
Google cloud自然语言API添加自己的上下文分类器

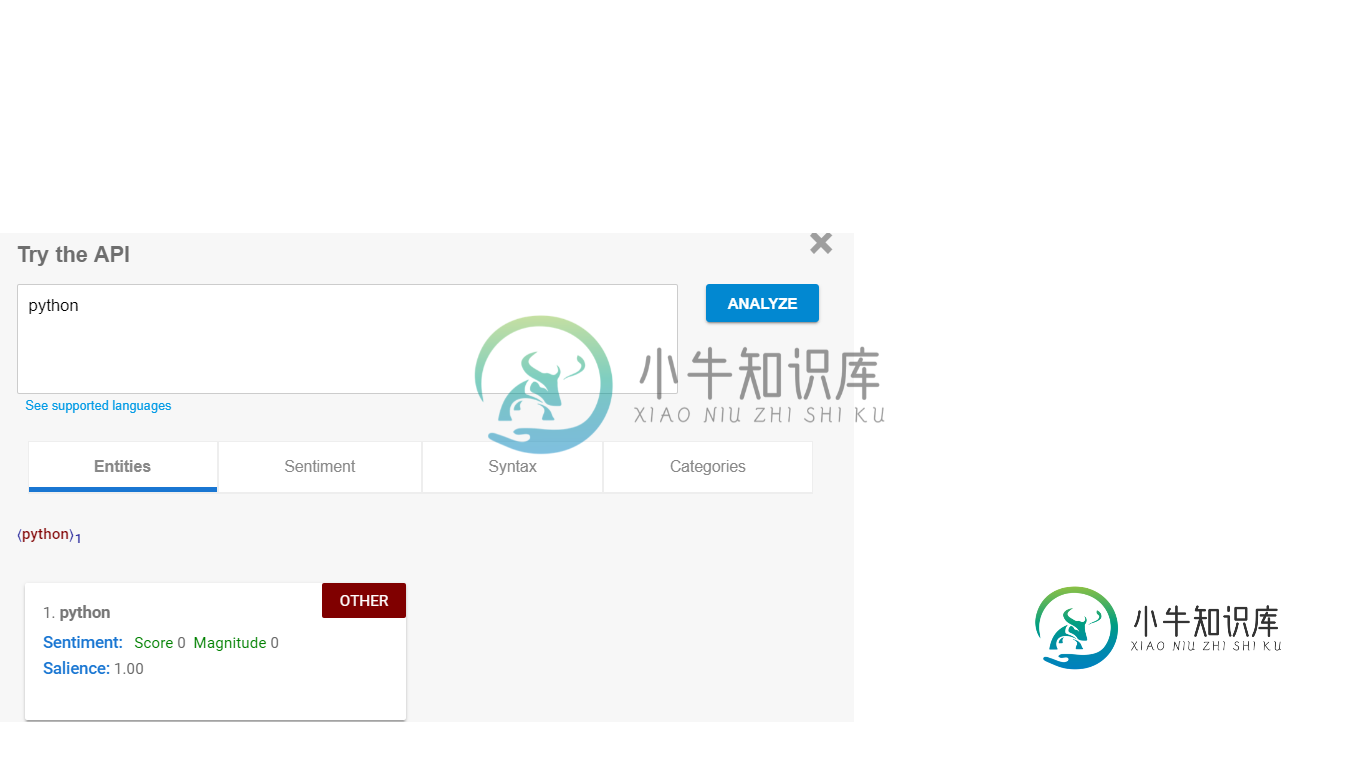
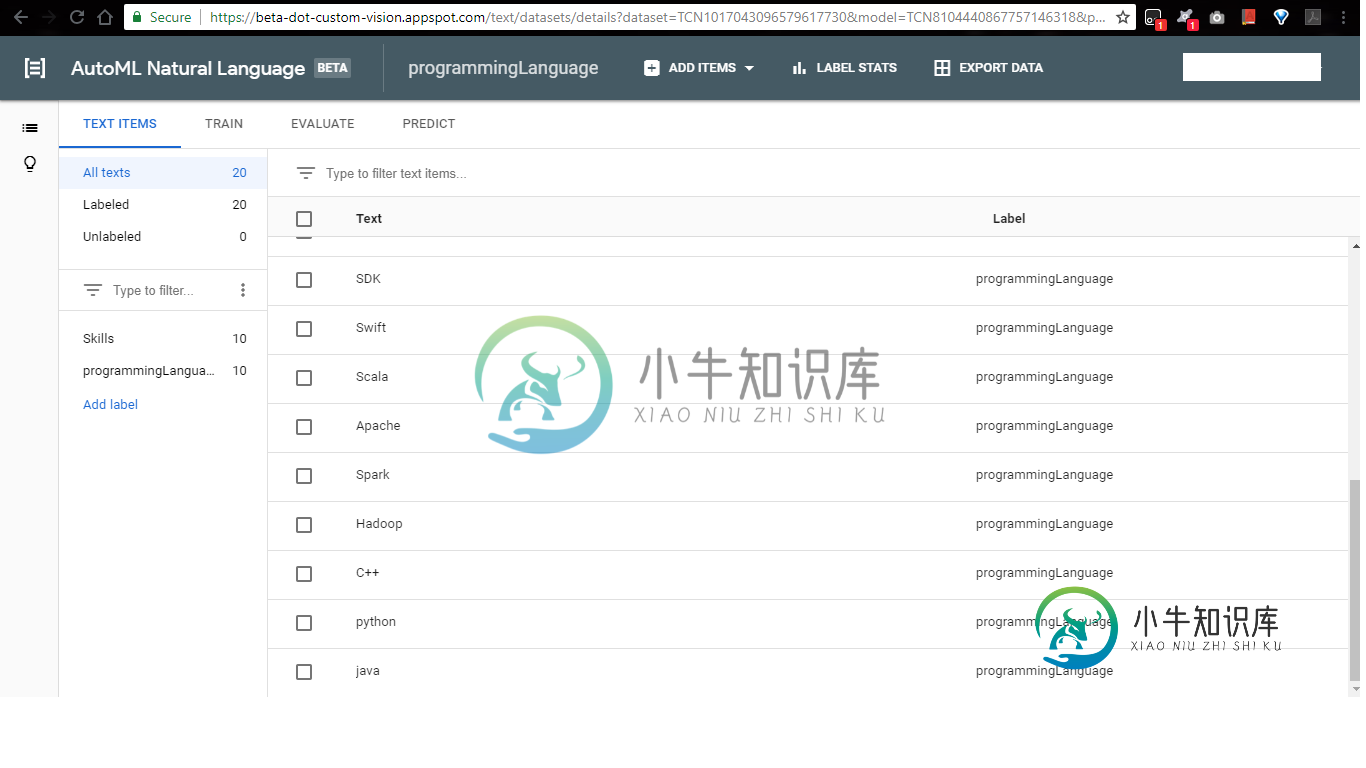
谢谢你的帮助,我们将不胜感激。
共有1个答案

Automl内容分类将数据分类到训练集中指定的标签中。它不进行实体检测。但似乎您需要做的更接近于内容分类,而不是实体检测。从你提供的描述中我的理解是,你有内容(可能是单词或短语或短句),你想把它们归类到一些标签中(例如programmingLanguage)。如果你把一个好的训练集放在一起,automl模型应该能够做到这一点。它在eval中提供的数字不是情绪,而是预测标签的概率。正如您在发布的评估页面中所看到的,它告诉您java是一种概率为1的编程语言(因此,这是非常确定的)。
-
先来一段前戏 机器学习的过程是训练模型和使用模型的过程,训练就是基于已知数据做统计学习,使用就是用统计学习好的模型来计算未知的数据。 机器学习分为有监督学习和无监督学习,文本分类也分为有监督的分类和无监督的分类。有监督就是训练的样本数据有了确定的判断,基于这些已有的判断来断定新的数据,无监督就是训练的样本数据没有什么判断,完全自发的生成结论。 无论监督学习还是无监督学习,都是通过某种算法来实现,而
-
我想开发一个应用程序,将检测重复的句子或问题。我可以使用云自然语言API服务来检测重复句子吗?
-
