
如何根据一列中的唯一值在另一列中建立索引

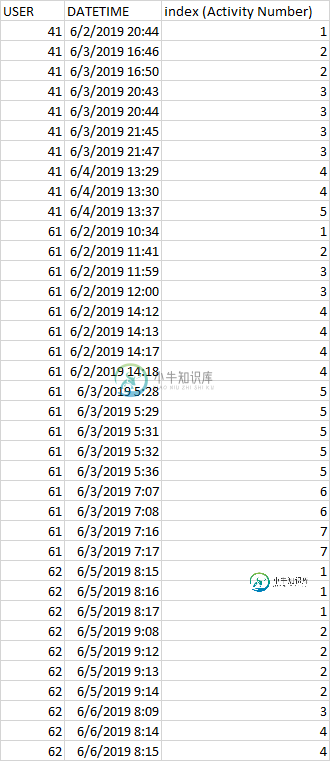
我有一个数据集DF,其中包括USER和DATETIME两列(列索引不在我的数据中。它是输出应该是什么样子)。DF中的行显示了每一分钟的活动。我想要的是创建并填充一个名为“index”的列。这个索引是显示等于或小于4分钟的活动。换句话说,如果第i行的DATETIME与其后面的第i 1行之间的差异小于或等于4分钟,则它们在同一个索引中(即在同一个活动中)。但是,如果这个差异大于4分钟,下一行(i 1)进入下一个活动,依此类推。这里很重要。我不需要DATETIMES之间差异的代码。我这里有。我想要的是一个for循环,为每个唯一的USER索引活动。然后,对于下一个USER,它应该从1开始。这是我尝试过的。但是我需要一个for in for循环或唯一函数。输出应该看起来像“索引”列。感谢您的帮助。
suum <- 1
DF$index[1] <- 1
for (k in unique(DF$USER))
{
for (i in 2:(nrow(DF)))
{
if(as.numeric(difftime(ymd_hms(DF$DATETIME[i]), ymd_hms(DF$DATETIME[i-1]), units = "mins") <= 4))
{ DF$index[i] <- suum }
else if(as.numeric(difftime(ymd_hms(DF$DATETIME[i]), ymd_hms(DF$DATETIME[i-1]),units = "mins") > 4))
{DF$index[i] <- suum + 1}
suum <- as.numeric(DF$index[i])
}
}
感谢@Paul van Oppen以R格式提供我的数据
data <- tibble(USER = c(rep(41, 10), rep(61, 6)),
DATETIME = as.POSIXct(c("2019/06/02 20:44:00", # 41
"2019/06/03 16:46:00",
"2019/06/03 16:50:00",
"2019/06/03 20:43:00",
"2019/06/03 20:44:00",
"2019/06/03 21:45:00",
"2019/06/03 21:47:00",
"2019/06/04 13:29:00",
"2019/06/04 13:30:00",
"2019/06/04 13:37:00",
"2019/06/02 10:34:00", # 61
"2019/06/02 11:41:00",
"2019/06/02 11:59:00",
"2019/06/02 12:00:00",
"2019/06/02 14:12:00",
"2019/06/02 14:13:00"),
"%Y/%m/%d %H:%M:%S", tz = "UTC")
)
共有2个答案

这能行吗?
首先创建数据对象(建议为<code>DATETIME</code>列使用适当的日期时间格式,如<code>POSIXct</code>):
library(dplyr)
library(tibble)
data <- tibble(
USER = c(rep(41, 10), rep(61, 6)),
DATETIME = as.POSIXct(c("2019/06/02 20:44:00", # 41
"2019/06/03 16:46:00",
"2019/06/03 16:50:00",
"2019/06/03 20:43:00",
"2019/06/03 20:44:00",
"2019/06/03 21:45:00",
"2019/06/03 21:47:00",
"2019/06/04 13:29:00",
"2019/06/04 13:30:00",
"2019/06/04 13:37:00",
"2019/06/02 10:34:00", # 61
"2019/06/02 11:41:00",
"2019/06/02 11:59:00",
"2019/06/02 12:00:00",
"2019/06/02 14:12:00",
"2019/06/02 14:13:00"),
"%Y/%m/%d %H:%M:%S", tz = "UTC")
)
然后,我使用 lag 函数计算与前一行的时间差,并使用 ifelse 创建一个标记列,突出显示那些以分钟为单位的时间差大于 4 的行。标记列的 cumsum 1 应该是您要查找的索引。按用户分组允许我们按组进行计算。最后,我们去掉中间列标记。
data <- data %>%
group_by(USER) %>%
mutate(diff_time = DATETIME - lag(DATETIME, 1)) %>%
mutate(marker = ifelse(as.numeric(diff_time > 4), 1, 0)) %>%
mutate(marker = replace_na(marker, 0)) %>%
mutate(index = cumsum(marker) + 1) %>%
select(USER, DATETIME, index)
> data
# A tibble: 16 x 3
# Groups: USER [2]
USER DATETIME index
<dbl> <dttm> <dbl>
1 41 2019-06-02 20:44:00 1
2 41 2019-06-03 16:46:00 2
3 41 2019-06-03 16:50:00 2
4 41 2019-06-03 20:43:00 3
5 41 2019-06-03 20:44:00 3
6 41 2019-06-03 21:45:00 4
7 41 2019-06-03 21:47:00 4
8 41 2019-06-04 13:29:00 5
9 41 2019-06-04 13:30:00 5
10 41 2019-06-04 13:37:00 6
11 61 2019-06-02 10:34:00 1
12 61 2019-06-02 11:41:00 2
13 61 2019-06-02 11:59:00 3
14 61 2019-06-02 12:00:00 3
15 61 2019-06-02 14:12:00 4
16 61 2019-06-02 14:13:00 4

