
'AdjOE': {'Michigan St. ': 114.4, 'Louisville ': 113.9},
'eFG%': {'Michigan St. ': 52.9, 'Louisville ': 60.7},
'TO%': {'Michigan St. ': 15.9, 'Louisville ': 17.1},
'OR%': {'Michigan St. ': 37.1, 'Louisville ': 32.8},
'FTRate': {'Michigan St. ': 30.9, 'Louisville ': 32.5},
'AdjDE': {'Michigan St. ': 85.1, 'Louisville ': 87.5},
'deFG%': {'Michigan St. ': 40.3, 'Louisville ': 42.9},
'dTO%': {'Michigan St. ': 20.7, 'Louisville ': 15.9},
'dOR%': {'Michigan St. ': 25.0, 'Louisville ': 27.6},
'dFTRate': {'Michigan St. ': 27.3, 'Louisville ': 26.0}}
输入
import pandas as pd
off_data = pd.read_csv(r'C:\Users\westc\Desktop\sports.data\ncaab\kenpomdata\off20.csv', index_col= 'Team')
type(off_data)
off_data.loc["Louisville",0]
KeyError Traceback(最近的调用最后)~\Anaconda3\lib\site-包\熊猫\核心\索引\base.py在get_loc(自己,关键,方法,公差)2896尝试:-
熊猫库\索引。大熊猫中的pyx_图书馆。指数IndexEngine。获取_loc()
熊猫库\索引。大熊猫中的pyx_图书馆。指数IndexEngine。获取_loc()
pandas\u libs\hashtable\u class\u助手。熊猫体内的pxi_图书馆。哈希表。PyObjectHashTable。获取_项()
pandas\u libs\hashtable\u class\u助手。熊猫体内的pxi_图书馆。哈希表。PyObjectHashTable。获取_项()
关键错误:'路易斯维尔'
在处理上述异常期间,发生了另一个异常:
4-5类型(关闭数据)中的KeyError回溯(最近一次调用)----
~\Anaconda3\lib\site packages\pandas\core\index。getitem(self,key)1416中的py,除了(KeyError,indexer,AttributeError):1417通过-
~\Anaconda3\lib\site packages\pandas\core\index。py in_getitem_元组(self,tup)803 def_getitem_元组(self,tup):804 try:--
~\anaconda3\lib\site-包\熊猫\core\indexing.py在_getitem_lowerdim(自我,tup)927为i,键在枚举(tup): 928如果is_label_like(键)或is实例(键,元组):-
~\Anaconda3\lib\site packages\pandas\core\index。py在_getitem_轴(self、key、axis)1848中#通过直线查找1849 self_验证_键(键,轴)-
~\Anaconda3\lib\site-包\熊猫\核心\indexing.py在_get_label(自我,标签,轴)158引发索引错误("这里没有切片,在其他地方处理")159-
~\Anaconda3\lib\site-包\熊猫\核心\generic.py在xs(自我,键,轴,水平,drop_level)3735 loc,new_index=self.index.get_loc_level(键,drop_level=drop_level)3736
~\Anaconda3\lib\site packages\pandas\core\index\base。py在get_loc(自身、键、方法、公差)2897返回自身_发动机获取位置(钥匙)2898`
共有2个答案

试试这个
off_data.index = off_data.index.str.strip()
off_data.loc[off_data.index == "Louisville"]
编辑
如果在读取dataframe.you时需要删除空格,可以使用skip0019 alspace=True。这将跳过分隔符后的空格。
df1 = pd.read_csv(.. skipinitialspace=True)
或者需要删除特定列的空格,可以这样使用
df["column_name"] = df["column_name"].str.strip()
或者也可以使用rstrip或lstrip。
从左侧开始,从序列/索引中的每个字符串中删除空白(包括换行符)或一组指定的字符。
rstrip,从右侧删除序列/索引中每个字符串的空白(包括换行符)或一组指定字符。

您可以通过以下方式获取行:
off_data.loc[off_data['Team'] == "Louisville"]
你做位置的方式,需要列名,通过你的输出显示为团队,你可以尝试这些,看看他们是否工作:
In [4496]: df2.loc[0,"Team"]
Out[4496]: 'Michigan'
In [4497]: df2.loc[1,"Team"]
Out[4497]: 'Louisville'
看起来数据中有空白,这里有一个快速的方法来去除最后的空白:
off_data.index = off_data.index.str.strip()
这应该让你做一个搜索是:
off_data[off_data.index == 'Louisville']
-
我正在尝试基于第二个数据框的值周围的范围创建一个数据框的子集,我一直在进行研究,但我就是想不出如何去做。我在这里使用了虚拟数据,因为它们都是包含许多列的大型数据集。 数据帧1(df1)有50列,数千条不同纬度的记录 数据帧2(df2)有数百个城镇,都位于不同纬度,比df1小得多 我需要df1的一个子集,它只包括纬度在df2纬度0.01范围内的行。所以代码需要查看df1的每一行,并根据df2的每一行
-
我和Spark一起在Databricks上工作。编程语言是Scala。 我有两个数据帧: 主数据框:见截图:1 查找数据帧:参见屏幕截图3 我想: 查找主数据框中“年龄”=-1的所有行 我对如何做这件事伤了脑筋。我唯一想到的是将dataframe存储为DataRicks中的表,并使用SQL语句(SQL.Context.SQL…),结果非常复杂。 我想知道是否有更有效的方法。 编辑:添加可复制的示例
-
我是熊猫数据框的新手,我想应用一个函数,在同一列中取几行。就像当你应用函数diff(),但我想计算文本之间的距离。所以我定义了一个测量距离的函数,我试图使用应用,但我不知道如何选择几行。下面我展示了一个我尝试过的例子和我所期望的: 但它不起作用。我想得到的是: 提前感谢您为我提供的任何帮助。
-
我有3个数据帧。第一数据帧(例如df1)具有多行和多列。第二和第三数据帧(例如df2和df3)仅具有来自DF1的一行和列的子集。df2和df3中的列名相同。所以我要做的是将df1中的每一行与df2和DF3中的单行进行比较。如果来自df1的单元格的值与df2的单元格内容匹配,则将df1中单元格的值替换为1;如果来自df1的单元格的值与df3匹配,则将df1中单元格的值替换为2;如果df2的单元格内容
-
我想替换一行数据的每个值。帧,对于大小相等的逻辑矩阵,其值为TRUE,由向量的对应行的值确定。以下是一个例子: 所以结果应该是这样的: 有没有不使用循环的方法来实现这一点?谢谢
-
我试图计算数据中几列(第一列除外)的平均值和标准差。具有<code>NA<code>值的帧。 我试过< code>colMeans、< code > sappy 等。,创建一个循环,遍历data.frame,然后将平均值和标准偏差存储在一个单独的表中,但不断得到一个“有趣的”错误。任何帮助都是巨大的。谢谢 一个