
如何使用Python和/或R在数据帧上的值之间进行插值

我的数据集如下所示:
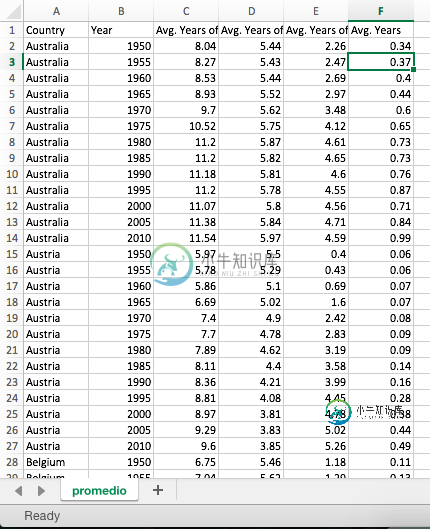
我将其导入到熊猫数据框中,使用pandas.read_csv以年份和国家列作为索引。我需要做的是将时间步长从每5年更改为每年,并插入所述值,我真的不知道如何做到这一点。我正在学习R和python,所以在这两种语言的帮助将高度赞赏。
共有3个答案

首先,重新为帧建立索引。然后使用df。应用和系列。插值
类似的东西:
import pandas as pd
df = pd.read_csv(r'folder/file.txt')
rows = df.shape[0]
df.index = [x for x in range(0, 5*rows, 5)]
df = df.reindex(range(0, 5*rows))
df.apply(pandas.Series.interpolate)
df.apply(pd.Series.interpolate, inplace=True)

这很难,但我想我已经做到了。
下面是一个示例数据框:
df = pd.DataFrame({'country': ['australia', 'australia', 'belgium','belgium'],
'year': [1980, 1985, 1980, 1985],
'data1': [1,5, 10, 15],
'data2': [100,110, 150,160]})
df = df.set_index(['country','year'])
countries = set(df.index.get_level_values(0))
df = df.reindex([(country, year) for country in countries for year in range(1980,1986)])
df = df.interpolate()
df = df.reset_index()
对于您的具体数据,假设每个国家都有1950年至2010年(含)之间每5年的数据,则
df = pd.read_csv('path_to_data')
df = df.set_index(['country','year'])
countries = set(df.index.get_level_values(0))
df = df.reindex([(country, year) for country in countries for year in range(1950,2011)])
df = df.interpolate()
df = df.reset_index()
有点棘手的问题。有兴趣看看是否有人有更好的解决方案

