
SQLite根据另一列的值拆分列

我有一个数据库,其中多个变量显示为连续的行(如下所示,变量由其标记区分)。因此,它们的值在“值”列中显示为连续行。
现有表格:
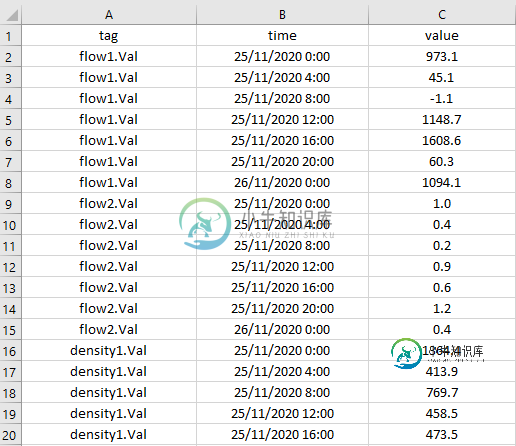
对于数据分析,我需要将每个变量的值拆分为单独的列,如下所示。
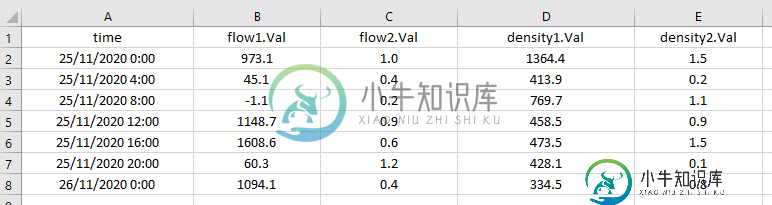
下面列出了SQLite查询。我曾尝试使用分组标记并平均值,但结果变得过于细粒度,无法使用。
建议将不胜感激!
SELECT
tag
,time
,value
FROM
[archive]..[interp]
WHERE
tag
IN
( 'flow1.Val'
, 'flow2.Val'
, 'density1.Val'
, 'density2.Val'
)
AND
time
BETWEEN
't-1d' and 't'
AND
timestep = '1h'
共有1个答案

您可以使用条件聚合:
select time,
max(case when tag = 'flow1.Val' then value end) as flow1_val,
max(case when tag = 'flow2.Val' then value end) as flow2_val,
max(case when tag = 'density1.Val' then value end) as density1_val,
max(case when tag = 'density2.Val' then value end) as density2_val
from [archive]..[interp]
group by time
根据您的实际需求,如果给定的时间/标记元组有多行,则可能需要使用另一个聚合函数而不是max()。
-
问题内容: 我试图根据该行的单元格中的值将其分为两行。例如,我具有以下表结构(这是一个临时表,没有任何键,索引或任何其他内容,我可以在另一个临时表中选择拆分结果): 然后,应将其拆分为: 问题答案: 我将使用
-
问题内容: 我在包含一个大字符串的表中有一个 文本 字段,我要分离的字符串的每个部分都被一个小方块分开。 搜索时,我发现这可能是一个ascii值,所以我运行了它 返回 27 如何根据此ascii值将该字段拆分为单独的字段? 预先感谢克里斯 编辑:当前数据看起来像什么的例子。如果可能的话,将TEXT放在=之前作为标题将非常有用。 ABS_ID = 1234567 PERSON_ID = 123456
-
问题内容: 我有一个名为Vendor的表,在此表中有一个名为AccountTerms的列,该列仅显示一个值(即0、1、2、3),依此类推。我也有一个要使用()的列,以反映该值的含义,例如: 等等… 我需要的是一个脚本,它将查看AccountTerms中的值,然后将更新以显示上面显示的单词值。我该怎么做呢? 问题答案: 我将尝试以一种尽可能简单的方式来解释这一点,以便于理解: 假设您有一个这样的表设
-
问题内容: 我有下表。 我想选择的每一个具有最低。 当我得到所需的内容后,一旦添加了列,就需要将其也添加到GROUP BY子句,当我需要的只是每种类型的最低要求时,它返回所有行。 问题答案: 在标准SQL中,这可以使用窗口函数来完成 但是,Postgres具有运算符,该运算符通常比带有窗口函数的相应解决方案要快:
-
问题内容: 我需要基于Pandas数据框中的另一列的值来设置一列的值。这是逻辑: 我无法做到这一点,我想要做的就是简单地创建一个具有新值的列(或更改现有列的值:任何一个都对我有用)。 如果我尝试运行上面的代码,或者将其编写为函数并使用apply方法,则会得到以下信息: 问题答案: 一种方法是将索引与配合使用。 例 在没有示例数据框的情况下,我将在此处进行补充: 假设您想 创建一个新列 ,除wher
-
问题内容: 我有这样的桌子 我需要选择何时类型为0,何时类型为1,何时类型为N … 我怎样才能做到这一点? 问题答案: