
按[duplicate]分组后将数据帧转换为数据透视表

我有一个数据框,在完成分组后得到,如下所示:-
data = [[1,'US', 10], [1,'CA', 15], [1,'IN', 14],
[2,'US', 15], [2,'CA', 9], [2,'IN', 1],
[3,'US', 16], [3,'CA', 8], [3,'IN', 33]]
# Create the pandas DataFrame
df = pd.DataFrame(data, columns = ['fan', 'country','value'])
# print data frame.
df
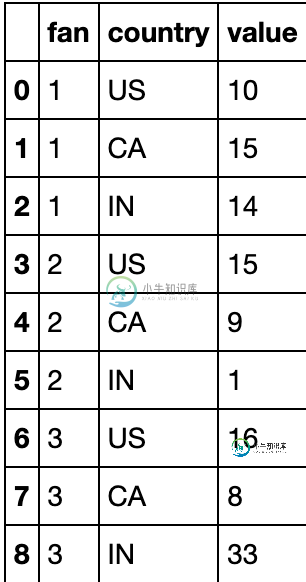
我想将其转换为:-

共有1个答案

您只需要枢轴:
>>> df.pivot(index="country", columns="fan", values="value").reset_index()
fan country 1 2 3
0 CA 15 9 8
1 IN 14 1 33
2 US 10 15 16
-
我正在尝试将RDD[String]转换为数据框。字符串是逗号分隔的,所以我希望逗号之间的每个值都有一列。为此,我尝试了以下步骤: 但我明白了: 这不是这篇文章的副本(如何将rdd对象转换为火花中的数据帧),因为我要求RDD[字符串]而不是RDD[行]。 而且它也不是火花加载CSV文件作为DataFrame的副本?因为这个问题不是关于将CSV文件读取为DataFrame。
-
我有这个数据框 我想转换这种形式的Numpy数组: 我正在使用转换为_矩阵函数,并在它重塑(1,4)后使用,但它不起作用!!它给我的格式是:有什么建议吗?我需要把它转换成那种格式,这样我就可以应用“精确回忆曲线”功能。
-
我正在尝试将熊猫DF转换为Spark one。测向头: 代码: 我得到了一个错误:
-
我在火花中工作,要使用库的类,我需要将的内容转换为2D数组,即。 虽然我已经找到了很多关于如何将数据帧的单个列转换为数组的解决方案,但我不知道如何 将整个数据帧转换为2D数组(即数组数组); 这样做时,将其内容从长转换为双倍。 原因是我需要将数据帧的内容加载到Jama矩阵中,这需要一个2D的Double数组作为输入: 编辑:为了完整起见,df模式是: 有165列相同类型的
-
什么是透视? 如何透视? 这是枢轴吗? 长格式到宽格式? 我见过很多关于透视表的问题。即使他们不知道他们询问的是透视表,他们通常也是。几乎不可能写出一个包含旋转的所有方面的规范的问题和答案。 ...但我要试一试。 现有问题和答案的问题是,问题通常集中在一个细微差别上,而OP很难将其概括出来,以便使用现有的许多好答案。然而,没有一个答案试图给出一个全面的解释(因为这是一个令人生畏的任务) 从我的谷歌
-
问题内容: 我有一个要转换为json格式的数据框: 我的数据帧称为res1: 当我做: 我得到这个: 我需要这个json输出像这样,有什么想法吗? 问题答案: 怎么样 通过使用,我们实际上将大的data.frame分解为每一行的单独的data.frame。通过从结果列表中删除名称,该函数将结果包装在数组中,而不是命名对象中。