使用 dplyr,无需循环:
library(dplyr)
data %>%
group_by(USER) %>%
mutate(
INDEX = cumsum(
c(1, difftime((DATETIME), lag(ymd_hms(DATETIME), 1), units = "mins")[-1] > 4)
)
)
# # A tibble: 16 x 3
# # Groups: USER [2]
# USER DATETIME INDEX
# <dbl> <dttm> <dbl>
# 1 41 2019-06-02 20:44:00 1
# 2 41 2019-06-03 16:46:00 2
# 3 41 2019-06-03 16:50:00 2
# 4 41 2019-06-03 20:43:00 3
# 5 41 2019-06-03 20:44:00 3
# 6 41 2019-06-03 21:45:00 4
# 7 41 2019-06-03 21:47:00 4
# 8 41 2019-06-04 13:29:00 5
# 9 41 2019-06-04 13:30:00 5
# 10 41 2019-06-04 13:37:00 6
# 11 61 2019-06-02 10:34:00 1
# 12 61 2019-06-02 11:41:00 2
# ...
(当然是未经测试的,因为我无法导入你的数据图片。如果您以有效的R语法共享数据,例如< code>dput(DF[1:20,]),我会很乐意进行测试和调试。)
-
问题内容: 我有一个名为Vendor的表,在此表中有一个名为AccountTerms的列,该列仅显示一个值(即0、1、2、3),依此类推。我也有一个要使用()的列,以反映该值的含义,例如: 等等… 我需要的是一个脚本,它将查看AccountTerms中的值,然后将更新以显示上面显示的单词值。我该怎么做呢? 问题答案: 我将尝试以一种尽可能简单的方式来解释这一点,以便于理解: 假设您有一个这样的表设
-
问题内容: 我需要基于Pandas数据框中的另一列的值来设置一列的值。这是逻辑: 我无法做到这一点,我想要做的就是简单地创建一个具有新值的列(或更改现有列的值:任何一个都对我有用)。 如果我尝试运行上面的代码,或者将其编写为函数并使用apply方法,则会得到以下信息: 问题答案: 一种方法是将索引与配合使用。 例 在没有示例数据框的情况下,我将在此处进行补充: 假设您想 创建一个新列 ,除wher
-
我有两个熊猫数据框 步骤1:根据df1中唯一的“val”在df2中创建列,如下所示: 步骤2:对于flag=1的行,AA_new将计算为var1(来自df2)*组“A”和val“AA”的df1的'cal1'值*组“A”和val“AA”的df1的'cal2'值,类似地,AB_new将计算为var1(来自df2)*组“A”和val“AB”的df1的'cal1'值*组“A”和val“AB”的df1的'c
-
问题内容: 我有一个清单说。我想为每个唯一值分配一个特定的“索引”来获取。 这是我的代码: 事实证明这很慢。 具有1M个元素和100K个唯一元素。我也尝试过用lambda和sort进行地图操作,这没有帮助。这样做的理想方法是什么? 问题答案: 由于执行线性搜索,然后对中的每个元素执行线性搜索,因此导致代码变慢。因此,对于每1M个项目,您要进行(最多)100K个比较。 将一个值转换为另一个值的最快方
-
问题内容: 我有下表。 我想选择的每一个具有最低。 当我得到所需的内容后,一旦添加了列,就需要将其也添加到GROUP BY子句,当我需要的只是每种类型的最低要求时,它返回所有行。 问题答案: 在标准SQL中,这可以使用窗口函数来完成 但是,Postgres具有运算符,该运算符通常比带有窗口函数的相应解决方案要快:
-
问题内容: 不知道在PostgreSQL 9.3+中是否可行,但是我想在非唯一列上创建唯一索引。对于像这样的表: 我想仅能[快速]查询不同的日子。我知道我可以用来帮助执行不同的搜索,但是如果不同值的数量大大少于索引覆盖的行数,这似乎会增加额外的开销。就我而言,大约30天中有1天与众不同。 我是创建关系表以仅跟踪唯一条目的唯一选择吗?思维: 并在每次插入数据时使用触发器来更新它。 问题答案: 索引只