
R中的非累积分布函数

我有两个不同长度的向量,每个向量包含0到50之间的数字。有些数字在向量中不包含,其他数字可能出现多次。
a <- c(22, 11, 9, 15, 19, 14, 13, 17, 24, 21, 21, 19, 20, 23, 18, 20, 21, 15, 25, 11, 21, 19, 27, 20, 30, 11, 31, 28, 21, 24, 29, 13, 19, 13, 18, 18, 11, 29, 7, 21, 36, 21, 31, 24, 28, 36, 12, 21, 18, 27, 6, 23, 22, 25, 17, 15, 27, 9, 33, 14, 4, 15, 31, 27, 22, 25, 31, 23, 8, 23, 27, 21, 19, 17, 5, 29, 15, 26, 25, 30, 29, 5, 19, 12, 23, 8, 21, 20, 23, 19, 18, 40, 33, 17, 15, 25, 15, 15, 10, 9, 19, 11, 41, 14, 33, 5, 28, 15, 27, 16, 9, 5, 21, 19, 19, 29, 30, 8, 15, 20, 26, 17, 35, 18, 18, 26, 35, 33, 30, 11, 26, 21, 14, 20, 20, 23, 15, 21, 23, 15, 12, 8, 33, 13, 15, 5, 19, 12, 23, 18, 19, 15, 18, 16, 7, 19, 21, 23, 8, 10, 6, 5, 20, 19, 18, 13, 32, 14, 11, 14, 26, 28, 20, 9, 31, 19, 9, 23, 29, 12, 37, 17, 15, 13, 18, 23, 18, 10, 13, 18, 28, 8, 17, 18, 14, 14, 19, 23, 16, 30, 16, 16, 19, 13, 15, 25, 22, 36, 8, 26, 5, 2, 26)
b <- c(7, 2, 3, 11, 16, 1, 3, 9, 15, 27, 2, 5, 11, 13, 24, 29, 11, 6, 1, 2, 5, 4, 2, 1, 7, 3, 0, 26, 13, 2, 15, 14, 11, 12, 15, 10, 4, 24, 21, 3, 43, 12, 19, 5, 2, 30, 9, 3, 5, 8, 25, 5, 24, 16, 15, 7, 2, 28, 8, 1, 15, 11, 3, 19, 28, 7, 3, 16, 7, 19, 5, 7, 1, 21, 21, 4, 8, 11, 16, 27, 13, 9, 2, 5, 14, 10, 3, 4, 20, 10, 7, 1, 10, 13, 11, 12, 10, 9, 24, 4, 26, 7, 11, 14, 3, 2, 9, 5, 1, 6, 9, 8, 16, 23, 3, 5, 5, 23, 25, 14, 3, 7, 16, 1, 11, 4, 2, 8, 6, 2, 2, 2, 2, 16, 8, 5, 15, 14, 10, 7, 9, 13, 5, 10, 18, 1, 24, 1, 8, 14, 3, 16, 18, 13, 0, 0, 10, 3, 21, 10, 8, 4, 2, 2, 4, 1, 10, 10, 8, 5, 17, 19, 2, 6, 5, 5, 17, 13, 0, 1, 19, 2, 14, 24, 7, 4, 8, 9, 7, 9, 6, 15, 8, 3, 7, 9, 13, 20, 13, 1, 7, 6, 28, 2, 11, 7, 0, 14)
我想画一条线,显示每个数字在每个向量中包含的频率,即数字的频率。
如果我将中断设置为每个可能的数字之间,我可以绘制显示频率的直方图:
hist(a, breaks=seq(-0.5, 50.5, 1), xlim = c(0, 50), col = rgb(0,1,0,0.5))
par(new=TRUE)
hist(b, breaks=seq(-0.5, 50.5, 1), xlim = c(0, 50), col = rgb(1,0,1,0.5))
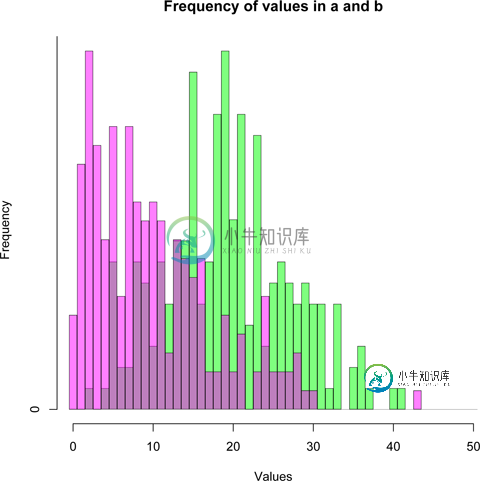
我知道有一个经验累积分布函数(ecdf()),它会形成一个S形;但我想要的是一个非累积的经验分布函数,它将导致类似阶梯形钟形曲线的结果,类似于直方图的轮廓。
我能得到的最接近的是绘制密度:
plot(density(a), xlim = c(-10, 50))
par(new=TRUE)
plot(density(b), xlim = c(-10, 50))
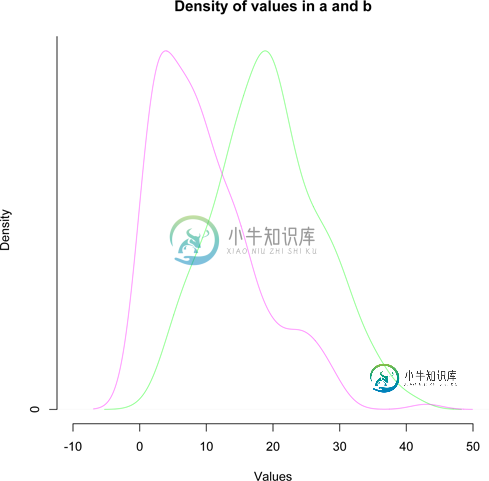
但这不是我想要的。我想要的是频率“曲线”。它应该是这样的(在Photohshop中徒手绘制):
那么如何才能做到频率“曲线”呢?
共有3个答案