>
如果您给DataFrame一个DatetimeIndex,那么您可以利用df.resample和df.interpolate('time')方法。
要使df.index成为DatetimeIndex,您可能会尝试使用set_index('年')。然而,年本身并不是唯一的,因为它是为每个国家重复的。为了调用重新取样,我们需要一个唯一的索引。所以用df.pivot代替:
# convert integer years into `datetime64` values
In [441]: df['Year'] = (df['Year'].astype('i8')-1970).view('datetime64[Y]')
In [442]: df.pivot(index='Year', columns='Country')
Out[442]:
Avg1 Avg2
Country Australia Austria Belgium Australia Austria Belgium
Year
1950-01-01 0 0 0 0 0 0
1955-01-01 1 1 1 10 10 10
1960-01-01 2 2 2 20 20 20
1965-01-01 3 3 3 30 30 30
然后,您可以使用df.resample('A')。平均值()以年度频率重新取样数据。您可以将重新取样('A')看作是将df切成1年间隔的组。重新取样返回一个DatetimeIndexResapper对象,该对象的均值方法聚合每个组中的值通过取平均值。因此平均值()每年返回一行的DataFrame。由于您的原始df每5年有一个数据,大多数1年组将是空的,因此平均值返回这些年的NaNs。如果您的数据始终以5年的间隔间隔,那么您可以使用. first()或. last()来代替。它们都会返回相同的结果。
In [438]: df.resample('A').mean()
Out[438]:
Avg1 Avg2
Country Australia Austria Belgium Australia Austria Belgium
Year
1950-12-31 0.0 0.0 0.0 0.0 0.0 0.0
1951-12-31 NaN NaN NaN NaN NaN NaN
1952-12-31 NaN NaN NaN NaN NaN NaN
1953-12-31 NaN NaN NaN NaN NaN NaN
1954-12-31 NaN NaN NaN NaN NaN NaN
1955-12-31 1.0 1.0 1.0 10.0 10.0 10.0
1956-12-31 NaN NaN NaN NaN NaN NaN
1957-12-31 NaN NaN NaN NaN NaN NaN
1958-12-31 NaN NaN NaN NaN NaN NaN
1959-12-31 NaN NaN NaN NaN NaN NaN
1960-12-31 2.0 2.0 2.0 20.0 20.0 20.0
1961-12-31 NaN NaN NaN NaN NaN NaN
1962-12-31 NaN NaN NaN NaN NaN NaN
1963-12-31 NaN NaN NaN NaN NaN NaN
1964-12-31 NaN NaN NaN NaN NaN NaN
1965-12-31 3.0 3.0 3.0 30.0 30.0 30.0
然后df.interpolate(method='time')将根据最近的非NaN值及其相关的日期时间索引值线性插值缺失的NaN值。
import numpy as np
import pandas as pd
countries = 'Australia Austria Belgium'.split()
year = np.arange(1950, 1970, 5)
df = pd.DataFrame(
{'Country': np.repeat(countries, len(year)),
'Year': np.tile(year, len(countries)),
'Avg1': np.tile(np.arange(len(year)), len(countries)),
'Avg2': 10*np.tile(np.arange(len(year)), len(countries))})
df['Year'] = (df['Year'].astype('i8')-1970).view('datetime64[Y]')
df = df.pivot(index='Year', columns='Country')
df = df.resample('A').mean()
df = df.interpolate(method='time')
df = df.stack('Country')
df = df.reset_index()
df = df.sort_values(by=['Country', 'Year'])
print(df)
产量
Year Country Avg1 Avg2
0 1950-12-31 Australia 0.000000 0.000000
3 1951-12-31 Australia 0.199890 1.998905
6 1952-12-31 Australia 0.400329 4.003286
9 1953-12-31 Australia 0.600219 6.002191
12 1954-12-31 Australia 0.800110 8.001095
15 1955-12-31 Australia 1.000000 10.000000
18 1956-12-31 Australia 1.200328 12.003284
21 1957-12-31 Australia 1.400109 14.001095
...
-
本文向大家介绍如何找到R数据帧的列值之和?,包括了如何找到R数据帧的列值之和?的使用技巧和注意事项,需要的朋友参考一下 R数据框包含可能代表相似类型变量的列;因此,我们可能希望找到每个列的值的总和,然后基于该总和进行比较。这可以借助sum函数来完成,但是首先我们需要提取列以找到和。 示例 请看以下数据帧- 找出所有列的总和- 让我们再看一个例子-
-
我试图修改数据帧以仅包含列中的值介于99和101之间的行,并尝试使用下面的代码执行此操作。 然而,我得到了错误 ValueError:序列的真值不明确。使用a.empty、a.bool()、a.item()、a.any()或a.all() 我想知道是否有一种不用循环就能做到这一点的方法。
-
本文向大家介绍如何使用grepl函数对R数据帧的行进行子集化?,包括了如何使用grepl函数对R数据帧的行进行子集化?的使用技巧和注意事项,需要的朋友参考一下 R中的grepl函数在R数据帧的字符向量或列的每个元素内搜索与参数模式的匹配项。如果我们想使用grepl对R数据帧的行进行子集化,则可以通过访问包含字符值的列来使用带有单方括号和grepl的子集。 例1 请看以下数据帧: 输出结果 通过在x
-
我设法在一个图形上显示来自同一数据帧的两个散点图,并尝试将同一行中的点与图形上的一条线连接起来。任何人都可能知道我如何做到这一点?谢谢
-
本文向大家介绍如何在R数据帧的列中查找唯一值?,包括了如何在R数据帧的列中查找唯一值?的使用技巧和注意事项,需要的朋友参考一下 分类变量具有多个类别,但是如果数据集很大且类别也很大,那么识别它们就会有些困难。因此,我们可以为分类变量提取唯一值,这将有助于我们轻松识别分类变量的类别。我们可以通过对R数据帧的每一列使用唯一的方法来做到这一点。 示例 请看以下数据帧- 在列x1中找到唯一值- 在列x2中
-
本文向大家介绍如何基于R数据帧列的值获取行索引?,包括了如何基于R数据帧列的值获取行索引?的使用技巧和注意事项,需要的朋友参考一下 R数据帧的一行可以在列中具有多种方式,并且这些值可以是数字,逻辑,字符串等。基于行号查找值很容易,但是基于值查找行号却很不同。如果要在特定列中查找特定值的行号,则可以提取整行,这似乎是一种更好的方法,可以使用单个方括号来获取行的子集。 示例 请看以下数据帧- 输出结果