
bboss-datatran --- 简化版Flink
bboss-datatran由 bboss 开源的数据采集&流批一体化工具,提供数据采集、数据清洗转换处理和数据入库以及数据指标统计计算流批一体化处理功能。
bboss-datatran 数据同步作业采用java语言开发,小巧而精致,同时又可以采用java提供的所有功能和现有组件框架,随心所欲地处理和加工海量存量数据、实时增量数据,实现流批一体数据处理功能;可以根据数据规模及同步性能要求,按需配置和调整数据采集同步作业所需内存、工作线程、线程队列大小;可以将作业独立运行,亦可以将作业嵌入基于java开发的各种应用汇总运行;通过作业执行控制API、任务状态监控metircs api,可以定制化开发一些符合自己要求的同步作业任务监控管理功能,提供作业启动、暂停(pause)、继续(resume)、停止控制功能,轻松定制一款属于自己的ETL管理工具。
工具可以灵活定制具备各种功能的数据采集统计作业
1) 只采集和处理数据作业
2) 采集和处理数据、指标统计计算混合作业
3) 采集数据只做指标统计计算作业
指标计算特点
1) 支持时间维度和非时间维度指标计算
2) 时间维度指标计算:支持指定统计时间窗口,单位到分钟级别
3) 一个指标支持多个维度和多个度量字段计算,多个维度字段值构造成指标的唯一指标key,支持有限基数key和无限基数key指标计算
4) 一个作业可以支持多种类型的指标,每种类型指标支持多个指标计算
5)支持准实时指标统计计算和离线指标统计计算
6)可以从不同的数据输入来源获取需要统计的指标数据,亦可以将指标计算结果保存到各种不同的目标数据源
增量数据采集,默认基于sqlite数据库管理增量采集状态,可以配置到其他关系数据库管理增量采集状态,提供对多种不同数据来源增量采集机制:
1) 基于数字字段增量采集:各种关系数据库、Elasticsearch、MongoDB、Clickhouse等
2) 基于时间字段增量采集:各种关系数据库、Elasticsearch、MongoDB、Clickhouse、HBase等,基于时间增量还可以设置一个截止时间偏移量,比如采集到当前时间前十秒的增量数据,避免漏数据
3) 基于文件内容位置偏移量:文本文件、日志文件基于采集位置偏移量做增量
4) 基于ftp文件增量采集:基于文件级别,下载采集完的文件就不会再采集
可以把 bboss-datatran看成是一个简单的、轻量级的数据同步框架,亦可以把他当做一个小组件,只需导入一个maven坐标,参考提供的一系列案例,就可以轻松愉快地开发出一个非常棒的数据采集、加工、入库、分发、上传的、具备增量状态管理功能的数据采集同步作业,同时还可以在idea、eclipse中进行debug调测,通过一些错误回调处理机制,可以非常方便地洞悉同步过程中的各种数据问题、处理错误和异常;依赖jdk环境,无需额外安装其他工具环境,就可以将bboss数据采集同步作业跑起来。
如果您还在:
- 苦于logstash、flume、filebeat之类的开源工具无法满足复杂的、海量数据自定义加工处理场景;
- 苦于无法调用企业现有服务和库来处理加工数据;
- 苦于因项目投入有限、进度紧,急需一款功能强大、上手快、实施简单的数据交换工具
- 苦于寻求数据采集和流批一体数据处理和指标统计计算于一体的数据处理计算框架
那么bboss-datatran将是一个不错的选择。