尝试以下与ggplod:
dual = data.frame(grp='a', value=a)
dual2 = data.frame(grp='b', value=b)
dual3 = rbind(dual, dual2)
dd = data.frame(with(dual3, table(grp, value)))
> head(dd)
grp value Freq
1 a 0 0
2 b 0 5
3 a 1 0
4 b 1 13
5 a 2 1
6 b 2 19
ggplot(dd, aes(x=value, y=Freq, group=grp, fill=grp))+geom_bar(stat='identity', position='dodge')
ggplot(dd, aes(x=value, y=Freq, group=grp, color=grp))+geom_line()
ggplot(dd, aes(x=value, y=Freq, group=grp, color=grp))+stat_smooth()

使用ggplot2:
DF <- data.frame(x=c(a, b), g=c(rep("a", length(a)), rep("b", length(b))))
library(ggplot2)
ggplot(DF, aes(x=x, colour=g)) +
stat_bin(position="identity", breaks=seq(-0.5, 50.5, 1),
geom="errorbarh", aes(xmin=..x..-0.5, xmax=..x..+0.5), height=0, size=2) +
theme_bw() +
theme(legend.position="none")

像这样的?
ah <- hist(a, seq(-0.5, 50.5, 1), plot=FALSE)
bh <- hist(b, seq(-0.5, 50.5, 1), plot=FALSE)
plot(ah$breaks[-1], ah$counts, type="s", ylim=c(0, 100), xaxt="n")
lines(bh$breaks[-1], bh$counts, type="s", col="red")
axis(1, at=ah$breaks)
-
问题内容: 如何计算Python中正态分布的累积分布函数(CDF)的反函数? 我应该使用哪个库?可能是卑鄙的? 问题答案: NORMSINV(在注释中提到)是标准正态分布的CDF的倒数。使用,您可以使用对象的方法进行计算。首字母缩写词代表 百分比点函数 ,它是 分位数函数的 另一个名称。 检查它是否与CDF相反: 默认情况下,使用mean = 0和stddev = 1,这是“标准”正态分布。您可以
-
问题内容: 我想用NumPy创建CDF,下面是我的代码: 我正在阵列旁走,但是需要很长时间执行程序。这个功能有一个内置的功能,不是吗? 问题答案: 我不太确定您的代码在做什么,但是如果您有和返回的数组,则可以用来生成直方图内容的累积和。
-
我正在做一个关于象棋游戏的项目。在对数据进行一些处理之后,我需要得到一个特定位置的芬(https://en.wikipedia.org/wiki/Forsyth–Edwards_Notation)符号。我已经写好了每块FEN编码的代码,但是我很难对代表未被占据的连续方块的数量的字符进行编码。 例如,以以下FEN代码为例: 每个1代表棋盘内一个未被占用的方块。例如:告诉我们棋盘内的这一行没有被棋子占
-
问题内容: 在numpy或scipy(或其他库)中是否有一个函数将cumsum和cumprod的概念推广为任意函数。例如,考虑(理论上的)函数 func是一个接受两个浮点数并返回一个浮点数的函数。特殊情况 和 分别是cumsum和cumprod。例如,如果 我将其应用于: 我想要 问题答案: NumPy的ufunc有: 不幸的是,呼吁在“编Python函数失败,一个奇怪的错误: 这是将NumPy
-
我尝试过用这个方法来计算累积值,但是如果日期字段与累积字段中的值相同,那么有人能提出类似于这个问题的解决方案吗
-
我有一个,其中包含对项目进行抽样的概率(权重)。例如,包含如下所示的5个值。 我尝试了这样的方法,首先把概率列表做成累加形式。 0.1、0.5、0.7、0.8、1.0 那么我的做法如下。我生成一个随机double,并在列表上迭代以找到第一个大于随机double的项,然后返回它的索引。 我不确定二分搜索能有什么帮助。假设我生成了p=0.01。然后,二分搜索可以使用递归,如下所示。 0.01小于0.7