
关于纱线团簇上有缩线的平行度问题

作为Apache Flink的新手,以及流处理框架的一般情况下,我有几个关于它的问题,特别是关于并行性的问题。
首先,这是我的代码:
object KafkaConsuming {
def main(args: Array[String]) {
// **** CONFIGURATION & PARAMETERS ****
val params: ParameterTool = ParameterTool.fromArgs(args)
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(8)
env.getConfig.setGlobalJobParameters(params)
// **** Kafka CONNECTION ****
val properties = new Properties();
properties.setProperty("bootstrap.servers", params.get("server"));
// **** Get KAFKA source ****
val stream: DataStream[String] = env.addSource(new FlinkKafkaConsumer010[String](params.get("topic"), new SimpleStringSchema(), properties))
// **** PROCESSING ****
val logs: DataStream[MinifiedLog] = stream.map(x => LogParser2.parse(x))
val sessions = logs.map { x => (x.timestamp, x.bytesSent, 1l, 1)}
val sessionCnt: DataStream[(Long, Long, Long, Int)] = sessions
.keyBy(3).window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
.reduce( (x: (Long, Long, Long, Int), y: (Long, Long, Long, Int)) => (x._1, x._2 + y._2, x._3 + y._3, x._4))
.map { z => (z._1, z._2 / 10, z._3 / 10, z._4)}
// **** OUTPUT ****
val output: DataStream[String] = sessionCnt.map(x => (x.toString() + "\n"))
output.writeToSocket("X.X.X.X", 3333, new SimpleStringSchema)
env.execute("Kafka consuming")
}
}
当我想在集群上运行它时,我运行以下命令:
./bin/flink run -m yarn-cluster -yn 8 /directories/myjar.jar --server X.X.X.X --topic mytopic

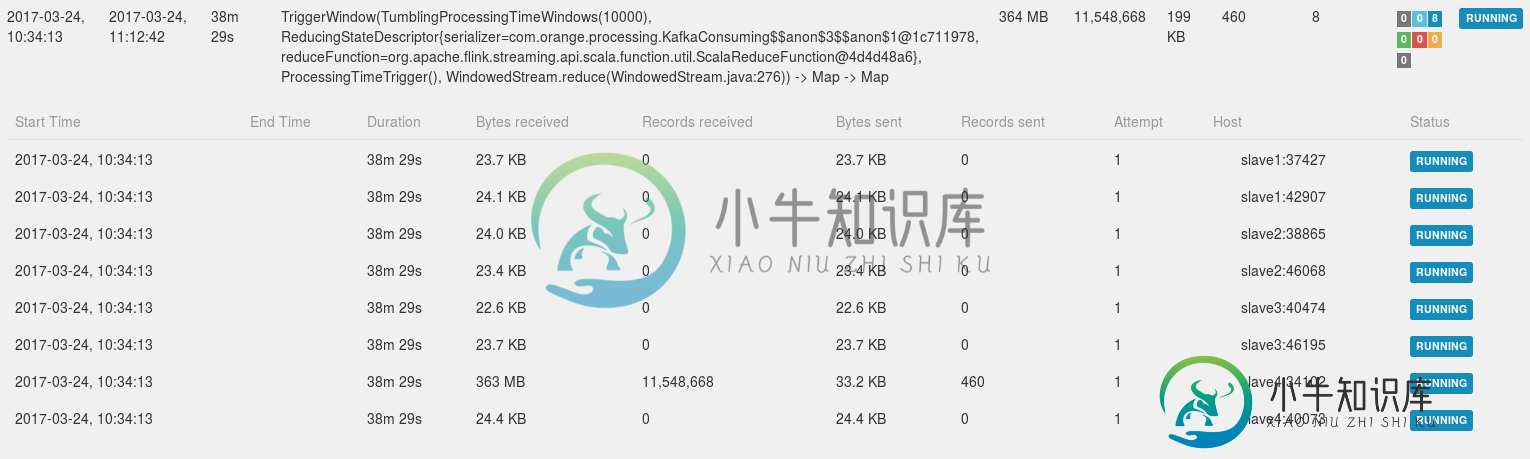
2.为什么Flink没有为这一步使用所有可能的线程?
我注意到源、窗口和接收器由不同的从服务器处理,但我仍然希望在集群上并行处理。
我在这篇文章中读到:https://stackoverflow.com/a/32329010/5035392,如果Kafka源代码只有一个分区(我的情况就是这样),Flink就不能在不同的节点上共享任务。但是,我的窗口处理应该能做到?
如果这些都是琐碎的问题,我很抱歉。我不确定我做错的是Flink还是我的集群配置。谢谢你。
共有1个答案

Ad.2同一键的所有值都在一个TaskManager上处理。在您的示例中,sessions.keyby(3)stream的每个元素都有相同的键->1,因此所有计算都在单个任务槽中执行。
-
我正在AWS EMR集群上使用pyspark3内核运行Jupyterhub。正如我们可能知道的那样,EMR上的Jupyterhub pyspark3使用Livy会话在AWS EMR YARN调度程序上运行工作负载。我的问题是关于火花的配置:执行器内存/内核、驱动程序内存/内核等。 配置中已经有默认配置。Jupyter的json文件: 我们可以改写此配置使用spackMagic: 火花默认值中也有配
-
我正在使用spark submit执行以下命令: spark submit script\u测试。py—主纱线—部署模式群集spark submit script\u测试。py—主纱线簇—部署模式簇 这工作做得很好。我可以在Spark History Server UI下看到它。但是,我无法在RessourceManager UI(纱线)下看到它。 我感觉我的作业没有发送到集群,但它只在一个节点上
-
aws上的3台机器(32个内核和64 GB内存) 我手动安装了带有hdfs和yarn服务的Hadoop2(没有使用EMR)。 机器#1运行hdfs-(NameNode&SeconderyNameNode)和yarn-(resourcemanager),在masters文件中定义 问题是,我认为我做错了,因为这项工作需要相当多的时间,大约一个小时,我认为它不是很优化。 我使用以下命令运行flink:
-
我在Cloudera CDH5.3集群上运行Spark,使用YARN作为资源管理器。我正在用Python(PySpark)开发Spark应用程序。 我正在运行一个提交命令,如下所示: 如何确保作业在集群中并行运行?
-
我无法理解纱线配置。 我在纱线/MapReduce配置中有这样的行: 这里写着: 默认情况下(“yarn.nodemanager.vmem-pmem-ratio”)设置为2.1。这意味着map或reduce容器最多可以分配2.1倍(“MapReduce.reduce.memory.MB”)或(“MapReduce.map.memory.MB”)的虚拟内存,然后NM才会杀死该容器。 我能得到更好的解