
AWS Sagemaker多模型endpoint与Scikit学习:使用培训脚本时出现意外状态异常

我试图使用Scikit学习和自定义训练脚本在AWS sagemaker中创建一个多模型endpoint。当我试图使用以下代码训练我的模型时:
estimator = SKLearn(
entry_point=TRAINING_FILE, # script to use for training job
role=role,
source_dir=SOURCE_DIR, # Location of scripts
train_instance_count=1,
train_instance_type=TRAIN_INSTANCE_TYPE,
framework_version='0.23-1',
output_path=s3_output_path,# Where to store model artifacts
base_job_name=_job,
code_location=code_location,# This is where the .tar.gz of the source_dir will be stored
hyperparameters = {'max-samples' : 100,
'model_name' : key})
DISTRIBUTION_MODE = 'FullyReplicated'
train_input = sagemaker.s3_input(s3_data=inputs+'/train',
distribution=DISTRIBUTION_MODE, content_type='csv')
estimator.fit({'train': train_input}, wait=True)
其中TRAINING_FILE包含:
import argparse
import os
import numpy as np
import pandas as pd
import joblib
import sys
from sklearn.ensemble import IsolationForest
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--max_samples', type=int, default=100)
parser.add_argument('--model_dir', type=str, default=os.environ.get('SM_MODEL_DIR'))
parser.add_argument('--train', type=str, default=os.environ.get('SM_CHANNEL_TRAIN'))
parser.add_argument('--model_name', type=str)
args, _ = parser.parse_known_args()
print('reading data. . .')
print('model_name: '+args.model_name)
train_file = os.path.join(args.train, args.model_name + '_train.csv')
train_df = pd.read_csv(train_file) # read in the training data
train_tgt = train_df.iloc[:, 1] # target column is the second column
clf = IsolationForest(max_samples = args.max_samples)
clf = clf.fit([train_tgt])
path = os.path.join(args.model_dir, 'model.joblib')
joblib.dump(clf, path)
print('model persisted at ' + path)
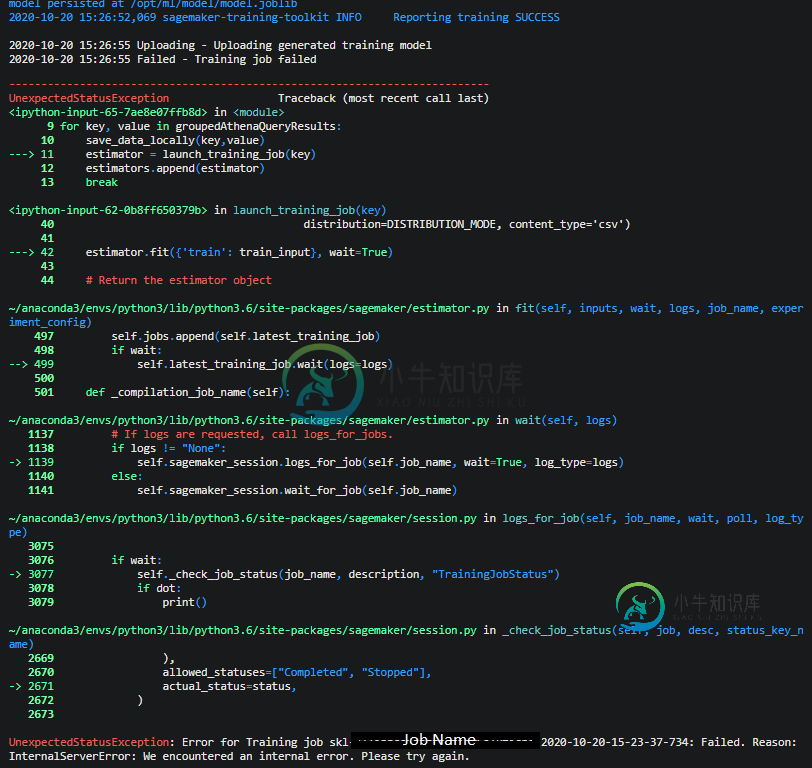
以前有人经历过这样的事情吗?我检查了所有的云观察日志,没有发现任何有用的东西,我完全不知道下一步该做什么。
共有1个答案

对任何将来遇到这个问题的人来说,这个问题已经解决了。
问题与训练无关,而是目录名称中的无效字符被发送到S3。所以脚本会正确地生成工件,但是sagemaker在试图将它们保存到S3时会抛出异常
-
问题内容: 我正在尝试从集群模块调用函数,如下所示: 我收到以下错误: 在IPython中,制表符补全似乎可以访问基本,克隆,外部,re,setup_module,sys和警告模块。sklearn目录中没有其他(包括群集)。 遵循以下pbu的建议并使用 我得到: 我在Windows上使用Python 3.4,scikit-learn 0.16.1。 问题答案: 问题是scipy / numpy安装
-
决策树(decision tree)是一种基本的分类与回归方法。决策树模型呈树形结构。通常包含3个步骤:特征选择、决策树的生成和决策树的修剪。 决策树模型 分类决策树树模型是一种描述对实例进行分类的树形结构。决策树由节点(node)和有向边(directed edge)组成。节点有两种类型:内部节点(internal node)和叶节点。内部节点表示一个特征或属性,叶节点表示一个类。 用决策树分类
-
我只是用TensorFlow训练了一个三层的softmax神经网络。它来自吴恩达的课程,3.11TensorFlow。我修改代码是为了查看每个历元的测试和训练精度。 当我增加学习率时,成本在1.9左右,而准确率保持1.66...7不变。我发现学习率越高,它发生的频率就越高。当learing_rate在0.001左右时,有时会出现这种情况。当learing_rate在0.0001附近时,这种情况不会
-
从sklearn加载流行数字数据集。数据集模块,并将其分配给可变数字。 分割数字。将数据分为两组,分别命名为X_train和X_test。还有,分割数字。目标分为两组Y_训练和Y_测试。 提示:使用sklearn中的训练测试分割方法。模型选择;将随机_状态设置为30;并进行分层抽样。使用默认参数,从X_序列集和Y_序列标签构建SVM分类器。将模型命名为svm_clf。 在测试数据集上评估模型的准确
-
我在Heroku上托管了一个Springboot应用程序。构建和部署工作得非常好。然而,每当我想访问该方法时,我都会看到这个错误<代码>出现意外错误(类型=错误请求,状态=400) 如果我使用loclhost,但使用Heroku的应用程序时抛出错误,那么它在Postman上运行得非常好。 这是控制器的样子。我猜这就是问题的来源。 . 你认为我能做些什么让api在Heroku上工作?
-
Spring我是新来的。我试图在我的数据库中添加一个新目标。在我添加spring security之前,它是有效的,但现在如果我单击添加新目标,我有一个问题: 出现意外错误(类型=禁止,状态=403)。被禁止的 我的goat-add.html: WebSecurity配置类: 我的控制器: 我读到这个问题可以是如果不使用csrf,但我不明白我怎么能解决它。 所有代码:https://github.