我的测试表明,我使用哪个角色其实并不重要。甚至像“BigQuery MetadataViewer”这样的东西也会授予对NLP API的访问权限?!然而,我想使用正确的角色,而不是一个随机的,在某些时候,东西会打破。 更令人困惑的是,API keys文档说NLP API只能通过API-key访问,但NLP文档本身告诉您使用服务帐户。我猜API密钥是遗留信息…
-
我正在做关于口头证词转录的情感分析的论文,对于Google Cloud的自然语言API V1Beta2背后的编程有几个问题/澄清。 我对任何答案都持开放态度。此外,如果任何人知道任何官方的谷歌文件列出了这些信息,也将非常感谢。谢谢你。
-
主要内容 前言 课程列表 推荐学习路线 数学基础初级 程序语言能力 机器学习简介 自然语言学习初级 数学和机器学习知识补充 自然语言处理中级 自然语言处理专项领域学习 前言 我们要求把这些课程的所有Notes,Slides以及作者强烈推荐的论文看懂看明白,并完成所有的老师布置的习题,而推荐的书籍是不做要求的,如果有些书籍是需要看完的,我们会进行额外的说明。 课程列表 课程 机构 参考书 Notes
-
一个人选用一个语言的理由可能是很少的,比如觉得开发效率高,觉得适合做网页,需求要求,或者甚至只因为作者长得帅;想要造一个语言的理由就比较多了,比如觉得xx语言写起来太麻烦,xx语言不安全,xx语言太慢,xx语言的风格不符合自己的审美等等 最早产生这个想法是09年,看完python的源码剖析后感觉编译原理里面的一些东西串起来了,其实大学就学过,只不过那时候大部分时间用来学lex和yacc怎么用,结果