
在dataframe python中的和列(每行不同的列)[重复]

我有一个数据框,有3列a, b, c,如下所示:
df=pd。DataFrame({'a':[1,1,5,3],'b':[2,0,6,1],'c':[4,3,1,4]})
我想添加列d,它是df中一些列的总和,但不是每行的同一列,例如
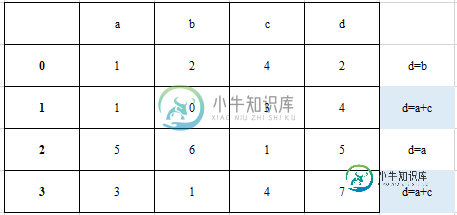
只有第1行和第3行是同一列的和,第0行和第2行是其他列的和。
我在Stack over flow上发现的总是整个数据帧的特定列,但在本例中是不同的。
我能做的最好的方法是什么?
共有2个答案

根据[此解决方案][1],动态方式使用pd.eval()。这将分别计算每一行的公式,这允许df['formula']在每一行上不同,并且代码中没有硬编码的内容。这一行中有大量的内容,请参见下面注释中的解释。
df.apply(lambda row: pd.eval(row['formula'], local_dict=row.to_dict()), axis=1)
0 2
1 4
2 5
3 4
# ^--- this is the result
如果您想将结果分配给数据框列,请说df['z']:
df['z']=df.apply(lambda行:pd.eval(行['formula'],local_dict=row.to_dict()),axis=1)- 或者,您可以使用
pd.eval(…,inplace=True),但是公式需要包含实际赋值,例如“z=ab”,并且“z”列需要已经声明:df['z']=np.NaN。这部分实现起来有点烦人,所以我没有
注:
- 我们使用
pd.eval(…)动态评估['formula']列
- 当我们像这样以行方式调用
df.apply(...,轴=1)时,每行都作为一个单独的系列传递进来,因此在我们的应用(...轴=1)中,我们不能再引用数据框为df或其列为df['a'],df['b'],... - 因此,我们需要将该行作为Python判决传递,因此在lambda函数中,local_dict=row.to_dict()参数为
pd.eval。
引用:[1]:从变量中的字符串公式计算dataframe列?

因为列d是随机计算的,所以对每行执行此操作的唯一方法是单独计算。
df['d'] = 0
df['d'].iloc[0] = df['b'].iloc[0]
df['d'].iloc[1] = df['a'].iloc[1] + df['c'].iloc[1]
df['d'].iloc[2] = df['a'].iloc[2]
df['d'].iloc[3] = df['a'].iloc[3] + df['c'].iloc[3]
如果是第1行和第3行,则有一个规则:
df['d'].loc[(df.index % 2)==1] = df['a'].iloc[df.index] + df['c'].iloc[df.index]
另外,对于循环:
for i in range(0, 4):
if i % 2 == 1:
df['d'].iloc[i] = df['a'].iloc[i] + df['c'].iloc[i]
-
问题内容: 我有交易数据框。每行代表两个项目的交易(可想而知,就像两张事件票之类的交易一样)。我想根据售出的数量重复每一行。 这是示例代码: 这将产生一个看起来像这样的数据框 因此,在上述情况下,每一行将转换为两个重复的行。如果“数量”列为3,则该行将转换为三个重复的行。 问题答案: 首先,我使用整数而不是文本重新创建了您的数据。我还更改了数量,以便可以更轻松地理解问题。 我通过使用嵌套列表理解结
-
在C#中,我可以制作一个列表并向其添加不同类型的项。只要它们继承基类即可。例如: Rust不是面向对象编程语言,但我想知道是否可以实现类似的功能。有办法吗?
-
我希望折叠与给定列的值匹配的数据帧行,但必须使用不同的逻辑折叠其余列。例子: 例如,我希望按城市折叠,我希望ColumnA保持最低值,ColumnB保持平均值。结果应该如下所示: 这只是一个例子,在我的实际问题中,我想应用更复杂的逻辑,而不是min()或mean()。 做这件事的正确、干净和最简单的方法是什么?非常感谢。
-
问题内容: 我有一个带有 N 列的表。让我们给他们打电话,,,,… 。在多行中,我想为[1,N]中的每个X获得单个行。 有没有一种方法(在存储过程中)而无需手动将每个列名写入查询中呢? 我们遇到了一个问题,即应用程序服务器中的错误意味着我们在以后插入垃圾时重写了良好的列值。为了解决这个问题,我存储了信息日志结构,其中每一行代表一个逻辑查询。然后,在给出记录已完成的信号时,我可以确定是否有任何值(错
-
我正在尝试使用GridLayoutManager构建一个RecyclerView,它每行有一个可变的列计数,如下所示: 同一行中所有项目的宽度之和将始终为屏幕宽度。 我试图重新组织项目列表,按行列表分组,然后每行膨胀一个线性布局。它不太好。 所以我被困住了,没有任何想法。任何帮助都将非常感激
-
问题内容: 我试图弄清楚如何为给定列中的每个不同值重置mysql中的行号。最好用一个例子来解释一下: 我有一组进行客户访问的用户,每个客户可能会被访问多次,并且我的表记录了访问的日期(但不是这是第一次,第二次,第三次访问)。所以我的桌子看起来像: 我要查找的是给定日期段内进行了多少次(例如)第二次访问。因此,在上面的数据中,有3次首次访问和2次第二次访问。 我假设我需要使用类似@rownum功