《hive》专题
-
使用JDBC从Java连接到Hive
问题内容: 我正在尝试从Java连接到Hive服务器1。很久以前我在这个论坛上发现了一个问题,但这对我不起作用。我正在使用此代码: 这就是指南中显示的代码。我已经在.java的同一路径中复制了hive- metastore,service,jdbc,exec,core和更多.jar。当我编译它时,我得到以下消息: 有人知道这里发生了什么吗? 问题答案: 尝试 代替 希望您在代码中添加了语句
-
使用Hiveserver2 Thrift Java客户端时请求挂起
问题内容: 这是该问题的后续问题,在这里我问什么是Hiveserver 2旧版Java客户端API。如果您不需要更多背景信息,那么这个问题应该能够在没有背景的情况下得以解决。 找不到有关如何使用hiverserver2旧版api的任何文档,我将它们放在一起。我能找到的最佳参考是Apache JDBC实现 。 我针对使用以下代码创建的Hiverserver2实例运行此代码 调试时,我从不走线 客户端
-
Hive 2.1.1 MetaException(在metastore中找不到消息:版本信息。)
问题内容: 我在Ubuntu 16.04上运行Hadoop 2.7.3,MySQL 5.7.17和Hive 2.1.1。 当我运行./hive时,我不断收到以下警告和异常: 这是我的hive-site.xml 为了解决该错误,我尝试了Hive无法实例化org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient和无法实例化org.apa
-
使用Hive将数据插入Hbase(JSON文件)
问题内容: 我已经使用hive在hbase中创建了一个表: 并创建了另一个表来加载数据: 最后将数据插入到hbase表中: 该表在hbase中如下所示: 我可以对JSON文件做同样的事情: 并做: 请帮忙 !:) 问题答案: 您可以使用该函数将数据解析为JSON对象。例如,如果您使用JSON数据创建登台表: 然后使用提取要加载到表中的属性: 有此功能的更全面的讨论在这里。
-
Hive中存放是什么?
本文向大家介绍Hive中存放是什么?相关面试题,主要包含被问及Hive中存放是什么?时的应答技巧和注意事项,需要的朋友参考一下 表。 存的是和hdfs的映射关系,hive是逻辑上的数据仓库,实际操作的都是hdfs上的文件,HQL就是用sql语法来写的mr程序。
-
Hive与关系型数据库的关系?
本文向大家介绍Hive与关系型数据库的关系?相关面试题,主要包含被问及Hive与关系型数据库的关系?时的应答技巧和注意事项,需要的朋友参考一下 没有关系,hive是数据仓库,不能和数据库一样进行实时的CURD操作。 是一次写入多次读取的操作,可以看成是ETL工具。
-
hive-shell批量命令执行脚本的实现方法
本文向大家介绍hive-shell批量命令执行脚本的实现方法,包括了hive-shell批量命令执行脚本的实现方法的使用技巧和注意事项,需要的朋友参考一下 如下所示: 以上这篇hive-shell批量命令执行脚本的实现方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。
-
Json使用Java将对象转换为Parquet格式而不转换为AVRO(不使用Spark,Hive,Pig,Impala)
问题内容: 我有一个场景,其中使用Java将作为Json对象存在的消息转换为Apache Parquet格式。任何示例代码或示例都将有所帮助。据我发现将消息转换为Parquet的内容,正在使用Hive,Pig,Spark。我需要转换为Parquet,而无需Java参与。 问题答案: 要将JSON数据文件转换为Parquet,您需要一些内存表示形式。Parquet没有自己的Java对象集。相反,它重
