
为什么每个神经网络层都有一个激活函数,而不仅仅是最后一层?

我试图自学机器学习,我有一个类似的问题。
是否正确:
例如,如果我有一个输入矩阵,其中X1、X2和X3是三个数字特征(例如,假设它们是花瓣长度、茎长度、花长度,我试图标记样本是否是特定的花物种):
x1 x2 x3 label
5 1 2 yes
3 9 8 no
1 2 3 yes
9 9 9 no
您将上表的第一个ROW(不是列)的向量输入到网络中,如下所示:
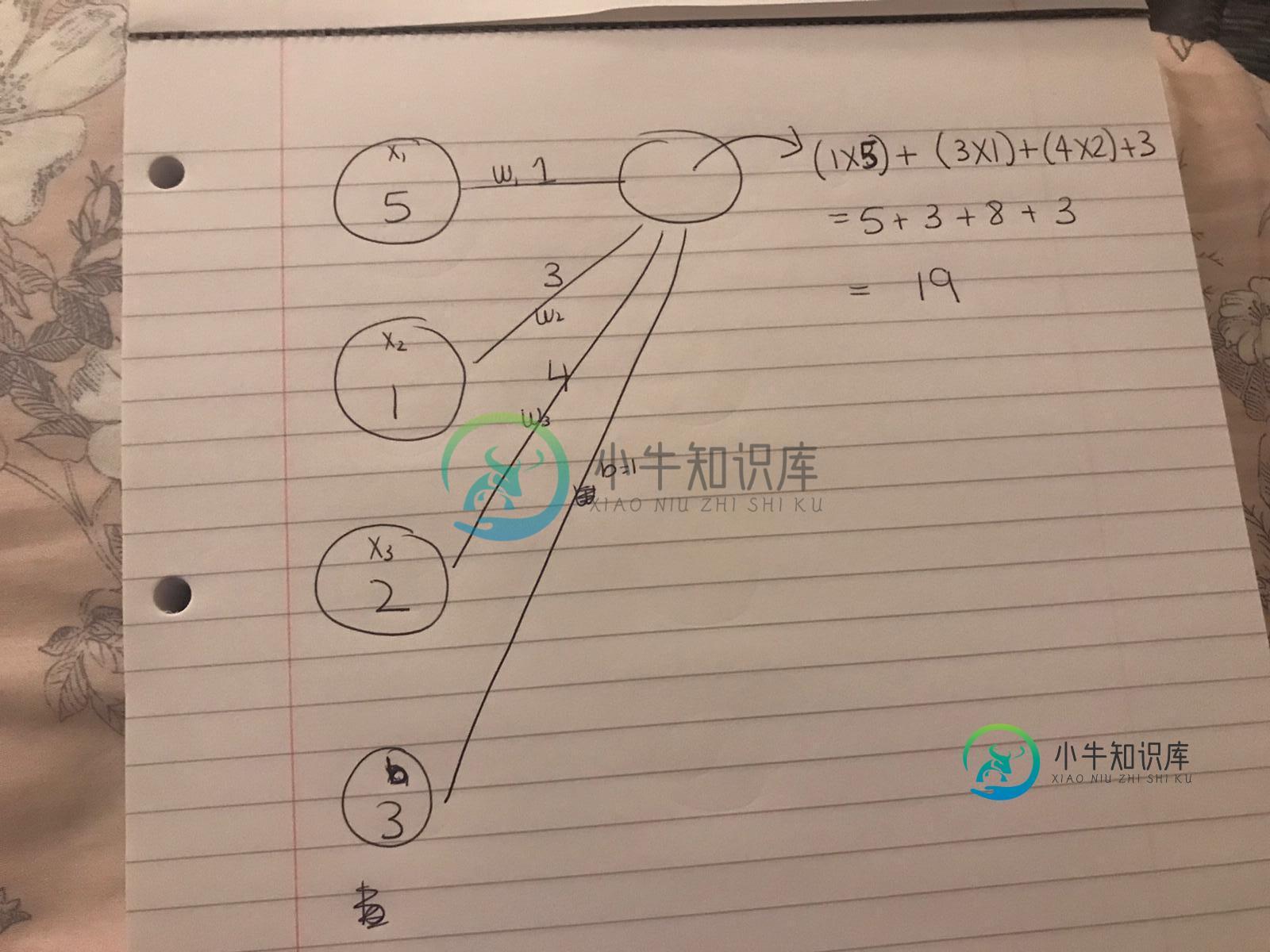
也就是说,将有三个神经元(第一个表行的每个值为1),然后随机选择w1、w2和w3,然后要计算下一列中的第一个神经元,您执行我描述的乘法,然后添加一个随机选择的偏置项。这给出了该节点的值。
这是为一组节点完成的(即每列实际上将有四个节点(三个偏置),为简单起见,我从第二列中删除了其他三个节点),然后在输出之前的最后一个节点中,有一个激活函数将总和转换为一个值(例如,sigmoid的0-1),该值告诉您分类是是还是不是。
我很抱歉这是多么的基本,我想真正了解这个过程,我是从免费资源来做的。因此,通常情况下,您应该选择网络中的节点数量为功能数量的倍数,例如,在这种情况下,编写以下内容是有意义的:
from keras.models import Sequential
from keras.models import Dense
model = Sequential()
model.add(Dense(6,input_dim=3,activation='relu'))
model.add(Dense(6,input_dim=3,activation='relu'))
model.add(Dense(3,activation='softmax'))
我不明白的是,为什么keras模型在网络的每一层都有激活功能,而不仅仅是在最后,这就是为什么我想知道我的理解是否正确/为什么我添加了图片。
编辑1:我只看到一个注释,在偏差神经元中,我在边缘上加了“b=1”,这可能会让人困惑,我知道偏差没有权重,所以这只是提醒我自己,偏差节点的权重是1。
共有3个答案

