
谷歌编码挑战题2020:未指定的单词

我在2020年8月16日发生的Google编码挑战赛中遇到了以下问题。我试图解决它,但没有成功。
字典中有N个单词,每个单词都是固定长度的,M只由小写英文字母组成,即('a',b',…,'z')
查询词由Q表示。查询词的长度为M。这些单词包含小写英文字母,但在某些地方不是字母介于“a”、“b”、…、'z’有'?'
。请参阅示例输入部分以了解这种情况
Q的匹配计数,由匹配计数(Q)表示,是字典中包含与查询词Q中字母相同位置的相同英文字母(不包括可以位于?位置的字母)的单词的计数。换句话说,词典中的一个单词可以包含位于'?'位置的任何字母
但其余字母必须与查询词匹配
给您一个查询词Q,您需要计算match\u count
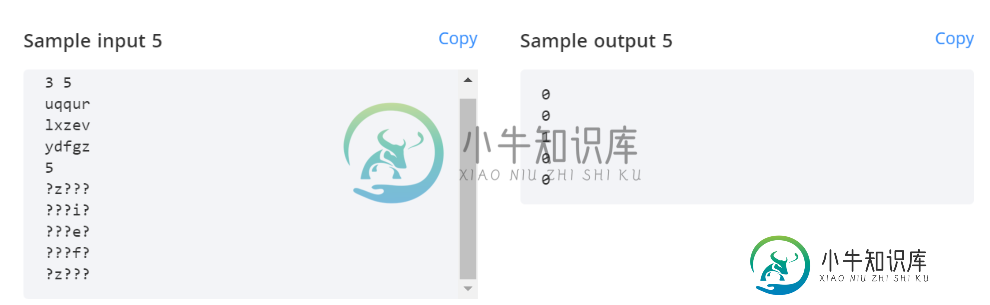
输入格式
第一行包含两个空格分隔的整数N和M分别表示字典中的单词数和每个单词的长度。- 接下来的
N行分别包含字典中的一个单词。 - 下一行包含一个整数Q,表示必须计算match_count的查询字数。
- 接下来的
Q行每行包含一个查询词。
输出格式对于每个查询词,在新行中打印特定词的match\u count
约束
1 <= N <= 5X10^4
1 <= M <= 7
1 <= Q <= 10^5


因此,我有30分钟的时间回答这个问题,我可以编写以下错误的代码,因此没有给出预期的输出
def Solve(N, M, Words, Q, Query):
output = []
count = 0
for i in range(Q):
x = Query[i].split('?')
for k in range(N):
if x in Words:
count += 1
else:
pass
output.append(count)
return output
N, M = map(int , input().split())
Words = []
for _ in range(N):
Words.append(input())
Q = int(input())
Query = []
for _ in range(Q):
Query.append(input())
out = Solve(N, M, Words, Q, Query)
for x in out_:
print(x)
有人能帮我用一些伪代码或算法来解决这个问题吗?
共有3个答案

它应该是O(N)时间和空间方法,因为M很小,可以认为是常数。您可能想在这里看看Trie的实现。
执行第一遍并将单词存储在Trie DS中。
接下来,按照以下顺序执行DFS和BFS的组合。
如果您收到一个?,执行BFS并添加所有子级。对于非?,执行DFS,这应该指向一个单词的存在。
为了进一步优化,后缀树也可用于存储DS。

这个问题可以在Trie数据结构的帮助下完成。首先将所有单词添加到trie ds中。然后你必须看看单词是否存在于trie中,有一个特殊的条件“?”所以你也必须注意这个条件,比如如果字符是?然后简单地转到单词的下一个字符。
我认为这种方法会奏效,Leetcode中也有类似的问题。
链接:https://leetcode.com/problems/design-add-and-search-words-data-structure/

