
使用Java的ElasticSearch聚合

我想在我的java应用程序中获得聚合。
首先,我用curl构造了REST查询。它看起来像:
curl -XGET 'localhost:9200/analysis/_search?pretty' -H 'Content-Type:
application/json' -d'
{
"size": 0,
"query" : {
"bool": {
"must": [
{ "term" : { "customer_id" : 5117 } }
]
}
},
"aggs": {
"customer_id": {
"terms": {
"field": "customer_id",
"order": {
"contract_sum": "desc"
}
},
"aggs": {
"contract_sum": {
"sum": {
"field": "contract_sum"
}
}
}
}
}
}
'
结果和我预期的一样
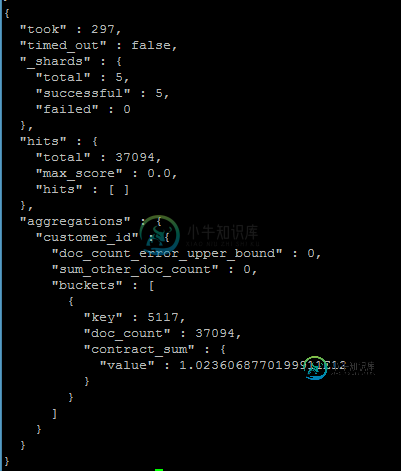
之后我在java中创建了一些代码
Settings settings = Settings.builder().put("cluster.name", elasticProperties.getElasticClusterName()).build();
log.info("Initializing ElasticSearch client");
try (TransportClient client = new PreBuiltTransportClient(settings).addTransportAddress(new InetSocketTransportAddress(
InetAddress.getByName(elasticProperties.getElasticTransportAddress()), elasticProperties.getElasticTransportPort()))) {
// Base query
log.info("Preparing query");
SearchRequestBuilder requestBuilder = client.prepareSearch(elasticProperties.getElasticIndexName())
.setTypes(elasticProperties.getElasticTypeName())
.setSize(Top);
// Add aggregations
AggregationBuilder aggregation =
AggregationBuilders
.terms("customer_id")
.field("customer_id")
//.order(Terms.Order.aggregation("customer_id", "contract_sum", false))
.subAggregation(
AggregationBuilders.sum("total_contract_sum")
.field("contract_sum")
);
requestBuilder.addAggregation(aggregation);
// Get response
log.info("Executing query");
SearchResponse response = requestBuilder.get();
log.info("Query results:");
Terms contractSums = response.getAggregations().get("customer_id");
for (Terms.Bucket bucket : contractSums.getBuckets()) {
log.info(" " + bucket.getKey() + " ");
}
问题是:
如何获取当前bucket项的“contract\u sum”聚合值?
当我在IntelliJ Idea中使用调试工具时,它似乎可以
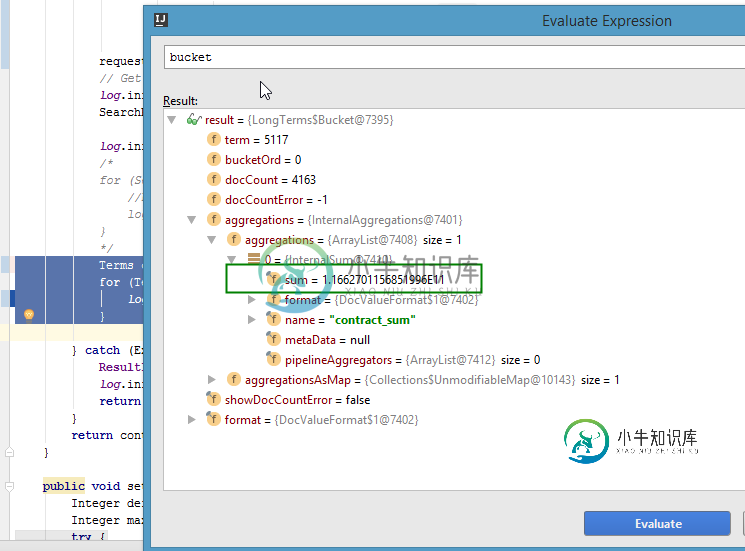
请帮助我的代码示例。
共有3个答案

public Map<String, Collection<Map<String, Object>>> processAggregation(SearchResponse response) {
Map<String,Collection<Map<String, Object>>> responseMap = new HashMap<>();
try {
if(response.getAggregations() != null) {
for (Aggregation agg : response.getAggregations().asList()) {
String key = agg.getName();
Terms terms = response.getAggregations().get(key);
Collection<Map<String, Object>> objects = new HashSet<>();
Map<String, Object> result = new HashMap<>();
for(Terms.Bucket bucket : terms.getBuckets()){
String extLabel = (String) bucket.getKey();
Object count = bucket.getDocCount();
result.put(extLabel,count);
}
objects.add(result);
responseMap.put(key,objects);
}
}
return responseMap;
} catch (Exception e) {
log.error("Unable to process search response");
}
return null;
}

