
字符数组/字符串如何存储在二进制文件中?

当我使用不同的编译器编译这段代码并在十六进制编辑器中检查输出时,我希望在某个地方找到字符串“南希”。
#include <stdio.h>
int main()
{
char temp[6] = "Nancy";
printf("%s", temp);
return 0;
}
>
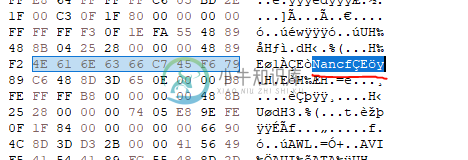
输出为g-o main. c,我看不到找到"Nancy"任何地方。
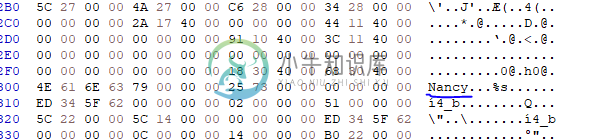
在visual studio(MSVC 1929)中编译相同的代码时,我在十六进制编辑器中看到了完整的字符串:
为什么我在(1)中的字符串中间得到一些随机字节?
共有3个答案

一般来说,编译后的程序被分成不同类型的“节”。汇编程序文件将使用指令在它们之间切换。
- 代码(". text")
- 静态只读数据("。节。rodata")
- 初始化的全局或静态变量(". data")
- 未初始化的全局或静态变量(". bss")
C中的字符串文字可以用两种不同的方式使用。
- 作为指向常量数据的指针
如果字符串文本被用作指针,那么编译器很可能会将字符串数据放在只读数据部分。
如果使用字符串文字初始化全局/静态数组,那么编译器很可能会将该数组放在初始化数据部分(如果数组声明为常量,则放在只读数据部分)。
然而,在你的情况下,你初始化的数组是一个自动的局部变量。所以它不能在程序启动前预初始化。编译器必须包含代码来在每次函数运行时初始化它。
编译器可以选择将字符串存储在只读数据位置,然后使用复制例程(内联或调用)将其复制到本地数组。它可以选择简单地生成指令来逐个加载数组的元素。它可以选择生成同时加载多个数组元素的指令。
另外,我注意到一些人在这个问题的其他答案上发布了戈德博尔特链接。戈德博尔特是一个有用的工具,但是要注意,默认情况下,它会从汇编输出中隐藏部分切换指令。

我用gcc 9.3.0(LinuxMint 20.2)在x86-64系统(Intel
HEXTDUMP-C的结果:
注意字节序列是相同的。
所以我使用了gcc-S-c:
.file "teststr.c"
.text
.section .rodata
.LC0:
.string "%s"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movq %fs:40, %rax
movq %rax, -8(%rbp)
xorl %eax, %eax
movl $1668178254, -14(%rbp) # NOTE THIS PART HERE
movw $121, -10(%rbp) # AND HERE
leaq -14(%rbp), %rax
movq %rax, %rsi
leaq .LC0(%rip), %rdi
movl $0, %eax
call printf@PLT
movl $0, %eax
movq -8(%rbp), %rdx
xorq %fs:40, %rdx
je .L3
call __stack_chk_fail@PLT
.L3:
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:
突出显示的值1668178254是十六进制636E614E或“cnaN”(由于x86是一个小的端位系统,因此在ASCII编码中变成“Nanc”),而121是十六进制79,或“y”。
因此,它使用两条移动指令,而不是从文件的字节字符串部分复制一个循环,因为它是一个短字符串,中间的“垃圾”是(我相信)以下movw指令。这可能是一种优化初始化的方法,而不是通过内存逐字节循环,即使没有“正式”给编译器提供优化标志——这就是问题所在,编译器可以在这方面做它想做的事情。因此,微软的编译器在编译方式上似乎更“迂腐”,因为事实上,它显然放弃了这种优化,转而将字符串连续组合在一起。

关于编译器如何在其生成的输出文件中存储数据,没有单一的规则。
数据可以存储在“常量”部分。
数据可以被构建到指令的“直接”操作数中,其中数据被编码在编码指令的位的各个字段中。
数据可以通过编译器生成的指令从其他数据中计算出来。
我怀疑您在一个地方看到“Nanc”,在另一个地方看到“y”的情况是编译器使用加载指令(可以用“mov”编写)加载形成“Nanc”的字节作为直接操作数,另一个加载指令加载形成“y”的字节,并带有尾随的空字符,以及其他将加载的数据存储在堆栈上并将其地址传递给printf的指令。
您没有提供足够的信息来诊断g大小写:您没有命名编译器或其版本号,也没有提供生成输出的任何部分。
-
问题内容: 我们正在捕获大小可变(从100k到800k)的原始二进制字符串,并且我们想存储这些单独的字符串。它们不需要索引(duh),并且不会对该字段的内容进行任何查询。 这些插件的数量将非常大(用于存档),例如每天10,000。像这样的大型二进制字符串的最佳字段类型是什么?应该是还是其他? 问题答案: 就 PostgreSQL 而言,类型是不可能的。与目标相比,它更慢,占用更多空间并且更容易出错
-
问题内容: 程序从经过排序的字符串的txt文件中读取,并使用顺序的,迭代的二进制和递归的二进制存储在数组中,然后在数组中搜索位置以及查找该单词所需的迭代次数。当我尝试将数组中的单词与用户输入的单词进行比较时出现错误。不知道为什么。2)希望有人可以解释迭代二进制和递归二进制之间的区别。3)为什么需要这样做… SearchString si = new SearchString(); 程序在下面… }
-
问题内容: 这一定很明显,但我无法弄清楚。我为此花了将近一整天。我很乐意给减轻我体重的人买啤酒。 这是我的代码。我看到字节数组大小不合适,但是我找不到正确的大小。除此之外,内容也不是不正确的。似乎只有文字字符可以。 似乎从二进制文件中删除数据确实很痛苦,我真的很沮丧。 还有一件事:文件内容不是文本,可以是图片,视频或pdf之类的东西。 问题答案: 如果你正在读一个二进制文件,你应该 不 尝试把它当
-
我有一个通过ORM保存到数据库的对象。对象有一个字符串数组,每个对象的数组长度可以不同。我想知道在db中存储字符串数组的标准做法(例如,我是否应该将所有字符串存储在一个字段中作为csv等)?
-
问题内容: 我正在使用使用Strings的二维数组的程序(一开始可能不是很聪明,但是eh),并且我想编写一个采用这些数组之一的函数(比方说array1),一个独立的副本,并返回它(假设为array2)。但是,当我然后更改array2中的值时,它似乎反映在array1中。 我的函数当前看起来像这样: 我声明一个新的字符串数组,然后对其进行迭代,分别复制每个值。当这不起作用时,我什至尝试从每个旧字符串
-
在“基本类型”一章中,介绍了字符串,以及使用is_binary/1函数检查它: iex> string = "hello" "hello" iex> is_binary string true 本章将学习理解:二进制串(binaries)是个啥,它怎么和字符串(strings)扯上关系的; 以及用单引号包裹的值'like this'是啥意思。 UTF-8和Unicode 字符串是UTF-8编码的二