
概览
Apache Geode 是一个数据管理平台,提供实时的、一致的、贯穿整个云架构地访问数据关键型应用.
Geode 池化了服务器上的内存, CPU, 网络资源, 和本地磁盘,跨多个进程来管理应用对象和应用行为. 它使用了动态数据复制和分区技术来实现高可用, 高性能, 高可扩展性, 和容错. 另外, 对于一个分布式数据容器, Apache Geode 是一个基于内存的数据管理系统, 提供了可靠的异步事件通知和可靠的消息投递.
Apache Geode 是一个相当成熟, 强健的技术, 最初由GemStone Systems 公司开发(位于美国俄勒冈州的比弗顿市). 商标为 GemFire™, 此项技术初期被广泛应用在金融领域, 用于华尔街交易平台,作为事务性, 低延时的数据引擎. 那么今天Apache Geode 有超过600家大中型企业级用户, 主要是必须满足低延时和24x7 高可靠要求的,高可扩展的关键业务应用系统.
此工程目前在ASF下正处于孵化阶段, 通过孵化器来提供赞助. 孵化对于所有新加入的工程很重要,直到基础设施, 通信, 决策流程足够稳定,和其他成功的 ASF工程一致. 当孵化器状态完成或代码稳定时, 它提示此工程完全由 ASF 承认.
主要概念和模块
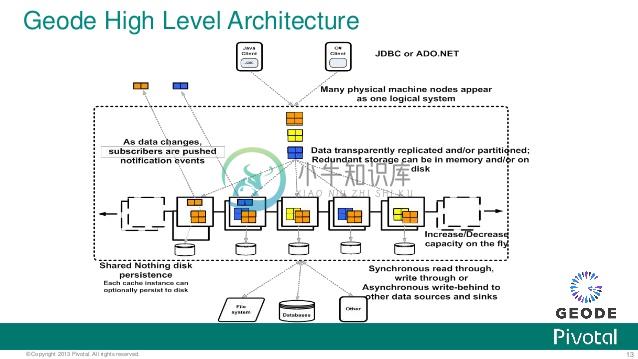
缓存 是一个抽象的概念, 在一个 Geode 分布式系统中用于描述一个节点.
在每个缓存中, 你定义数据 regions. 数据 regions 类似于传统关系型数据库中的'表'的概念, 以分布式的方式来管理数据 , 表现为名/值对儿形式. 在分布式系统的每个缓存成员中, 一个 复制 region 保存数据的拷贝. 一个 分区 region 跨缓存成员来同步数据. 在系统配置后, 客户端应用能够访问regions 中的分布式数据, 而不需要知道系统整体架构的知识. 你能够定义监听器来接收通知, 当数据发生变化时, 同时你也能够定义超时标准来删除在一个 region 中的废弃掉的数据.
Locators 提供了发现和负载均衡服务. 你配置带有 locator 服务列表的客户端, 同时 locators 维护一个成员服务器的动态列表. 默认情况下, Geode 客户端和服务器使用端口 40404 和多播来互相发现.
Geode 包含了如下的特性:
-
结合冗余, 复制, 和 "shared nothing" 的一致性架构来交付 '自动防故障' 的可靠性和高性能.
-
水平扩展到数千个缓存成员, 具有多种缓存拓扑结构来满足不同的企业级部署需求. 缓存能够跨多台机器进行分布.
-
异步和同步缓存更新传播.
-
Delta 传播只分发新版本和旧版本的变化量 (delta) , 而不是整个对象, 从而可以节省大量的网络开销.
-
通过经过优化的, 低延时的通信层进行可靠的异步事件通知, 高保障的消息投递.
-
在没有额外硬件的辅助下, 应用可以加速4 到 40,000 倍.
-
数据感知和实时BI. 当你查询时, 如果数据变化了, 你能够立刻在系统中看见数据的变化.
-
集成 Spring 框架来加速和简化高可扩展、高并发和事务型企业级应用的开发复杂度.
-
JTA 兼容的事务支持.
-
集群的配置可以写到文件中和导出到其他集群中.
-
通过HTTP做 远程集群管理.
-
基于REST应用开发的REST APIs.
-
滚动升级是可行的, 但是需要服从新特性的限制问题.
