
The best elasticsearch highlevel java rest api-----bboss
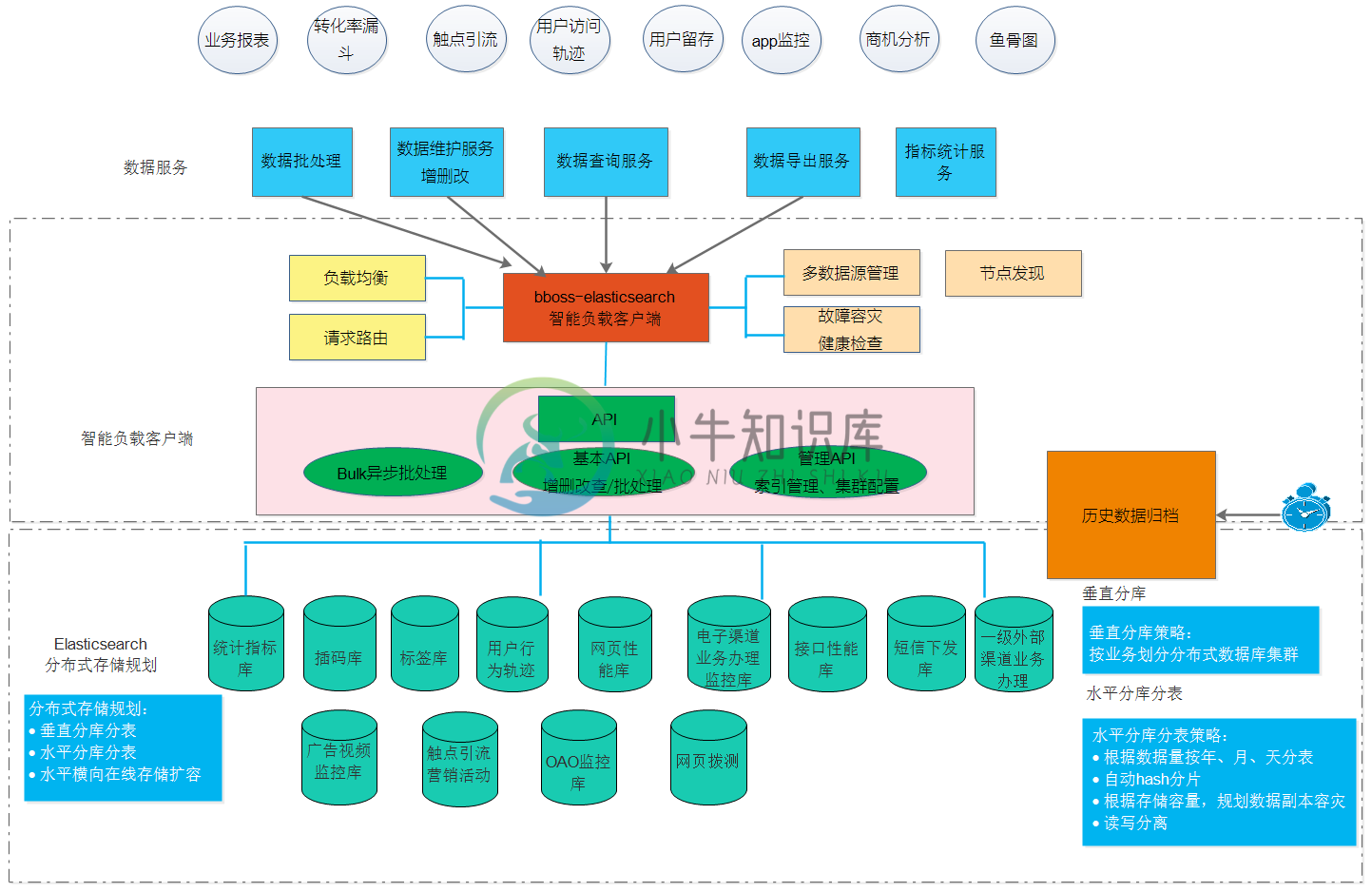
bboss是一套基于query dsl语法操作和访问分布式搜索引擎Elasticsearch/Opensearch的o/r mapping高性能开发库,底层直接基于 http 协议操作和访问Elasticsearch、Opensearch。基于bboss,可以快速编写出访问和操作Elasticsearch/Opensearch的程序代码,简单、高效、可靠、安全。

快速开始bboss
https://esdoc.bbossgroups.com/#/quickstart
bboss兼容性
兼容性:bboss兼容所有版本Elasticsearch、Spring boot,基于bboss开发的代码,可以无缝对接不同版本的Elasticsearch、Opensearch、Spring boot
| bboss | Elasticsearch | spring boot |
|---|---|---|
| all | 1.x | 1.x,2.x |
| all | 2.x | 1.x,2.x |
| all | 3.x | 1.x,2.x |
| all | 5.x | 1.x,2.x |
| all | 6.x | 1.x,2.x |
| all | 7.x | 1.x,2.x |
Opensearch兼容性:1.x,2.x,+
jdk兼容性:jdk 1.7+
典型应用场景
一行代码插入/修改
//添加/修改文档,如果文档id存在则修改,不存在则插入
clientUtil.addDocument("agentinfo",//索引名称
agentInfo);//需添加/修改的索引数据对象一行代码分页/高亮检索
ESDatas<TAgentInfo> data //ESDatas为查询结果集对象,封装了返回的当前查询的List<TAgentInfo>结果集和符合条件的总记录数totalSize
= clientUtil.searchList("trace-*/_search",//查询操作,查询indices trace-*中符合条件的数据
"queryServiceByCondition",//通过名称引用配置文件中的query dsl语句
traceExtraCriteria,//查询条件封装对象
TAgentInfo.class);//指定返回的po对象类型,po对象中的属性与indices表中的文档filed名称保持一致
//获取当前页结果对象列表
List<TAgentInfo> demos = data.getDatas();
//获取总记录数
long totalSize = data.getTotalSize();根据文档id获取文档
Demo demo = clientUtil.getDocument("demo",//索引表
"2",//文档id
Demo.class);//指定返回对象类型根据字段直接获取文档
String document = clientInterface.getDocumentByField("demo",//索引名称
"applicationName.keyword",//字段名称
"blackcatdemo2");//字段值
Map document = clientInterface.getDocumentByField("demo","applicationName.keyword","blackcatdemo2",Map.class);
DemoPo document = clientInterface.getDocumentByField("demo","applicationName.keyword","blackcatdemo2",DemoPo.class);一行代码根据字段值进行分页查找
ESDatas<Map> documents = clientInterface.searchListByField("demo",//索引名名称
