
在python中读取德语csv文件的问题

我有一个德语csv文件,我想用pd阅读。读取\u csv。
数据:
原始文件如下所示:
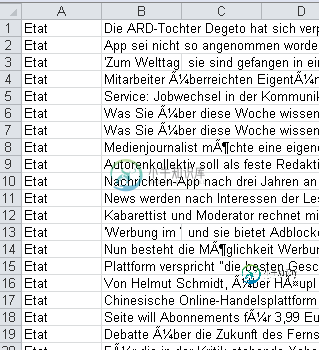
所以它有两个列(A,B),分隔符应该是';',
问题:当我运行命令时:
dataset = pd.read_csv('C:/Users/.../GermanNews/articles.csv',
encoding='utf-8', header=None, sep=';')
我得到的错误:ParserError:错误标记化数据。C错误:第3行中预期2个字段,锯3
半解决方案:我知道这可能有几个原因,但当我运行命令时:
dataset = pd.read_csv('C:/Users/.../GermanNews/articles.csv',
encoding='utf-8', header=None, sep='delimiter')
我将返回以下数据集:
0
0 Etat;Die ARD-Tochter Degeto hat sich verpflich...
1 Etat;App sei nicht so angenommen worden wie ge...
2 Etat;'Zum Welttag der Suizidprävention ist es ...
3 Etat;Mitarbeiter überreichten Eigentümervertre...
4 Etat;Service: Jobwechsel in der Kommunikations...
所以我只得到一列,而不是两个想要的列,
目标:任何想法如何正确加载数据集,我有:
0 1
0 Etat Die ARD-Tochter Degeto hat sich verpflich...
1 Etat App sei nicht so angenommen worden wie ge...
提示/尝试:
当我在excel中对我的数据运行搜索功能时,我也没有找到任何
在其中。
看起来有些行的列数超过了两列(如我的示例的第3行和第13行所示)
共有3个答案

这对我有效:
import pandas as pd
df = pd.read_csv('german.txt', sep=';', header = None, encoding='iso-8859-1')
df
输出:
0 1
0 Etat Die ARD-Tochter Degeto hat sich verpflich...
1 Etat App sei nicht so angenommen worden wie ge...
2 Etat 'Zum Welttag der Suizidprävention ist es ...
3 Etat Mitarbeiter überreichten Eigentümervertre...
4 Etat Service: Jobwechsel in der Kommunikations...

一种可能的解决方案是创建一列DataFrame,在数据中不使用分隔符,如delimiter,然后使用序列。str.split带有n参数和expand=True用于新的DataFrame:
dataset = pd.read_csv('C:/Users/.../GermanNews/articles.csv',
encoding='utf-8', header=None, sep='delimiter')
#more general solution is use some value NOT exist in data like yen ¥
#dataset = pd.read_csv('C:/Users/.../GermanNews/articles.csv',
# encoding='utf-8', header=None, sep='¥')
df = dataset[0].str.split(';', n=1, expand=True)
df.columns = ['A','B']
print (df)

仔细浏览课文。如果没有找到潜在客户,请遵循以下解决方案。
我只是这样读了一遍,然后通过在第一次出现分隔符时进行拆分,将字符串拆分为两个所需的列。
df['col1'] = df[0].str.split(';', 1).str[0]
df['col2'] = df[0].str.split(';', 1).str[1]
输出:
0 col1 col2
0 Etat;Die ARD-Tochter.. Etat Die ARD-Tochter
1 Etat;App sei nicht... Etat App sei nicht
2 Etat;Mitarbeiter überreich.. Etat Mitarbeiter überreich
我只是整理了一下文本来演示这个例子。
-
问题内容: 我有一个CSV文件,下面是其外观示例: 我知道如何读取文件并打印每列(例如- )。但是我真正想做的是读取行,就像这样,然后依此类推。 然后,我想将这些数字存储到变量中,以便稍后将它们总计(例如): 。那我可以做。 我将如何在Python 3中做到这一点? 问题答案: 您可以执行以下操作: 要么 : 编辑:
-
我正试图从压缩的csv文件中获取数据。有没有一种方法可以做到这一点,而不解压整个文件?如果没有,我如何解压文件并有效地读取它们?
-
我使用Jmeter和Selenium Webdriver采样器 代码CSV配置 我的问题是它没有从CSV中挑选。以上两行生成结果“loginName”,而不是从文件中选择实际的登录名。我用过单引号、双引号等,但运气不佳。使用${loginName}会产生错误。知道什么地方出了问题,如何解决吗?
-
我正在运行一个程序,可以处理30000个类似的文件。他们中的一些人正在停止并产生这个错误...
-
问题内容: 我正在从包含以下数据的CSV文件(xyz.CSV)中读取数据: 当我使用循环对其进行迭代时,我可以按以下代码逐行打印数据,并且仅打印column1数据。 通过上面的代码,我只能得到第一列。 如果我尝试打印line [1]或line [2],则会出现以下错误。 请建议打印列2或列3的数据。 问题答案: 这是我获得第二列和第三列的方法: 结果如下:
-
问题内容: 我目前正在尝试从Python 2.7中的.csv文件中读取数据,该文件最多包含100万行和200列(文件范围从100mb到1.6gb)。对于少于300,000行的文件,我可以(非常缓慢地)执行此操作,但是一旦超过该行,就会出现内存错误。我的代码如下所示: 在getstuff函数中使用else子句的原因是,所有符合条件的元素都将一起列在csv文件中,因此,经过它们以节省时间时,我离开了循