
Springboot Maven项目从不运行垃圾收集

我有一个Springboot Maven项目,它使用@JmsListener从队列中读取消息。
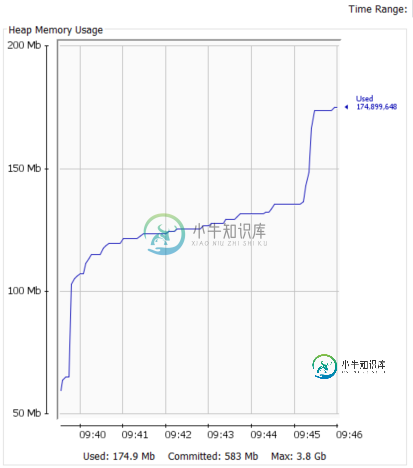
如果没有事件进来,堆内存会慢慢增加。当消息传来时,堆内存会快速增加。但是堆内存永远不会下降(查看下图)。
如果我添加系统。gc()在receiver方法的末尾,垃圾收集器正在按预期完成其工作。但这绝对不是好的做法。
如何确保gc在适当的时间运行。任何帮助都将不胜感激!
堆内存使用率
接收方法
@JmsListener(destination = "${someDestination}", containerFactory = "jmsListenerContainerFactory")
public void receiveMessage(Message message){
if (message instanceof BytesMessage) {
try {
List<Trackable> myList;
BytesMessage byteMessage = (BytesMessage) message;
byte[] byteData = new byte[(int) byteMessage.getBodyLength()];
byteMessage.readBytes(byteData);
DocumentBuilder dBuilder = DocumentBuilderFactory.newInstance().newDocumentBuilder();
Document doc = dBuilder.parse(new InputSource(new StringReader(new String(byteData))));
TransformerFactory factory = TransformerFactory.newInstance();
factory.setFeature(XMLConstants.FEATURE_SECURE_PROCESSING, true);
Transformer transformer = factory.newTransformer();
StringWriter writer = new StringWriter();
transformer.transform(new DOMSource(doc.getElementsByTagName(SOME_TAG_NAME).item(0)), new StreamResult(writer));
String outputXmlString = writer.getBuffer().toString();
XMLInputFactory xmlFactory = XMLInputFactory.newInstance();
XMLStreamReader xmlReader = xmlFactory.createXMLStreamReader(new StringReader(outputXmlString));
JAXBContext jaxbContext = JAXBContext.newInstance(ObjectFactory.class);
MyEvent myEvent = ((JAXBElement<MyEvent>) jaxbContext.createUnmarshaller().unmarshal(xmlReader)).getValue();
myList = myService.saveEvent(myEvent);
LOGGER.info(String.format("Received message with EventID: %s and successfully inserted into database", myEvent.getID()));
} catch (Exception e) {
LOGGER.error(e.getClass().getCanonicalName() + " in Receiver: ", e);
}
} else {
LOGGER.error("Received unsupported message format from MQ");
}
}
共有1个答案

为什么?因为JVM决定(基于其启发式)现在还不是运行的时候。但何时运行取决于堆大小和GC算法。一般来说,运行GC循环绝不是免费的操作——它至少需要GC循环停止应用程序一段时间(称为stop the worldevents)。因此,GC算法在需要时运行。
当您使用并发收集器(例如ZGC或shenandoah)时,它们是否运行并不重要;这是因为它们是并发的:它们在您的应用程序运行时运行。它们确实有stop-the-world暂停-但这些非常小(例如在某些情况下与G1GC不同)。由于这种并发性,它们可以被迫“每X秒”运行一次;shenandoah有-XX: shenandoah保证GCInterval=10000(我们在生产中使用它)。
但是我假设您正在使用G1GC(即如果您根本不启用GC,这就是您得到的)。这个特定的GC主要是并发的,并且是分代的。它将堆拆分为年轻区域和旧区域,并独立收集它们。年轻区域是在STW暂停下收集的,而Full GC(收集旧区域)主要是并发的:它可以将STW暂停延长到分钟,字面上,但这不是一般情况。
因此,当您使用G1GC时,当所有年轻伊甸园区域(年轻区域在伊甸园和幸存者中进一步分裂)都已满时,将触发年轻GC循环。当发生以下3种情况之一时,将触发完整GC循环:
1) IHOP is reached
2) G1ReservePercent is reached
3) a humongous allocation happens (an allocation that spans across multiple regions - think huge Objects).