想象一下,你只有在最后一层有一个激活层(在你的情况下是sigmoid。它也可以是其他东西...比如softmax)。这样做的目的是将实值转换为0到1的范围,以获得分类排序的答案。但是,内部层(隐藏层)中的激活具有完全不同的目的。这是引入非线性。没有激活(例如ReLu、tanh等),你得到的是一个线性函数。你有多少个隐藏层,你最终仍然得到一个线性函数。最后,你在最后一层将其转换为非线性函数。这可能适用于一些简单的非线性问题,但无法捕获复杂的非线性函数。每个隐藏单元(在每一层中)都包含激活函数以包含非线性。

你的问题似乎是,为什么每一层都有激活功能,而不仅仅是最后一层。简单的答案是,如果中间没有非线性激活,无论你的网络有多深,都可以归结为一个线性方程。因此,非线性激活是使深度网络真正“深入”并学习高级功能的主要促成因素之一。
以下面的示例为例,假设您有三层神经网络,中间没有任何非线性激活,但有最后一层softmax。这些层的权重和偏差为(W1、b1)、(W2、b2)和(W3、b3)。然后,您可以编写网络的最终输出,如下所示。
h1 = W1.x + b1
h2 = W2.h1 + b2
h3 = Softmax(W3.h2 + b3)
让我们做一些操作。我们简单地将h3替换为x的函数,
h3 = Softmax(W3.(W2.(W1.x + b1) + b2) + b3)
h3 = Softmax((W3.W2.W1) x + (W3.W2.b1 + W3.b2 + b3))
换句话说,h3的格式如下。
<代码>h3=软最大值(W.x b)
因此,如果没有非线性激活,我们的三层网络已经被压缩为单层网络。这就是为什么非线性激活很重要。

除了标题中的问题,这里还有几个问题,但由于现在不是时候
因此,一般来说,您应该选择网络中的节点数量为功能数量的倍数,
不
特征数传递到参数input\u dim中,该参数仅为模型的第一层设置;除第一层外,每一层的输入数量只是前一层的输出数量。您编写的Keras模型无效,它将产生错误,因为对于第二层,您要求输入dim=3,而前一层显然有6个输出(节点)。
除了这个input_dim参数之外,数据特征的数量和网络节点的数量之间没有任何其他关系;既然您似乎想到了虹膜数据(4个特征),这里是一个简单的可复制的示例,将Keras模型应用于它们。
Keras sequential API(您在这里使用)中隐藏的是,实际上有一个隐式输入层,它的节点数就是输入的维度;有关详细信息,请参见Keras顺序模型输入层中的自己的答案。
因此,您在pad中绘制的模型实际上对应于使用顺序API编写的以下Keras模型:
model = Sequential()
model.add(Dense(1,input_dim=3,activation='linear'))
在功能API中,它将被写为:
inputs = Input(shape=(3,))
outputs = Dense(1, activation='linear')(inputs)
model = Model(inputs, outputs)
仅此而已,也就是说,它实际上只是线性回归。
我知道偏见没有份量
这种偏见确实有其影响力。同样,有用的类比是线性(或logistic)回归的常数项:偏差“输入”本身始终为1,其相应的系数(权重)通过拟合过程学习。
为什么keras模型在网络的每一层都有激活函数,而不仅仅是在末端
我相信这一点在另一个答案中已经充分涵盖。
我很抱歉这是多么的基本,我想真正了解这个过程,我是从免费资源来做的。
我们都做到了;虽然没有理由不从吴恩达的免费
-
我试着运行一个没有任何激活函数的简单神经网络,并且网络不会收敛。我正在使用MSE成本函数进行MNIST分类。 然而,如果我将校正线性激活函数应用于隐藏层(输出=max(0,x),其中x是加权和),那么它会很好地收敛。 为什么消除前一层的负面输出有助于学习?
-
本文向大家介绍问题:神经网络激活函数?相关面试题,主要包含被问及问题:神经网络激活函数?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: sigmod、tanh、relu 解析:需要掌握函数图像,特点,互相比较,优缺点以及改进方法
-
神经网络的输入层使用激活函数,还是仅仅是隐藏层和输出层?
-
对于一个Box2D组合,我需要这段代码来避免无意中的点击: null null 目前,它适用于整个文档。但我希望它仅适用于 。 怎么可能编码呢? 会非常感谢你的帮助!
-
我试图使用web控制台获取页面上所有h2标记中的文本。 我所发现的就是使用每一种,我已经试过了 但是它返回
-
我设计了卷积神经网络(tf.Keras),该网络具有很少的具有不同核大小的并行卷积单元。然后,将该卷积层的每个输出结果馈送到另一个并行的卷积单元中。然后将所有输出串联起来。下一次展平完成。之后,我添加了完全连接的层,并连接到最终的softmax层进行多类分类。我对它进行了培训,并在验证测试中取得了良好的结果。