"applicationName.keyword", //检索字段名称
"blackcatdemo2",//检索值
Map.class, //返回结果类型,可以是po对象类型也可以是map类型
0, //分页起始位置
10); //分页每页记录数
//获取当前页结果对象列表
List<Map> demos = data.getDatas();
//获取匹配的总记录数
long totalSize = data.getTotalSize();一行代码删除文档
clientUtil.deleteDocument("demo",//索引表
"2");//文档id一行代码批量删除文档
//批量删除文档
clientUtil.deleteDocuments("demo",//索引表
new String[]{"2","3"});//批量删除文档idsapi方法可以指定特定的Elasticsearch 集群进行操作
所有 api 可以直接指定 数据源操作,指哪打哪,下面展示了在一段代码里面同时操作两个Elasticsearch集群功能:datasourceName1和datasourceName2
ESDatas<Demo> esDatas1 =
clientUtil.searchListWithCluster(datasourceName1,//指定操作的Elasticsearch集群数据源名称
"demo1/_search",//demo为索引表,_search为检索操作action
"searchDatas",//esmapper/demo7.xml中定义的dsl语句
params,//变量参数
Demo.class);//返回的文档封装对象类型
ESDatas<Demo> esDatas2 =
clientUtil.searchListWithCluster(datasourceName2,//指定操作的Elasticsearch集群数据源名称
"demo2/_search",//demo为索引表,_search为检索操作action
"searchDatas",//esmapper/demo7.xml中定义的dsl语句
params,//变量参数
Demo.class);//返回的文档封装对象类型datasourceName1和datasourceName2 可是两个相同版本的Elasticsearch,亦可以是两个不同版本的Elasticsearch,bboss在兼容性方面是毋庸置疑的。
快速集成,导入BBoss maven坐标:quickstart文档
其他特点
-
采用XML文件配置和管理检索dsl脚本,简洁而直观;提供丰富的逻辑判断语法,在dsl脚本中可以使用变量、脚本片段、foreach循环、逻辑判断、注释;基于可扩展DSL配置管理机制可以非常方便地实现数据库、redis等方式管理dsl;配置管理的dsl语句支持在线修改、自动热加载,开发和调试非常方便
-
提供Elasticsearch集群节点自动负载均衡和容灾恢复机制,Elasticsearch节点断连恢复后可自动重连,高效可靠
-
提供Elasticsearch集群节点自动发现机制:自动发现Elasticsearch服务端节点增加和下线操作并变更客户端集群可用节点地址清单
-
提供http 连接池管理功能,提供精细化的http连接池参数配置管理
-
支持在应用中访问和操作多个Elasticsearch集群,支持在应用中访问和操作不同版本的Elasticsearch集群
-
提供高效的BulkProcessor处理机制
-
提供快速而高效的数据同步导入ES工具:支持DB到Elasticsearch,Elasticsearch到DB,MongoDB到Elastisearch数据同步,HBase到Elasticsearch数据同步,Kafka到Elasticsearch数据同步,将支持更多的数据源
-
提供按时间日期ES历史数据清理工具
源码地址:
https://github.com/bbossgroups/bboss-elasticsearch