-
简介 Performance is key. Consistency is a must. 性能是关键。一致性是必须的。 Providing low latency, high concurrency data management solutions since 2002. 自2002年以来提供低延迟、高并发数据管理解决方案。 Build high-speed, data-intensive a
-
本篇文章主要讲解Apache Geode/GemFire 是如何进行数据分区的。 GemFire和大多数分布式系统一样都采用 Hash 的方式对数据进行分区,将 Entry 数据分布到 PartitionedRegion 当中,大家都知道 Entry 数据主要保存在 ConcurrentHashMap 中,ConcurrentHashMap存放在 Bucket 中,在 PR 服务器启动后会为 Pa
-
关于Apache Geode Apache Geode是一个数据管理平台,可在广泛分布的云架构中提供对数据密集型应用程序的实时,一致的访问。 Geode跨多个进程汇集内存,CPU,网络资源和可选的本地磁盘,以管理应用程序对象和行为。它使用动态复制和数据分区技术来实现高可用性,改进的性能,可伸缩性和容错性。除了作为分布式数据容器之外,Geode还是一个内存数据管理系统,可提供可靠的异步事件通知和有保
-
一、概述 Apache Geode是一个数据管理平台,在广泛分布的云架构中提供对数据密集型应用程序的实时,一致的访问。 Geode可以跨多个进程池内存,CPU,网络资源和可选的本地磁盘,以管理应用程序对象和行为。它使用动态复制和数据分区技术来实现高可用性,改进的性能,可扩展性和容错性。Apache Geode除了是一个分布式数据容器外,还是一个内存数据管理系统,提供可靠的异步事件通知和有保证的消息
-
性能是关键。一致性是必须的。 自 2002 年起提供低延迟、高并发的数据管理解决方案。 构建高速、数据密集型应用程序,以弹性满足任何规模的性能要求。 利用 Apache Geode 的独特技术,该技术融合了用于数据复制、分区和分布式处理的高级技术。 Apache Geode 提供了类似数据库的一致性模型、可靠的事务处理和无共享架构,以通过高并发处理保持极低的延迟性能。 Gradle depen
-
昨天研究了半天apache geode,通过gfsh命令查询和操作比较简单,但是如何通过程序查询因为资历太少,没有搞懂,试验了半天才明白 1.创建测试regioncreate region --name=user --type=REPLICATE_PERSISTENT 2.用eclipse创建maven工程 修改pom.xml,需要引入gemfire-8.2.0.jar,这个在 xsi:schem
-
Apache Geode是一个数据管理平台,提供实时、稳定的访问数据密集型应用在广泛分布的云架构。 Apache Geode池化内存、CPU、网络资源,以及可选的本地磁盘到多个进程来管理应程序对象和行为。它使用动态复制和数据分区技术来实现高可用性,改进的性能,可扩展性和容错性。除了是一个分布式的数据容器,Geode是一个内存中的数据管理系统,提供了可靠的异步事件通知和保证信息传递。 高速缓存是一个
-
最近在研究开源内存数据库,apache ignite用了一段时间感觉还行因为资料太少,因此只是用了它的rpc功能做了一个分布式框架。 前天发现apache geode这个框架,据说是12306的Gemfire的开源版本。 官网地址:http://geode.apache.org/ 一、安装 安装之前,服务器上必须要安装jdk(最好是jdk1.8),配置好JAVA_HOME 下载wget http:
-
Overview [Apache Geode] (http://geode.incubator.apache.org/) is a data management platform that provides real-time, consistent access to data-intensive applications throughout widely distributed cloud
-
一、开始使用Apache Geode 1、关于Apache Geode 2、主要特征 3、先决条件与安装指南 4、在15分钟或更短的时间内使用 二、配置和运行集群 1、集群配置服务概述 2、教程——创建和使用集群配置 3、部署应用程序jars到Apache Geode成员 4、使用成员组 5、导出和导入集群配置 6、集群配置文件和故障排除 7、将现有的配置文件加载到集群配置中 8、基于HTTP或H
-
Overview Learn Samples Spring Session for Apache Geode & Pivotal GemFire (SSDG) provides an API and implementation of Spring Session core to manage a user’s Session information. Session state is stor
-
在本章节,提供了关于诸葛io数据管理的相关文档: 数据模型 数据接入技术 identify记录用户身份 UTM参数标识流量 DeepShare跨应用商店的来源分析 事件分组&重要事件(星标事件) 数据的别名/隐藏/停用 字符串/数值/日期的设置 用户信息脱敏与数据安全 成员角色权限表
-
这一章介绍如何在 Docker 内部以及容器之间管理数据,在容器中管理数据主要有两种方式: 数据卷(Volumes) 挂载主机目录 (Bind mounts)
-
频道流水报表管理 获取频道报表 获取频道资金流水 获取频道打赏流水 获取频道发红包/抢红包记录 获取频道付费流水 获取观众观看流水_V2 获取观众观看流水_V1 获取频道报名问卷数据 获取频道问卷列表数据 获取频道观众列表V2 获取频道观众列表
-
我是wordpress的新手,在管理数据库方面有困难。我已经安装了“管理员”插件来管理数据库。我已经创建了一个名为“usersupp_admin”的新表。现在我还创建了一个自定义模板,该模板将使用PDO语句连接到此数据库,现在的问题是在哪里可以获取主机、数据库名、用户和密码?以下是代码: 任何帮助都将不胜感激。
-
“数据管理”用来管理“百度统计-分析云”所追踪的数据,帮助您对产品内所有的数据进行统一管理和维护。 新版分析云的数据模型由之前的“PV模型”升级为“事件模型”。支持您对产品进行更多场景下的精细化分析。在使用分析云进行分析前,您需要在“数据管理”内定义“事件”和“属性”。 事件是用户在产品上的行为,如“浏览页面”、“点击元素”等。 属性是用来描述事件的维度。在分析云中,属性不从属于具体事件,您需要从
-
CREATE TABLE充当来自CSVREAD的SELECT*('c://users/h/downloads/SERVES.csv');SQL语句“create TABLE SERVES AS SELECT*FROM CSVREAD([*]'c://users/h/downloads/SERVES.csv')”中的语法错误;SQL语句:CREATE TABLE充当从CSVREAD中选择*('c:/
-
① 事件管理 为了对系统所有事件进行新增,编辑和展示的配置模块,能非常明确目前系统中都有哪些监测事件; 新建事件 事件key:用来确定事件描述的唯一,长度为 1-32 个英文字符,设置后不可更改; 事件名称:用来区分不同的事件描述,并用于系统显示查看,可编辑更新; 事件属性key:用来确定事件的唯一,长度为 1-32 个英文字符,设置后不可更改; 类型:对定义属性的类型定义,可选择文本、日期、数字
-
5. 数据管理 ① 事件管理 为了对系统所有事件进行新增,编辑和展示的配置模块,能非常明确目前系统中都有哪些监测事件; 新建事件 事件key:用来确定事件描述的唯一,长度为 1-32 个英文字符,设置后不可更改; 事件名称:用来区分不同的事件描述,并用于系统显示查看,可编辑更新; 事件属性key:用来确定事件的唯一,长度为 1-32 个英文字符,设置后不可更改; 类型:对定义属性的类型定义,可选择