-
如何在Hive中生成所有n-gram
问题内容: 我想使用HiveQL创建一个n-gram列表。我的想法是使用带正则表达式和split函数的正则表达式-但这不起作用,但是: 输入是表格的一列 输出应该是: Hive中有一个n-gram udf,但是该函数直接计算n-gram的频率-我想改为列出所有n-gram的列表。 在此先多谢! 问题答案: 这可能不是最佳的解决方案,但却是可行的解决方案。用定界符分割句子(在我的示例中是一个或多个空
-
Hive中的窗口功能
问题内容: 我正在探索Hive中的窗口功能,并且能够理解所有UDF的功能。虽然,我无法理解我们与其他功能配合使用的分区和顺序。以下是与我计划构建的查询非常相似的结构。 只是试图了解两个关键字都涉及的后台过程。 感谢帮助:) 问题答案: 分析函数为数据集中每个分区的每一行分配一个等级。 子句确定行的分布方式(如果是配置单元,则在缩减程序之间)。 确定行在分区中的排序方式。 第一阶段由分配 ,数据集中
-
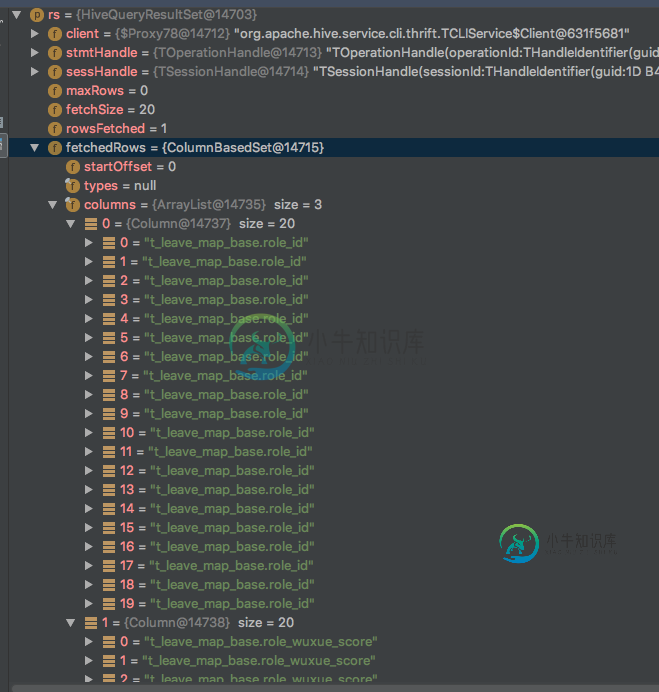 Spark-sql读取hive表失败
Spark-sql读取hive表失败我想通过配置单元jdbc连接将整个配置单元表加载到spark内存中。并且已经添加了配置单元站点。xml,hdfs站点。xml在我的项目中。spark已连接配置单元,因为已成功获取列名(例如role_id)。但是spark似乎将列名作为数据加载,并抛出异常。这是我的密码: 和获取错误: JAVAlang.NumberFormatException:对于输入字符串:“t_leave_map_base.
-
如何优化Spark作业将S3文件处理到Hive Parquet表中
null 应用程序读取所有S3文件=>重新分区到文件数量的两倍=>缓存RDD=>自定义处理每行=>创建临时视图/缓存表=>计数num行=>选择数据子集=>减少分区数量=>创建数据子集的视图=>使用视图插入配置单元目标表=>取消RDD持久化。 我不确定为什么执行要花很长时间。是spark执行参数设置不正确,还是这里调用了一些错误的东西?
-
Java-从MySQL到Hive导入,其中MySQL在Windows上运行,而Hive在Cent OS上运行(Horton Sandbox)
问题内容: 我通过命令行在Horton Sandbox中进行了尝试并成功。 其中192.168.56.101适用于Windows,而192.168.56.102适用于Horton Sandbox 2.6。 现在,我想在Java中做同样的事情,使Java代码在其他地方运行,但不在Horton沙箱中运行。 如何定位HIVE_HOME和其他Sqoop参数,因为它们正在沙盒中运行。 我必须传递的参数。它应
-
相关软件介绍/Hive/关于Hive建表需要注意的问题
一、环境 1、Hadoop 0.20.2 2、Hive 0.5.0 3、JDK 1.6 4、操作系统:Linux m131 2.6.9-78.8AXS2smp #1 SMP Tue Dec 16 02:42:55 EST 2008 x86_64 x86_64 x86_64 GNU/Linux 二、注意事项 1、关于数字类型支持的位数 类型 支持数字位数 tinyint 3位数字 smallint
-
相关软件介绍/Hive/UDF和UDAF简述
一、UDF 1、背景:Hive是基于Hadoop中的MapReduce,提供HQL查询的数据仓库。Hive是一个很开放的系统,很多内容都支持用户定制,包括: a)文件格式:Text File,Sequence File b)内存中的数据格式: Java Integer/String, Hadoop IntWritable/Text c)用户提供的 map/reduce 脚本:不管什么语言,利用 s