但这是一个相当简单且不完整的画面,描述了G1GC发生GC循环的时间,主要是因为这三者中的任何一个都会触发一个标记阶段(整个GC的某一部分),该阶段将根据从各个区域收集的数据决定下一步要做什么。它通常会立即触发一个年轻的GC,然后触发一个混合集合,但可能会选择不同的路径(同样,基于GC拥有的数据)。
因此,总的来说,您对堆的压力太小,无法启动GC循环,而且大部分时间-这正是您想要的。
-
Kubernetes 垃圾收集器的角色是删除指定的对象,这些对象曾经有但以后不再拥有 Owner 了。 注意:垃圾收集是 beta 特性,在 Kubernetes 1.4 及以上版本默认启用。 Owner 和 Dependent 一些 Kubernetes 对象是其它一些的 Owner。例如,一个 ReplicaSet 是一组 Pod 的 Owner。具有 Owner 的对象被称为是 Owner
-
垃圾回收 我们对生产中花了很多时间来调整垃圾回收。垃圾回收的关注点与Java大致相似,尽管一些惯用的Scala代码比起惯用的Java代码会容易产生更多(短暂的)垃圾——函数式风格的副产品。Hotspot的分代垃圾收集通常使这不成问题,因为短暂的(short-lived)垃圾在大多情形下会被有效的释放掉。 在谈GC调优话题前,先看看这个Attila的报告,它阐述了我们在GC方面的一些经验。 Scal
-
对于开发者来说,JavaScript 的内存管理是自动的、无形的。我们创建的原始值、对象、函数……这一切都会占用内存。 当我们不再需要某个东西时会发生什么?JavaScript 引擎如何发现它并清理它? 可达性(Reachability) JavaScript 中主要的内存管理概念是 可达性。 简而言之,“可达”值是那些以某种方式可访问或可用的值。它们一定是存储在内存中的。 这里列出固有的可达值的
-
垃圾收集,引用计数,显式分配 和所有的现代语言一样,OCaml提供垃圾收集器,所以你不用像C/C++一样显式地分配和释放内存。 JWZ在他的文章 "Java sucks" rant(Java蛋疼(怒)!): 第一个好家伙是Java没有 free()。其他的都没有所谓了。这几乎掩盖了所有的缺点,不管有多糟糕, 这个有点让后续文档基本都没有意义了,但是...(译注:但是啥大家自己看吧) OCaml的垃
-
我刚刚接触到一个项目,他们让我调查服务器(应用程序)为什么会表现得很奇怪。重新启动后,它们的速度非常快( 内存和CPU上升,直到应用程序重新启动才会下降。 所以他们正在运行一个Tomcat(hybris)服务器,该服务器具有以下命令行标志:-XX:congcthreads=1-XX:G1HeapRegionSize=4194304-XX:GCLogFileSize=786432-XX:Initia
-
本文向大家介绍Java垃圾收集,包括了Java垃圾收集的使用技巧和注意事项,需要的朋友参考一下 示例 C ++方法-新增和删除 在像C ++这样的语言中,应用程序负责管理动态分配的内存所使用的内存。当使用new运算符在C ++堆中创建对象时,需要相应地使用delete运算符来处置该对象: 如果程序忘记了delete一个对象而只是“忘记”了该对象,则关联的内存将丢失给应用程序。这种情况的术语是内存泄