
Pandas:从返回数据创建索引时间序列[从100开始]

我有关于Pandas数据帧中变量的对数返回的数据。我想把这些返回变成一个索引时间序列,它从100(或任意数字)开始。这种操作非常常见,例如在创建通货膨胀指数或比较两个不同幅度的系列时:
因此,例如,2000年1月1日中的第一个值设置为等于100,2000年1月2日中的下一个值等于100*exp(return_2000_01_02),依此类推。以下示例:
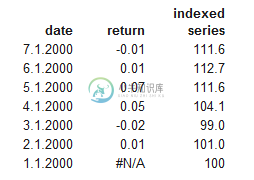
我知道我可以使用.iterItems()在Pandas DataFrame中循环遍历行,如以下问题所示:逐行遍历Pandas DataFrame
有没有一种方法可以使用纯熊猫创建一个索引时间序列?如果不是,请你建议一下最有效的方法。找到解决方案是出奇的困难,因为索引和索引在熊猫中有一个特定的含义,我不是在这次之后。
共有1个答案

您可以使用矢量化方法而不是循环/迭代:
import pandas as pd
import numpy as np
df = pd.DataFrame({'return':np.array([np.nan, 0.01, -0.02, 0.05, 0.07, 0.01, -0.01])})
df['series'] = 100*np.exp(np.nan_to_num(df['return'].cumsum()))
#In [29]: df
#Out[29]:
# return series
#0 NaN 100.000000
#1 0.01 101.005017
#2 -0.02 99.004983
#3 0.05 104.081077
#4 0.07 111.627807
#5 0.01 112.749685
#6 -0.01 111.627807
-
我有一个数据框,我正在使用TIA来填充彭博社的数据。当我看着df。索引我看到我打算成为列的数据以多索引的形式呈现给我。df的输出。列是这样的: 索引([u'column1','u'column2']) 我尝试过各种reset_index的迭代,但都无法补救这种情况。 1) TIA管理器如何使数据帧列作为索引读入? 2) 如何正确地将这些列标识为列而不是多索引? 我试图解决的最终问题是,当我尝试将此
-
问题内容: 我有一个由列表列表组成的Numpy数组,代表带有行标签和列名的二维数组,如下所示: 我希望所得的DataFrame将Row1和Row2作为索引值,并将Col1,Col2作为标头值 我可以指定索引如下: 但是我不确定如何最好地分配列标题。 问题答案: 您需要指定,并以构造函数,如: 编辑 :如@joris注释中所示,您可能需要更改上述内容才能具有正确的数据类型。
-
问题内容: 我需要为InvoiceID生成一列。我想像这样保留本专栏的内容 如您所见,此列随着上一个索引的增加而增加。我怎样才能做到这一点。 我正在使用SQL Server 2012。 我已经搜索了,但找不到如何增加这样的数字。 问题答案: 尝试使用 MSDN SQLFIDDLE演示 关于为什么你需要让你的计算列的详细信息 检查 这里
-
我有一个返回dict对象的函数,我想利用pandas/numpy在数据帧的每一行上为该函数执行列操作/向量化的能力。函数的输入在dataframe中指定,我希望函数的输出成为现有dataframe上的新列。下面是一个例子。 期望输出: 我读了这个答案,大部分内容都是这样的,但是当函数返回一个dict对象,其中包含所需的列名作为dict中的键时,我不太明白该怎么做。
-
我有一个Numpy数组,由一系列列表组成,表示一个二维数组,其中包含行标签和列名,如下所示: 但是,我不确定如何最好地分配列标题。
-
好的,我已经成功地将一个列表变成了一个二维数组。唯一的问题是输出只索引一次,所以基本上,如果我想将每个列表中的10个元素添加到一个二维数组中,那么这个二维数组将只有一个包含“n”个元素的索引。 例如 我愿意 相反,它正在返回: 我接受了以下建议:将ArrayList转换为包含不同长度数组的2D数组 这是我的代码: 我正在使用数据提供者(DataProviders)和TestNG,它们需要返回一个二