https://gitee.com/bboss/bboss-elastic
从源码构建
https://esdoc.bbossgroups.com/#/bboss-build
Elasticsearch Demo
https://esdoc.bbossgroups.com/#/Elasticsearch-demo
快速集成和应用
- 普通类型项目集成bboss:common-project-with-bboss
- spring boot 项目集成bboss:spring-booter-with-bboss
- 增删改查开发手册:https://esdoc.bbossgroups.com/#/document-crud
- 详细开发指南:https://esdoc.bbossgroups.com/#/development
-
原文网址:bboss-elasticsearch--API_IT利刃出鞘的博客-CSDN博客 简介 说明 本文介绍bboss-elasticsearch的API。 官网 Elasticsearch索引文档增删改查 - Elasticsearch Bboss Elasticsearch开发指南 - Elasticsearch Bboss 注解 官网 ElasticSearch客户端注解介绍 - El
-
最近项目中有文件信息需要快速索引,就打算把原来存储到MYSQL里面的数据全部存储到ES中 一下是代码 yml配置 ```yaml elasticsearch: bboss: elasticUser: elasticPassword: elasticsearch: rest: hostNames: 192.168.0.
-
一、官方文档 https://esdoc.bbossgroups.com/#/README 二、官方demo https://github.com/bbossgroups/elasticsearch-example.git 三、maven构建 <dependency> <groupId>com.bbossgroups.plugins</groupId>
-
原文网址:bboss-elasticsearch--介绍/官网等_IT利刃出鞘的博客-CSDN博客 简介 官网 官网网址(中文) 官网教程(中文) github:GitHub - bbossgroups/bboss-elasticsearch: the best elasticsearch highlevel java rest client api-----bboss
-
官方解决方法 点我跳转 idea启动正常,打包启动报错127.0.0.1连不上看这里↓↓↓ 必须使用这种方式,不要用ElasticSearchHelper,打包会有问题 @Autowired private BBossESStarter bbossESStarter; 正常启动,读取到配置的application.yml spring: application: name: xxx
-
依赖增加: <dependency> <groupId>com.bbossgroups.plugins</groupId> <artifactId>bboss-elasticsearch-rest-jdbc</artifactId> <version>6.2.8</version> </dependency> <dependency> <groupId>com.bb
-
前言: 今天看bboss的xml文件,要用bboss的查询检索功能,结果有一些东西看不懂,问了尹标平大佬果然是用了velocity,那就看看学习学习吧,万一以后我维护Bboss源码了呐,时刻准备着、不行就再(pao)学(lu) Velocity 是MVC架构的一种实现;基于java的模板引擎,允许任何人使用简单而强大的模板语言来引用定义在Java代码中的对象。 页面设计人员可只关
-