文件输入和输出插件:支持大量文件并行采集、增量/全量采集,快速、稳定、高效
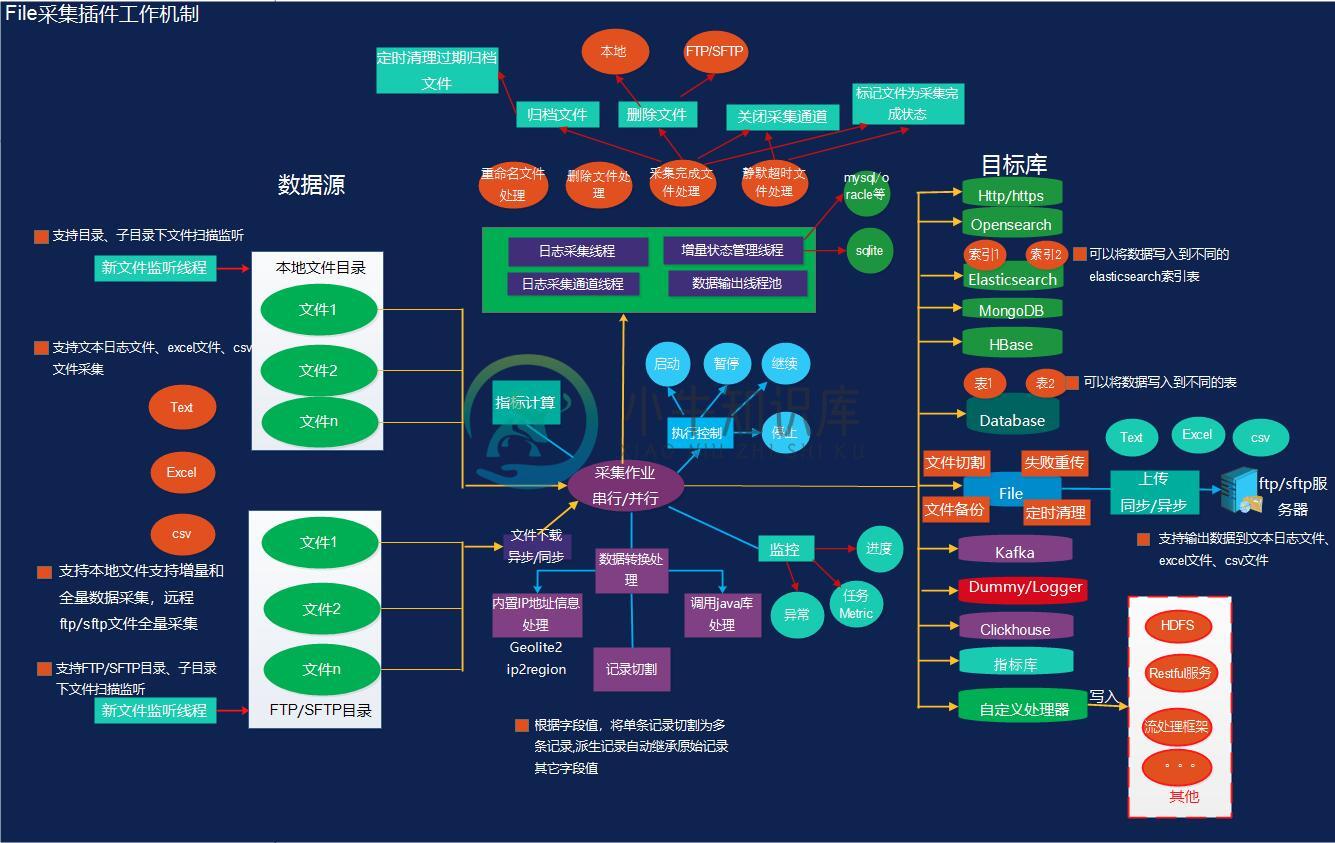
采用标准的输入输出异步管道来处理数据

案例大全
https://esdoc.bbossgroups.com/#/bboss-datasyn-demo
功能特点
1.支持多种数据源之间的数据同步
2.支持多种数据导入方式
- 批量数据导入
- 批量数据多线程并行导入
- 定时全量(串行/并行)数据导入
- 定时增量(串行/并行)数据导入
3.支持的数据库和消息中间件类型
数据库: mysql,maridb,postgress,oracle ,sqlserver,db2,tidb,hive,clickhouse,mongodb、HBase、elasticsearch、达梦等
消息中间件:kafka 1x,kafka 2x
4.Elasticsearch版本兼容性
Elasticsearch 1.x,2.x,5.x,6.x,7.x,8.x+
5.支持海量PB级数据同步导入Elasticsearch
6.支持将ip转换为对应的运营商/省份城市/经纬度坐标位置信息
7.支持设置数据bulk导入任务结果处理回调函数,对每次bulk任务的结果进行成功和失败反馈,然后针对失败的bulk任务通过error和exception方法进行相应处理
8.提供详细的数据同步任务监控指标,可监控作业任务处理总记录数、成功记录数、Ignore记录数、失败记录数,支持自行将任务监控指标数据进行存储或者转发到kafka
9.支持多种定时任务执行引擎
- jdk timer (内置)
- quartz
- xxl-job分布式调度引擎,基于分片调度机制实现海量数据快速同步能力
10.支持两种作业运行方式
- 嵌入到应用中运行,基于quartz和jdk timer调度的作业都可以运行在这种模式下,参考文档:spring boot运行案例
- 独立发布包运行,基于quartz和xxl-job,jdk timer调度的作业都可以运行在这种模式下,参考文档:作业发布
11.基于java语言开发和发布数据同步作业
12.提供了基于gradle管理的作业开发模板工程,以方便大家快速构建和发布自己的数据同步作业:
https://gitee.com/bboss/bboss-datatran-demo
总之bboss-datatran是一款高度灵活的数据交换工具,基于bboss-datatran可以快速实现开发高效而强大的数据同步作业,以及构建在其上的数据交换产品。
-
ElasticSearch 1.什么是RestFul REST : 表现层状态转化(Representational State Transfer),如果一个架构符合REST原则,就称它为 RESTful 架构风格。 资源: 所谓"资源",就是网络上的一个实体,或者说是网络上的一个具体信息 表现层 :我们把"资源"具体呈现出来的形式,叫做它的"表现层"(Representation)。 状态转化(
-
5.8.1.1 Elasticsearch 安装 安装 logstash ElasticSearch中 logstash安装和logstash-input-jdbc插件 安装 logstash-input-jdbc插件 logstash-plugin install logstash-input-jdbc # 在有网点环境下安装,将安装插件后的 logstash 拷贝到内网环境即可使用。 编辑