https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/_bucket_aggregations.html
public List<StringBuilder> aggregation(String filterField, Object start, Object end, String... fields) throws IOException {
List<StringBuilder> results = new LinkedList<>();
SearchRequest searchRequest = new SearchRequest(this.index);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
if (!StringUtils.isEmpty(filterField)){
QueryBuilder queryBuilder = QueryBuilders.rangeQuery(filterField).gte(start).lte(end);
searchSourceBuilder.query(queryBuilder);
}
AggregationBuilder aggregationBuilder = buildAggregation(fields, 0);
if(aggregationBuilder == null)
return results;
searchSourceBuilder.aggregation(aggregationBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = esClient.search(searchRequest, RequestOptions.DEFAULT);
Terms terms = searchResponse.getAggregations().get(fields[0]);
processBuckets(terms, new Stack<>(), results);
return results;
}
public AggregationBuilder buildAggregation(String[] fields, int i) {
if(i == fields.length - 1)
return aggregationBuilder(fields[i]);
return aggregationBuilder(fields[i]).subAggregation(buildAggregation(fields, i + 1));
}
private AggregationBuilder aggregationBuilder(String term) {
return AggregationBuilders
.terms(term)
.field(term)
.size(1000)
.order(BucketOrder.count(false));
}
public void processBuckets(Terms terms, Stack<String> stack, List<StringBuilder> results) {
if(terms != null) {
for (Terms.Bucket bucket : terms.getBuckets()) {
stack.push(bucket.getKeyAsString() + ":" + bucket.getDocCount() + ";");
if(bucket.getAggregations().asList().isEmpty()) {
StringBuilder result = new StringBuilder();
for (String s : stack) {
result.append(s);
}
results.add(result);
}
for (Aggregation aggregation : bucket.getAggregations().asList()) {
processBuckets((Terms) aggregation, stack, results);
}
stack.pop();
}
}
}

我和我的网友找到了解决方案
log.info("Query results:");
Terms contractSums = response.getAggregations().get("customer_id");
for (Terms.Bucket bucket : contractSums.getBuckets()) {
Sum aggValue = bucket.getAggregations().get("total_contract_sum");
DecimalFormat formatter = new DecimalFormat("0.00");
log.info(" " + bucket.getKey() + " " + formatter.format(aggValue.getValue()));
}
-
问题内容: 嗨,我有供cpu使用的文档,其中包含date_time字段。现在,我想查找日期范围内的avg cpu用法。我想出了以下解决方案。如果我是Elastic Search的新手,请告诉我是否有任何先进或更好的方法。 现在,上面的查询返回我期望的文档,该文档在/日期范围内。现在,我要做的是,使用这些文档找到所有唯一的日期,并将这些唯一的日期组合存储在中,然后针对其中的所有项目执行以下查询 现在
-
不知道如何表达这个问题。我正在使用Elasticsearch 2.2。 让我们从数据集的一个示例开始,该数据集由5个文档组成: 被调用的\u实体始终具有uuid。coverage\u实体可以为空,也可以具有uuid。 我使用脚本在任何一个被调用的\实体上进行聚合。uuid或coverage\u实体。uuid: 现在,聚合已经从任一头生成了术语。调用了\u实体。uuid或标头。coverage\u实
-
问题内容: 有人可以告诉我如何编写将汇总(汇总和计数)有关我的文档内容的Python语句吗? 脚本 输出值 是什么原因造成的?“ aggregations”关键字是否错误?我还需要导入其他软件包吗?如果“出勤”索引中的文档有一个名为emailAddress的字段,我将如何计算哪些文档具有该字段的值? 问题答案: 首先。现在我注意到,我在这里写的内容实际上没有定义聚合。对我来说,有关如何使用它的文档
-
框架集合由搜索查询选择的所有数据。框架中包含许多构建块,有助于构建复杂的数据描述或摘要。聚合的基本结构如下所示 - 有以下不同类型的聚合,每个都有自己的目的 - 指标聚合 这些聚合有助于从聚合文档的字段值计算矩阵,并且某些值可以从脚本生成。 数字矩阵或者是平均聚合的单值,或者是像一样的多值。 平均聚合 此聚合用于获取聚合文档中存在的任何数字字段的平均值。 例如, 请求正文 响应 如果该值不存在于一
-
我想在JAVA API中编写elasticsearch聚合代码,以查找字段折叠和结果分组。 json聚合代码如下所示,我从elasticsearch文档中获得了这些代码 “dedup\u by\u score”聚合具有称为“top\u hit”聚合的子聚合,并将此聚合用于桶排序。 我想将这个json查询转换为JAVA 这是我已经在JAVA中尝试过的 但是我从Elasticsearch得到了如下错误
-
问题内容: 有一个对话列表,每个对话都有一个消息列表。每个消息都有一个不同的字段和一个字段。我们需要考虑的是,在对话的第一条消息中使用了动作,在几条消息中使用了动作之后,过了一会儿,依此类推(有一个聊天机器人意图列表)。 将对话的消息动作分组将类似于: 问题: 我需要使用ElasticSearch创建一个报告,该报告将返回每次会话的;接下来,我需要对类似的东西进行分组并添加一个计数;最终将导致as