
图上DFS的非递归方法

我正在做运动,我有点困了,需要一些帮助。假设有向图上有以下顶点和边:AB、BC、AD、CD、DC、DE、CE、EB、AE,如下所示
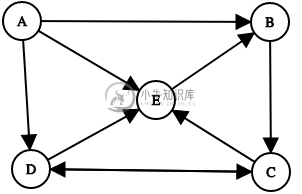
到目前为止,我已经设法通过使用DFS和递归来解决这个问题。我跟踪深度(即距离源有多少边),当深度超过3时,递归函数返回。
我现在想做的是不使用递归来解决它,也就是说,使用堆栈,但我卡住了!如果我使用以下类似的东西(伪代码):
s.create() <- create stack
s.push(nodeA)
depth = 0
while !s.empty
n = s.pop()
foreach (n.connectedVertices as c)
s.push(c)
depth++
那么我就无法知道每个顶点应该在哪个深度。我一直在考虑以某种方式使用一堆堆栈(为每个深度保存?)但我还没弄明白。
任何帮助都将不胜感激。
共有1个答案

可以通过在堆栈中推动对来实现这一点
该对将包含(节点、深度)
现在开始推送(节点,0)。
s.create()
s.push(nodeA , 0)
while !s.empty
cur_node , depth = s.pop()
if depth==3
continue // if depth = 3 then we don't need to push anything .
for each node connected with cur_node
s.push(node , depth + 1)
我希望你知道我们如何计算答案。
-
我在深度优先搜索算法实现的递归方法方面遇到了一些麻烦。这是二叉树照片: 该方法在树的右侧(55、89、144)工作得很好,但是当它来到左侧时,它返回nil,即使它输入“是”。那么,代码有什么问题呢?节点是Node类的一个实例,它具有值(整数)并链接到左右子级(Node类的其他实例),如果它没有来自该侧的子级,则为nil。 下面是方法代码:
-
这个问题不是为作业做的,尽管它是一个典型的“类似作业”的问题,我试图用不同的方法来解决。 我想写一个方法,它将使用深度优先搜索算法递归地遍历二叉树,以找到字符的匹配。一旦它找到匹配的字符,我希望它返回一个字符串,该字符串使用0和1映射该字符在树中的位置。例如,“001”将指示通过到根节点的左节点、该节点的左节点,然后到该节点的右节点来找到字符。 下面是我目前拥有的代码: 该方法最初被发送要搜索的字
-
我有两个非递归方法,其中一个读取字符串中的总“e”字符,另一个检查 ArrayList 是否按字母顺序排列。 递归方法的定义是方法调用自身。我相信我理解这个概念,但要实现它或将其转换为递归方法确实很困难。我怎样才能将这些方法转化为递归方法,同时我应该如何思考?此外,这是我的另一种方法,它只打印出指定数字大小的数字。 条件方法检查数字的第一个数字(从右起)是否大于第二个数字,并再次检查第二个是否大于
-
有没有人看到上述算法存在缺陷?我不是图论方面的专家,但我认为我对递归和迭代有很好的把握,我相信这也是一样的。我想让它在功能上与递归算法等价。它应该维护第一个算法的所有属性,即使不需要这些属性。 当我开始写它的时候,我并不认为我会有三个循环,但结果就是这样。当我环顾谷歌时,我看到了其他的迭代算法,它们只有一个双重嵌套的循环,然而,它们似乎不是从多个来源出发的。(即他们不会发现不连通图的每一个顶点)
-
我正在研究一般图的非递归DFS和BFS。除了前者使用堆栈而不是队列之外,唯一的区别在于它“延迟检查顶点是否已被发现,直到顶点从堆栈中弹出,而不是在推送顶点之前进行此检查”。为什么此“访问”检查顺序不同?或者换句话说,我们可以通过简单地用堆栈替换BFS中的队列来将BFS更改为非递归DFS吗? 我检查了所有我能找到的帖子,比如这个和这个,但是没有一个能澄清这个问题。
-
我认为在这篇文章中粘贴整个类可能代码太多(可能不够相关),所以我在这里显示它们: graph.java depthFirstSearch.java 可能的骑士步骤是这样定义的(在主类中)(使用图的边G): 以下是我试图找到的可能的旅行: 例如,如果我试图通过调用这个递归函数,它应该使用字段上的每个平方返回该平方中所有可能的tour()。 未标记的方块是已经到达的方块,在同一次旅行中不应该再访问了。