思路 使用Bboss的Http请求,核心还是ES原生的http请求接口,自己懒得写,直接使用Bboss封装好的 maven依赖 <dependency> <groupId>com.bbossgroups.plugins</groupId> <artifactId>bboss-elasticsearch-rest-jdbc</artifactId>
-
本文介绍如何采用bboss es添加/修改/删除/批量删除elasticsearch索引文档,直接看代码。 添加/修改文档 TAgentInfo agentInfo = new TAgentInfo() ; //设置地理位置坐标 agentInfo.setLocation("28.292781,117.238963"); //设置其他属性 。。。。 ClientInterface clientUt
-
1、date的默认格式 date格式可以在put mapping的时候用 format 参数指定,如果不指定的话,则启用默认格式,是"strict_date_optional_time||epoch_millis"。这表明只接合"strict_date_optional_time"格式的字符串值,或者long型数字。 实测,仅支持如下格式: “yyyy-MM-dd” “yyyyMMdd” “yyy
-
bboss elasticsearch开发视频教程 百度网盘免密下载: [url=https://pan.baidu.com/s/1kXjAOKn]https://pan.baidu.com/s/1kXjAOKn[/url]
-
更改历史 * 2018-05-07 胡小根 初始化文档 1 历史、现状和发展 1.1 历史 1.2 现状 1.3 发展 难点:预测发展方向。 2 安装和使用 2.1 安装 2.2 使用 创建index和type 上传单条数据 批量上传数据 查询 2.3 示例 2.4 最佳实践 难点:最佳实践,超出于示例,应该归纳总结出积累的技巧。 3 同类技术对比 难点:归纳比对项 参考资料 El
-
搜索引擎分为两部分: 时间筛选 和 搜索引擎 (详情) 1.时间筛选 便捷按钮有今日、昨日、前日、上周 X、近七天,并且能自定义选择时间段来得出想要的结果报表 2.搜索引擎 (时间段详情) 选择日期,查看来自对应时间段内,各个搜索引擎的访问量比例
-
lucene 和 es 的前世今生 lucene 是最先进、功能最强大的搜索库。如果直接基于 lucene 开发,非常复杂,即便写一些简单的功能,也要写大量的 Java 代码,需要深入理解原理。 elasticsearch 基于 lucene,隐藏了 lucene 的复杂性,提供了简单易用的 restful api / Java api 接口(另外还有其他语言的 api 接口)。 分布式的文档存储
-
搜索引擎 关键参数 报告 method metrics(指标, 数据单位) 其他参数 搜索引擎 source/engine/a pv_count (浏览量(PV)) pv_ratio (浏览量占比,%) visit_count (访问次数) visitor_count (访客数(UV)) new_visitor_count (新访客数) new_visitor_ratio (新访客比率,%) ip
-
元搜索引擎 原搜索引擎是通过一个统一的用户界面帮助用户在多个搜索引擎中选择和利用合适的搜索引擎来实现检索操作,是对分布于网络的多种检索工具的全局控制机制。 自己没搜索引擎,又想要大规模的数据源,怎么办?可以对百度搜索和谷歌搜索善加利用,以小搏大,站在巨人的肩膀上。有很多的应用场景可以很巧妙地借助百度搜索和谷歌搜索来实现,比如网站的新闻采集,比如技术、品牌的新闻跟踪,比如知识库的收集,比如人机问答系
-
为什么需要搜索引擎 首先想一下:在一篇文章里找一个关键词怎么找?字符串匹配是最佳答案。 然后再想一下:找到100篇文章里包含某个关键词的文章列表怎么找?依然是关键词匹配 再继续想:找到100000000000(一千亿)篇文章里包含某个关键词的文章怎么找?如果用关键词匹配,以现在的电脑处理速度,从远古时代到人类灭绝这么长时间都处理不完,这时候搜索引擎要发挥作用了 搜索引擎技术有多么高深? 搜索引擎这