-
问题内容: 最终,我想为PostgreSql中的数据提供一个可扩展的搜索解决方案。我的发现指向我使用Logstash将写入事件从Postgres传送到ElasticSearch,但是我没有找到可用的解决方案。我发现的解决方案涉及使用jdbc- input 间隔查询Postgres的 所有 数据,并且不捕获删除事件。 我认为这是一个常见的用例,因此我希望你们可以与我分享您的经验,或者给我一些指导。
-
问题内容: 我正在考虑使用日常脚本来执行以下操作,以解决ES服务器上更新存在问题的任何情况(我还没有高可用性设置,即使如此,它仍然可能是在数据库和ES之间复制数据的情况下的良好做法)。在把这个脚本放在一起之前,我想我会检查一下是否要以正确的方式进行操作,以及是否应该使用任何库或技术。 该脚本将简单地从数据库中检索所有ID,并从ElasticSearch中检索所有ID,其中(当前时间的快照,因为它是
-
问题内容: 目的 :将elasticsearch 与postgres数据库同步 为什么 :有时newtwork或集群/服务器中断,因此应记录将来的更新 本文https://qafoo.com/blog/086_how_to_synchronize_a_database_with_elastic_search.html建议我应该创建一个单独的表来同步elasticsearch的表,从而允许从上一个记
-
主要内容:1.同步双写,2.异步双写,3.定时任务,4.数据订阅1.同步双写 优点:实现简单 缺点: 业务耦合,商品的管理中耦合大量数据同步代码 影响性能,写入两个存储,响应时间变长 不便扩展:搜索可能有一些个性化需求,需要对数据进行聚合,这种方式不便实现 2.异步双写 上架商品的时候, 先把商品数据丢入MQ, 为了解耦, 拆分一个搜索微服务, 搜搜微服务去订阅商品变动的信息, 完成同步 一些数据需要聚合处理成类似宽表的结构怎么办呢?例如商品库的商品品类、sp
-
问题内容: 我想将数据同步到,我读了很多关于Elasticsearch River插件和mongo连接器的文章,但是不推荐使用mongo 4和elasticsearch 7! 作为专有软件,我想使用它来同步两者…任何人都知道如何做到这一点? 问题答案: 您可以将MongoDB和Elasticsearch与Logstash同步;实际上,同步是Logstash的主要应用之一。安装Logstash之后,
-
“同步到数据库”功能让你比对物理模型和现有数据库或模式,显示它们之间结构的差异,并提供同步模型的结构到目标连接。 Navicat 提供一个向导,一步一步指导你完成任务: 选择“文件”->“同步到数据库”。 选择源数据库、模式,然后从现有的连接中选择目标连接、数据库、模式。 点击“选项”并选择比对或高级选项。 点击“比对”以显示源对象和目标对象之间的差异。 选择要同步的对象。 点击“部署”以生成一组
-
“同步到数据库”功能让你比对模型和现有数据库或模式,显示它们之间结构的差异,并提供同步模型的结构到目标连接。 Navicat 提供一个向导,一步一步指导你完成任务: 选择“文件”->“同步到数据库”。 选择源数据库、模式,然后从现有的连接中选择目标连接、数据库、模式。 点击“选项”并选择比对或高级选项。 点击“比对”以显示源对象和目标对象之间的差异。 选择要同步的对象。 点击“部署”以生成一组脚本