我想我的第一次尝试是将查询中的?替换为.,即将? at更改为. at,然后将它们用作正则表达式并将它们与字典中的所有单词匹配,就像这样简单:
import re
for q in queries:
p = re.compile(q.replace("?", "."))
print(sum(1 for w in words if p.match(w)))
然而,看到输入大小为N到5x104和Q到105,这可能太慢了,就像任何其他算法比较所有单词和查询对一样。
另一方面,请注意,每个单词的字母数M是恒定的,并且相当低。因此,您可以为所有位置的所有字母创建Mx26组单词,然后获得这些集合的交点。
from collections import defaultdict
from functools import reduce
M = 3
words = ["cat", "map", "bat", "man", "pen"]
queries = ["?at", "ma?", "?a?", "??n"]
sets = defaultdict(set)
for word in words:
for i, c in enumerate(word):
sets[i,c].add(word)
all_words = set(words)
for q in queries:
possible_words = (sets[i,c] for i, c in enumerate(q) if c != "?")
w = reduce(set.intersection, possible_words, all_words)
print(q, len(w), w)
在最坏的情况下(具有字典中大多数或所有单词通用的非?字母的查询),这可能仍然很慢,但在过滤单词方面应该比迭代每个查询的所有单词快得多。(假设单词和查询中都有随机字母,第一个字母的单词集将包含N/26个单词,前两个字母的交集有N/26²个单词,等等。)
这可能可以通过考虑不同的情况来改进,例如(a)如果查询不包含任何?,只需检查它是否在单词的集中(!),而不创建所有这些交集;(b)如果查询是all-?,只需返回所有单词的集合;(c)按大小对可能的单词集进行排序,并首先使用最小的集合开始交集,以减少临时创建的集合的大小。
关于时间复杂度:老实说,我不确定这个算法的时间复杂度是多少。当N、Q和M分别为字数、查询数和字数和查询长度时,创建初始集的复杂性为O(N*M)。之后,查询的复杂性显然取决于非代码的数量 以及要创建的集合交点的数量,以及集合的平均大小。对于具有零、一或M非代码的查询 字符,查询将在O(M)中执行(评估情况,然后进行单个集合/字典查找),但对于具有两个或更多非代码的查询 -字符,第一组交叉点的平均复杂度为O(N/26),严格来说仍然是O(N)。(以下所有交叉口只需考虑N/26²、N/26³等要素,因此可以忽略不计。)我不知道这与Trie方法相比如何,如果其他任何答案能够详细说明这一点,我将非常感兴趣。
-
这个程序的目的是得到一个像“1256”这样的长变量,然后逐个数字相加,直到剩下一个个位整数。所以,,返回。 当我尝试验证时,它会给出错误: com.google.challenges.中找不到参数(int)的公共静态方法答案 有人能帮我理解这个错误的含义以及如何修复它吗?
-
CodingBat中的给定任务sameEnds: 给定一个字符串,返回出现在字符串开头和结尾且不重叠的最长子字符串。例如,sameEnds(“abXab”)是“ab”。 我的解决方案通过了所有测试,除了一个^: 这里有什么问题?我怎样才能修复它?
-
给定CodingBat中的任务maxBlock: 给定一个字符串,返回字符串中最大“块”的长度。块是相同的相邻字符的运行。 我的解决方案通过了所有测试,除了一个:
-
这个问题要求在键盘上键入字符串所需的总时间,用一个手指表示为二维字符矩阵。 输入: 第一行包含n和m作为输入,表示键盘矩阵的维数 接下来的n行包含m个字符,每个字符表示键盘中的字符 下一行将包含字符串S 输出: 说明:手指最初位于键盘的第一个符号,因此按下该键所需的时间为0。之后,新键位于1,1,因此总时间为|1-0||1-0|即2。现在第三个键位于位置1,2,因此移动到该键的总时间为|2-1||
-
问题内容: 据说SpringLayout非常强大。我试图使用SpringLayout实现我认为是相当简单的布局,但是我失败了。 减少到最低限度,我希望在JFrame上并排放置4个JButton: 我希望所有4个文本的大小相同,无论文本如何不同。 我希望最外面的一个(b1和b4)与容器的边界之间保持恒定的水平距离,即5 px,并且与按钮的南北之间的边界都保持5 px,它们的高度均相同。 我希望按钮之
-
问题内容: 我有以下提供商列表(俄语): 这些显然是在unicode中。以前,要执行SQL SELECT,我正在做: 现在,由于列表项使用的是unicode,因此我遇到了。 我将如何正确执行此sql语句? 问题答案: 您不应该用来在sql查询中包含值。改用sql参数: 原始清单在哪里。 想法是使用与列表中提供者数量匹配的SQL参数语法,通过测试生成SQL查询:对于两个提供者的列表。是的,MySQL